How Prometheus-Eval and Prometheus 2 Transform LLM Performance Metrics
In the rapidly evolving field of Natural Language Processing (NLP), evaluating language models is crucial to ensure their effectiveness in tasks such as text generation, translation, and sentiment analysis. To meet this demand for better evaluation tools, Prometheus-Eval and Prometheus 2 have emerged as groundbreaking solutions. These open-source projects have set new standards in LLM (Language Model) evaluation and open-source innovation, providing researchers with state-of-the-art evaluator language models.
Introducing Prometheus-Eval: A Robust Framework for LLM Evaluation
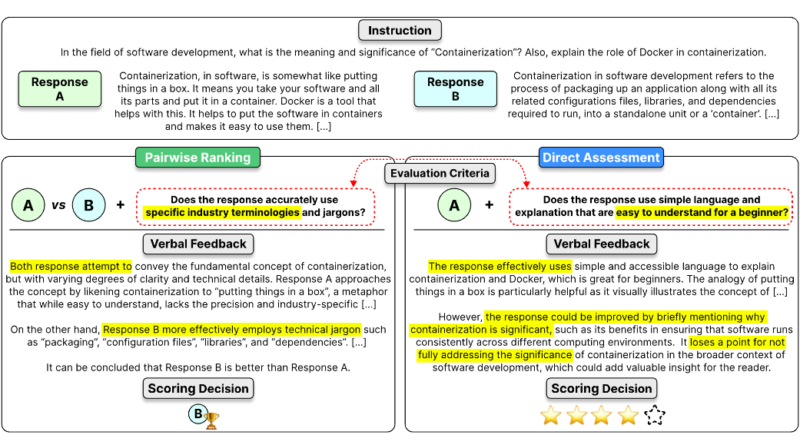
Prometheus-Eval is a powerful repository that offers a comprehensive set of tools for training, evaluating, and using language models specialized in evaluating other language models. With its Python package, Prometheus-eval, it provides a user-friendly interface for evaluating instruction-response pairs. This package supports both absolute and relative grading methods, facilitating thorough evaluations.
The absolute grading method in Prometheus-Eval produces a score between 1 and 5, allowing researchers to quantitatively assess the performance of language models. On the other hand, the relative grading method compares responses and determines the better one, providing valuable insights into model comparisons. These evaluation capabilities enable researchers to gain a deeper understanding of their language models’ strengths and weaknesses.
Moreover, Prometheus-Eval includes evaluation datasets and scripts that facilitate training or fine-tuning Prometheus models on custom datasets. This flexibility allows researchers to adapt the models to their specific needs and evaluate them more comprehensively.
One of the key features of Prometheus-Eval lies in its ability to simulate human judgments and conduct proprietary LM-based evaluations. By providing a transparent and robust evaluation framework, Prometheus-Eval ensures fairness and accessibility in language model assessment. It eliminates the need for reliance on closed-source models, empowering researchers to construct their own evaluation pipelines without concerns about GPT version updates.
Notably, Prometheus-Eval is designed to be accessible to a wide range of users, requiring only consumer-grade GPUs for operation. This accessibility democratizes the use of advanced evaluation capabilities, allowing more researchers to benefit from the power of Prometheus-Eval.
Prometheus 2: Revolutionizing LLM Evaluation with Advanced Capabilities
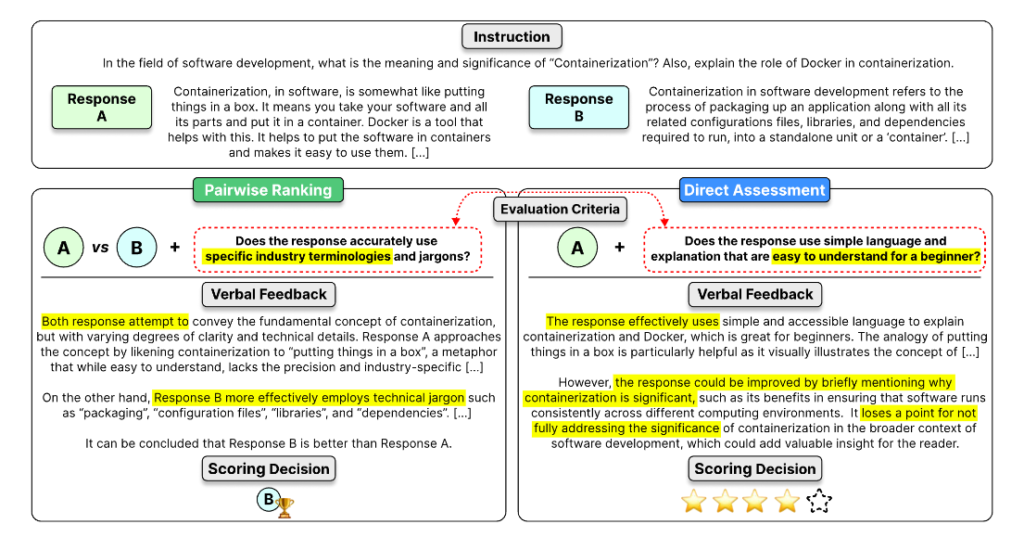
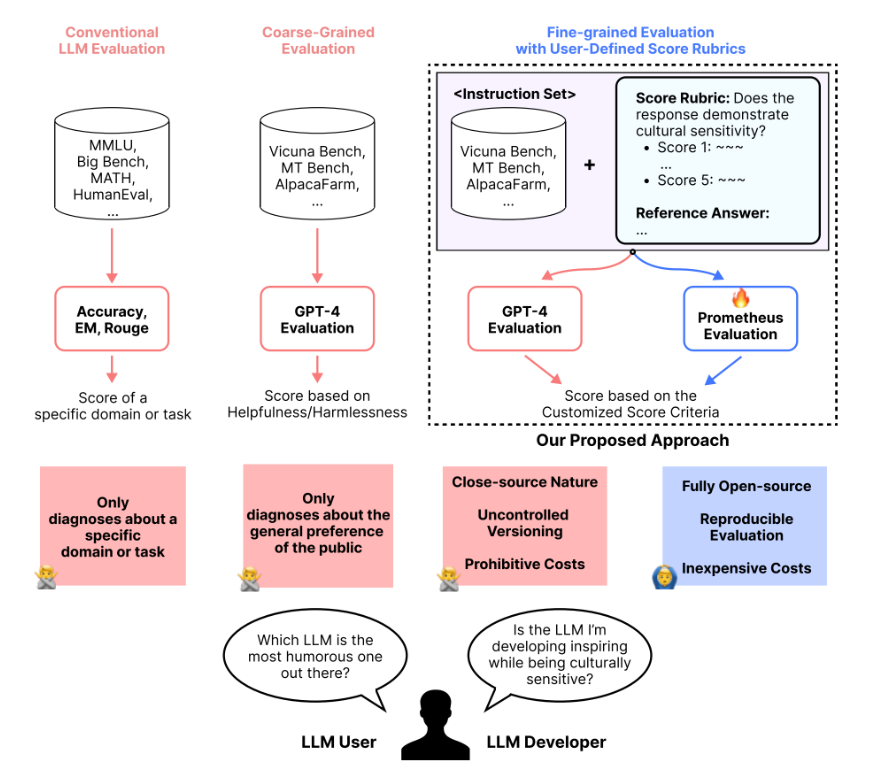
Building upon the success of Prometheus-Eval, a group of researchers from KAIST AI, LG AI Research, Carnegie Mellon University, MIT, Allen Institute for AI, and the University of Illinois Chicago have introduced Prometheus 2, the state-of-the-art evaluator language model. Prometheus 2 takes LLM evaluation to new heights with its advanced capabilities and remarkable performance metrics .
Prometheus 2 (8x7B) supports both direct assessment (absolute grading) and pairwise ranking (relative grading) formats, offering flexibility and accuracy in evaluations. It demonstrates a Pearson correlation of 0.6 to 0.7 with GPT-4-1106 on a 5-point Likert scale across various direct assessment benchmarks, including VicunaBench, MT-Bench, and FLASK. These results highlight the high accuracy and consistency of Prometheus 2 in evaluating language models.
Additionally, Prometheus 2 achieves a remarkable agreement of 72% to 85% with human judgments on multiple pairwise ranking benchmarks, such as HHH Alignment, MT Bench Human Judgment, and Auto-J Eval. Such agreements confirm the model’s reliability and its ability to align with human evaluation standards.
Prometheus 2 (8x7B) is designed to be accessible and efficient, requiring only 16 GB of VRAM. This makes it suitable for running on consumer-grade GPUs, expanding its usability to a wider audience of researchers. Furthermore, Prometheus 2 offers a lighter version, Prometheus 2 (7B), which achieves at least 80% of the larger model’s evaluation statistics or performances while being more efficient in terms of resource usage. It outperforms models such as Llama-2-70B and is on par with Mixtral-8x7B, making it an excellent choice for researchers with varying computational resources.
Leveraging Prometheus-Eval and Prometheus 2 for Comprehensive Evaluations
The Prometheus-Eval package provides a straightforward interface for evaluating instruction-response pairs using Prometheus 2. Researchers can easily switch between absolute and relative grading modes by providing different input prompt formats and system prompts. This versatility allows for the integration of various datasets, ensuring comprehensive and detailed evaluations of language models.
Furthermore, the batch grading feature supported by Prometheus-Eval enables researchers to evaluate multiple responses efficiently. This feature provides a significant speedup for large-scale evaluations, streamlining the evaluation process and allowing researchers to analyze and compare language models more effectively.
In conclusion, Prometheus-Eval and Prometheus 2 have revolutionized the field of LLM evaluation and open-source innovation. Prometheus-Eval offers a robust framework for evaluating language models, ensuring fairness and accessibility. Prometheus 2, the state-of-the-art evaluator language model, provides advanced evaluation capabilities with impressive performance metrics. Researchers can now assess their language models more confidently, armed with comprehensive and accessible tools.
FAQs
1. How to evaluate LLM model performance?
A Large Language Model (LLM)’s performance is evaluated in a series of steps. Initially, it is imperative to establish specific targets for the tasks performed by the model, including sentiment analysis, translation, and text generation. Testing should be conducted using representative datasets that appropriately reflect the model’s application domain.
Using a range of measures allows a thorough evaluation of the model’s capabilities. Perplexity is a metric that measures how well the model predicts a sample, whereas BLEU and ROUGE scores compare the quality of text output to that of reference texts.
Exact Match and Mean Reciprocal Rank are measures used to measure the accuracy of LLM outputs. Exact Match determines the fraction of responses that exactly match the ground truth, whereas Mean Reciprocal Rank measures the model’s ability to rank accurate answers highly.
A thorough error analysis identifies typical faults and possibilities for improvement. Furthermore, real-world testing in practical applications assures that the model is reliable and relevant.
2. What are the metrics for LLM answer evaluation?
Evaluating Large Language Model (LLM) answers requires a variety of measures customised to certain features of model performance. Perplexity, BLEU, ROUGE, and METEOR are common metrics used to measure the quality of text production. Perplexity is a measure of how effectively a probability distribution predicts a sample, which indicates the model’s knowledge of language. BLEU, ROUGE, and METEOR compare generated text to reference texts to assess the correctness and fluency of the results.
Furthermore, for dialogue systems, measures such as F1 score, Exact Match, and Mean Reciprocal Rank are employed to assess response relevance and correctness. The F1 score balances precision and memory, Exact Match calculates the percentage of responses that exactly match the ground truth, and Mean Reciprocal Rank evaluates the model’s ability to rank correct answers highly. These measures provide a complete framework for evaluating LLM performance, ensuring that models satisfy the required standards in real implementations.
3. How to measure accuracy of LLM output?
Human evaluators manually assess LLM outputs by comparing them to the preset ground truth or ideal response, providing a yes-or-no judgment on accuracy. This method relies heavily on the quality of the ground truths. Scoring involves assigning a numerical value to the output based on predefined criteria, and A/B testing compares pairs of outputs to determine the better one. This process ensures that the outputs align with the desired quality and accuracy standards, reflecting the model’s true performance .
Don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.Explore 3600+ latest AI tools at AI Toolhouse 🚀.If you like our work, you will love our Newsletter 📰