OpenAI Launches GDPval to Measure AI’s Impact on Real-World Work and Productivity
Artificial Intelligence has made remarkable progress in recent years, excelling on academic benchmarks, standardized tests, and synthetic problem sets. Yet, one persistent question remains: how do these models perform when applied to real-world tasks that actually generate economic value? OpenAI’s latest contribution, GDPval, seeks to address this gap. It is a groundbreaking evaluation suite designed to measure AI performance across authentic, occupationally relevant tasks spanning multiple industries.
This article provides an in-depth look at GDPval: its design, methodology, implications, and how it positions itself within the broader landscape of AI evaluation.
What is GDPval?
GDPval (Gross Domestic Product Value Alignment) is a new evaluation suite introduced by OpenAI to measure how AI models perform on economically valuable, real-world tasks across 44 occupations. Unlike academic exams or narrowly defined benchmarks, GDPval focuses on tasks that represent genuine workplace deliverables—the kind of outputs people are paid to produce in industries like law, finance, design, consulting, engineering, and media.
These tasks include:
- Writing briefs, reports, and analyses
- Creating spreadsheets and presentations
- Generating CAD artifacts
- Producing multimedia outputs like audio and video clips
In essence, GDPval evaluates whether AI can actually contribute to the workflows that drive the global economy.
Why GDPval Matters
The importance of GDPval lies in its alignment with economic utility. Existing benchmarks such as MMLU or Big-Bench test knowledge recall, reasoning, or specialized skills. While useful, they don’t capture whether AI can deliver outputs that match professional quality standards in real occupational contexts.
Key differentiators include:
- Economic Relevance
- GDPval is tied to GDP-dominant sectors of the U.S. economy, ensuring evaluations remain connected to where productivity gains matter most.
- Deliverable Realism
- Instead of multiple-choice or text-only outputs, tasks require multi-file, multimodal deliverables (presentations, spreadsheets, documents). This stresses practical usability, formatting, and integration.
- Expert Grading
- Human occupational experts, averaging 14 years of experience, grade AI outputs via blinded pairwise comparisons with human-created references. This ensures that scoring reflects industry expectations, not abstract metrics.
How GDPval is Built
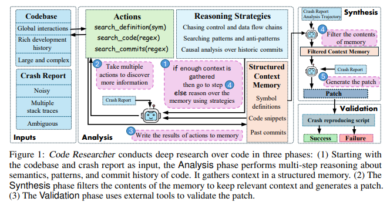
GDPval aggregates 1,320 tasks sourced directly from industry professionals. Each task maps to O*NET work activities (a U.S. Department of Labor framework for occupational functions). The construction process ensures coverage of critical knowledge work spanning nine major sectors of the U.S. economy.


Task Features:
- File-based Inputs/Outputs: Word docs, Excel sheets, PowerPoint slides, CAD files, videos, and images.
- Context-rich Design: Each task may include dozens of supporting reference files.
- Gold Subset: A public set of 220 tasks with prompts and references, enabling transparency and reproducibility for research.
This design ensures GDPval is multi-modal, complex, and context-dependent, pushing models beyond simple Q&A into true work simulation.
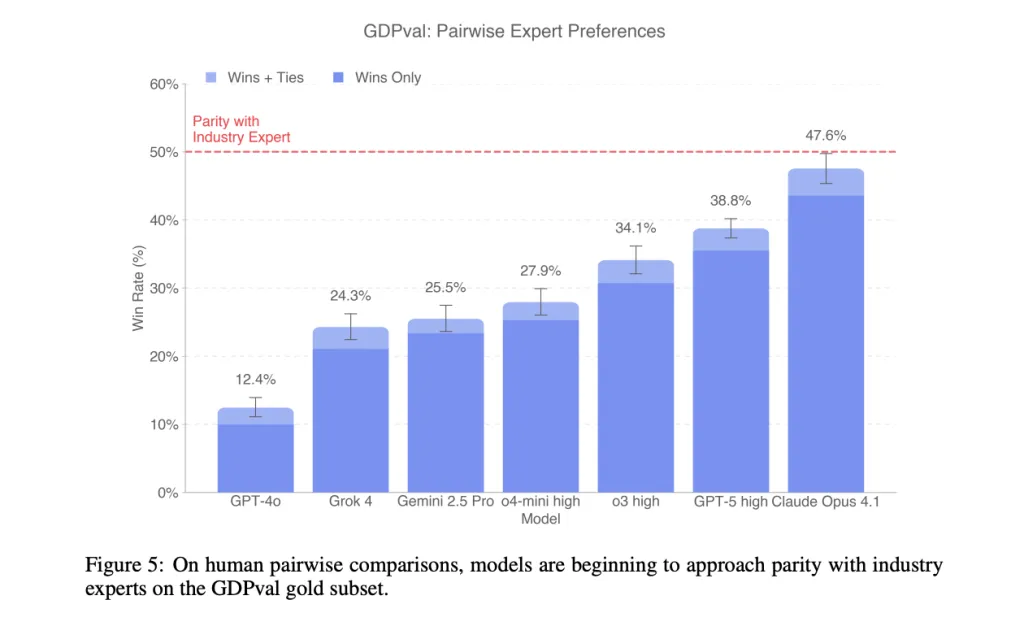
Human vs. Model: What the Data Shows
On the gold subset, cutting-edge AI models show near-parity with expert outputs on a substantial fraction of tasks under blinded expert review.
Key Findings:
- Linear Progression: AI model quality tracks roughly linearly across successive releases, mirroring progress seen on other benchmarks.
- Performance Clusters: Errors often involve formatting, instruction adherence, data use, and hallucinations.
- Scaffolding Helps: Stronger scaffolding (like self-checks, format validation, and artifact rendering) significantly improves performance.
- Human Parity in Contexts: Frontier models can now produce deliverables that match or surpass humans in specific occupational tasks.
This suggests that AI is moving closer to practical economic utility—not just solving puzzles, but generating work that organizations would accept as billable.
Time and Cost Analysis
Beyond accuracy, GDPval uniquely quantifies time and cost implications of using AI.
For each task, scenario analyses estimate:
- Human-only cost: Completion time × wage rates
- Model-assisted workflows: Model output + expert reviewer time
- API latency & cost: Inference expenses factored into the workflow
- Comparative Win/Tie Rates: How often AI outputs meet or exceed human deliverables
Findings indicate that AI-assisted workflows can reduce time and costs for many categories of tasks, especially when review overhead is modest. This makes GDPval not just an accuracy benchmark but a productivity economics tool.
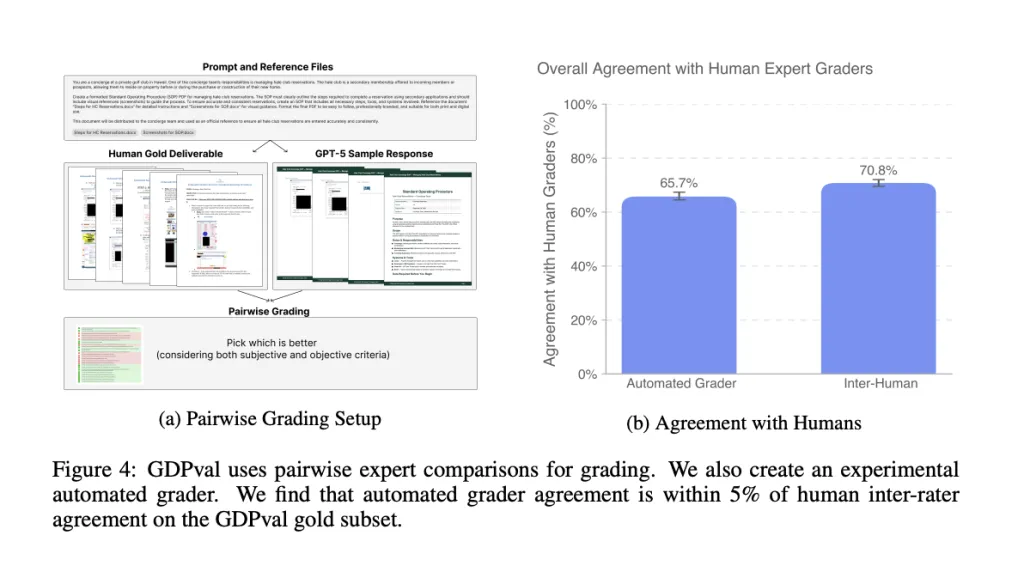
Automated Grading: Proxy vs. Oracle
To make evaluation scalable, OpenAI also introduced an automated pairwise grader hosted at evals.openai.com.
- 66% agreement with expert reviewers on the gold subset.
- Close to human-human agreement (~71%).
- Best used as a proxy for iteration, not a full replacement for expert grading.
This hybrid approach balances rigor with accessibility, making GDPval a tool researchers and developers can realistically use.
Where GDPval Fits in the AI Evaluation Stack
GDPval complements existing benchmarks by adding breadth and realism:
- Compared to MMLU/ARC: Broader occupational scope vs. narrow reasoning/knowledge checks.
- Compared to HELM/Evals: Focused on deliverables and economic value, not just prompts.
- Compared to Academic Exams: Measures authentic productivity rather than standardized test performance.
OpenAI positions GDPval as a living benchmark, with versioned releases (starting from v0) and plans to broaden both occupational coverage and task realism over time.
Limitations and Boundary Conditions
While ambitious, GDPval has defined boundaries:
- Scope: Limited to computer-mediated knowledge work. Manual labor, multi-turn collaboration, and organization-specific workflows are excluded.
- Task Type: One-shot, precisely specified tasks—real-world work is often iterative and interactive.
- Resource-Intensive: Task creation and grading are costly, motivating reliance on the automated grader.
- Performance Drops Without Context: Ablation studies show that reducing task context significantly worsens model outcomes.
These limitations highlight GDPval’s role as a first step toward capturing real-world economic utility, rather than the final word.
Why GDPval is a Game-Changer
1. Economic Benchmarking
It shifts the evaluation paradigm from academic difficulty to economic relevance, grounding AI progress in real productivity.
2. Holistic Assessment
By including multimodal, file-based tasks, GDPval tests everything from formatting discipline to artifact realism.
3. Human-Centric Judging
Outputs are graded by industry experts, ensuring alignment with professional quality standards.
4. Productivity Insights
Time–cost analyses show how AI can integrate into workflows, not just whether it can solve problems.
5. Scalable Evaluation
Automated graders balance cost with accessibility, enabling ongoing monitoring of AI progress.
Implications for the Future of Work
The launch of GDPval has deep implications:
- For Enterprises: It provides a framework to evaluate AI adoption, helping firms decide where to deploy models to cut costs and increase output quality.
- For Researchers: It establishes a rigorous, reproducible benchmark that expands beyond academic tasks.
- For Policymakers: It contextualizes AI’s impact in terms of GDP-relevant occupations, tying evaluation directly to economic productivity.
- For AI Developers: It highlights failure modes—like hallucinations, poor formatting, or weak reasoning—that must be overcome for reliable deployment.
Ultimately, GDPval aligns AI evaluation with the language of economics and work, bringing us closer to understanding AI’s role in reshaping industries.
Conclusion
OpenAI’s GDPval represents a pivotal evolution in AI benchmarking. By anchoring evaluation to economically valuable, real-world tasks, it moves beyond academic exercises to measure AI’s actual capacity to transform productivity.
Through its occupational breadth, expert-based grading, multimodal deliverables, and cost–time analyses, GDPval provides a holistic picture of AI utility. While still limited to computer-mediated, one-shot tasks, it lays the foundation for more expansive and dynamic evaluations in the future.
As AI systems increasingly step into the workflows of professionals across sectors, GDPval offers both a mirror of current capabilities and a roadmap for progress. It ensures that the question is no longer just “How smart are these models?” but rather “How much real-world economic value can they create?”
Check out the Paper, Technical details, and Dataset on Hugging Face. All credit for this research goes to the researchers of this project. Explore one of the largest MCP directories created by AI Toolhouse containing over 4500+ MCP Servers: AI Toolhouse MCP Servers Directory