COCOM: How Context Embeddings in RAG Supercharge Answer Generation Efficiency
Understanding RAG: Enhancing LLMs with External Knowledge
Retrieval-Augmented Generation (RAG) significantly improves the performance of Large Language Models (LLMs) by extending their inputs with external information. This integration is crucial for knowledge-intensive tasks where relying solely on the pre-trained data of LLMs falls short. However, this enhancement comes with a challenge: longer contextual inputs slow down the decoding time, leading to delays in generating answers.
The Decoding Dilemma: Long Contexts Slow Down LLMs
When LLMs receive extended contextual inputs, their self-attention mechanism requires more space and memory, increasing the decoding time. This delay can be problematic, particularly in applications demanding quick and accurate responses, such as customer support, research assistance, and interactive AI systems.
COCOM: The Breakthrough in Context Compression
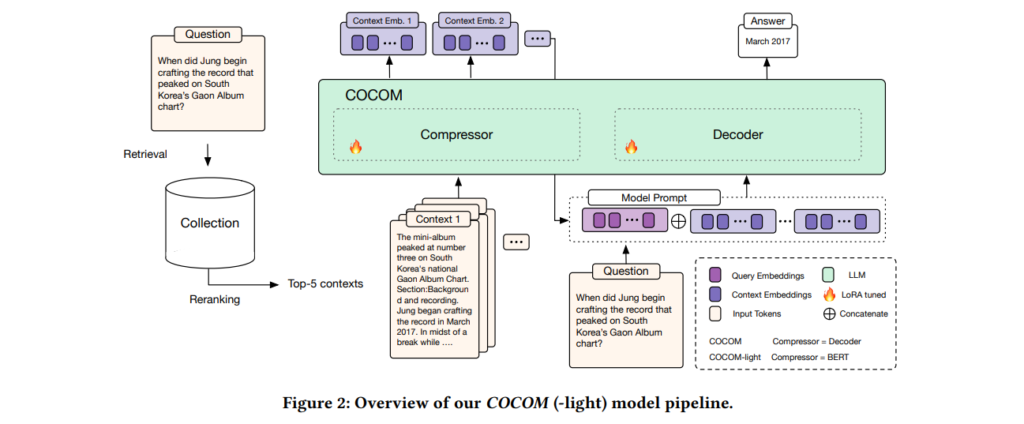
To address this issue, researchers have developed COCOM (Context Compression Model). COCOM reduces the length of contextual inputs by compressing them into a few context embeddings. This innovative approach accelerates the generation process without compromising the quality of the answers.
Advantages of COCOM: Speed and Performance
- Enhanced Efficiency: By compressing long contexts into a smaller set of context embeddings, COCOM significantly reduces decoding time, making the model much faster.
- Flexibility in Compression Rates: COCOM offers various compression rates, allowing users to balance between decoding time and answer quality based on their specific needs.
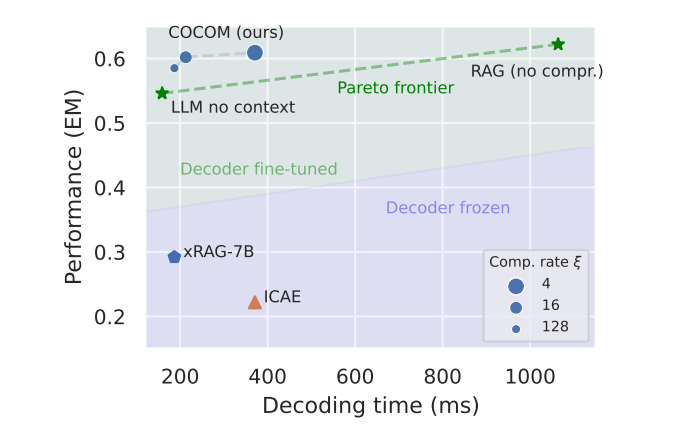
- Superior Performance: Unlike other methods, COCOM effectively handles multiple contexts, achieving a speed-up of up to 5.69 times while maintaining high performance.
The Mechanics of COCOM
COCOM employs a unified model for both context compression and answer generation. Here’s a detailed breakdown of its process:
- Context Compression: The model compresses long contexts into a few context embeddings, significantly reducing the input size.
- Pre-Training: The model undergoes rigorous pre-training to master the compression and decompression of inputs.
- Fine-Tuning: The model is fine-tuned on various QA datasets, enhancing its capability to generate accurate and relevant answers.
Empirical Results: Efficiency and Effectiveness
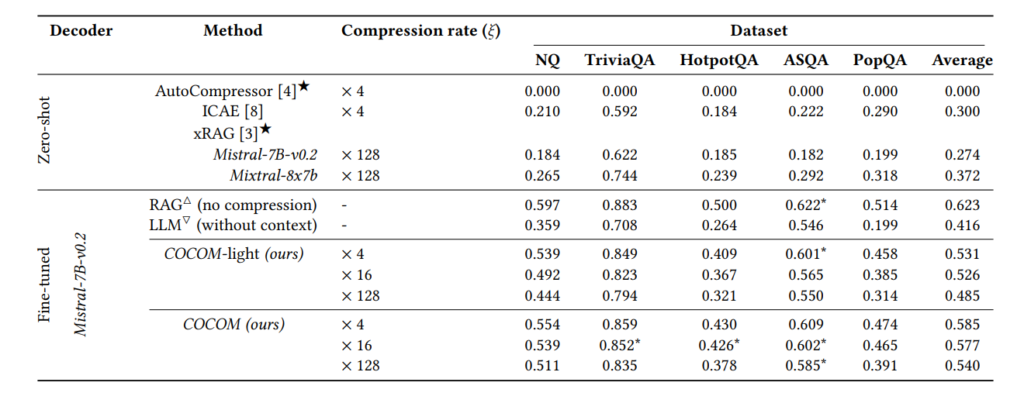
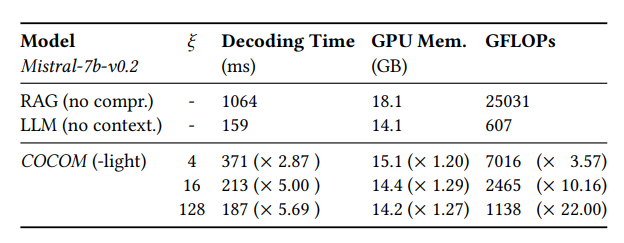
COCOM demonstrates impressive results in both efficiency and performance:
- Decoding Time: The model reduces decoding time by up to 5.69 times compared to uncompressed models.
- GPU Memory and Operations: It uses less GPU memory and fewer operations (GFLOPs), making it more resource-efficient.
Handling Multiple Contexts: A Key Strength
COCOM excels in scenarios where multiple retrieved contexts are necessary for answer generation. This capability is particularly beneficial for tasks requiring reasoning over several documents. By compressing multiple contexts into manageable embeddings, COCOM enhances the model’s ability to generate accurate answers quickly.
Detailed Comparison with Other Methods
COCOM outperforms existing context compression methods by:
- Using a Single Model: Both for compression and answer generation, streamlining the process.
- Maintaining High Performance: Even at higher compression rates, COCOM shows superior performance metrics.
- Providing Flexibility: Users can choose different compression rates, optimizing for either speed or quality as needed.
Conclusion
COCOM represents a significant advancement in the efficiency of Retrieval-Augmented Generation models. By effectively compressing contexts, it ensures faster and more accurate answer generation, making it invaluable for applications demanding quick responses. This breakthrough paves the way for more efficient AI-driven solutions across various fields.
Got an incredible AI tool or app? Let’s make it shine! Contact us now to get featured and reach a wider audience.
Explore 3600+ latest AI tools at AI Toolhouse 🚀. Don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Read our other blogs on AI Tools 😁
If you like our work, you will love our Newsletter 📰