NVIDIA AI Research Proposes LITA: Enhancing Temporal Localization Using Video LLMs
Large Language Models (LLMs) have been revolutionizing various natural language processing tasks, demonstrating impressive instruction-following capabilities. These models have the potential to serve as a universal interface for tasks such as text generation and language translation. However, when it comes to processing videos, existing Video LLMs face challenges in accurately localizing temporal information. NVIDIA AI Research has proposed a solution to this problem with their Language Instructed Temporal-Localization Assistant (LITA).
The Limitations of Existing Video LLMs
Existing Video LLMs have shown promising abilities in answering questions about videos, but they struggle with accurately localizing periods of time. When prompted with questions like “When did this event happen?” or “What time does this action occur?”, these models often hallucinate irrelevant or incorrect information. Several factors contribute to these limitations:
1. Time Representation
Existing models represent timestamps as plain text, such as “01:22” or “142sec.” However, without access to the frame rate, the correct timestamp is still ambiguous. This lack of precise time representation hinders the learning of temporal localization.
2. Architecture
The architecture of existing Video LLMs requires more temporal resolution to accurately interpolate time information. For example, models like Video-LLaMA only sample a small number of frames from an entire video, leading to a loss of temporal details. This limitation needs to be addressed for accurate temporal localization.
3. Data
Temporal localization is often ignored in the data used to train Video LLMs. While some video datasets provide timestamps, they only constitute a small subset of the training data, and the accuracy of these timestamps is not always verified. This lack of emphasis on temporal localization data affects the models’ ability to understand and answer questions about time-related events in videos.
Introducing LITA: Enhanced Temporal Localization
NVIDIA AI Research proposes the Language Instructed Temporal-Localization Assistant (LITA) to address the limitations mentioned above. LITA consists of three key components that enhance the temporal localization capabilities of Video LLMs:
1. Time Representation
LITA introduces time tokens to represent relative timestamps, enabling Video LLMs to communicate about time more effectively than using plain text. By incorporating time tokens into the model architecture, LITA improves the understanding and localization of temporal information in videos.
2. Architecture
To capture temporal information at a fine resolution, LITA introduces SlowFast tokens. This enhancement allows the model to process videos with greater temporal granularity, improving the accuracy of temporal localization. SlowFast tokens address the limitations of existing models that sample frames uniformly from the entire video.
3. Data
NVIDIA AI Research emphasizes the importance of temporal localization data for training LITA. They introduce a new task called Reasoning Temporal Localization (RTL) and develop the ActivityNet-RTL dataset for this purpose. By training LITA on RTL data, the model learns to accurately understand and answer questions related to temporal events in videos.
How LITA Works
LITA is built on the Image LLaVA architecture, chosen for its simplicity and effectiveness. The model doesn’t rely on the underlying Image LLM’s specific architecture and can be easily adapted for other base architecture.
Here’s a high-level overview of how LITA works:
- Given a video, LITA uniformly selects T frames and encodes each frame into M tokens.
- The total number of tokens (T × M) is usually too large to be directly processed by the LLM module. To address this, LITA employs SlowFast pooling to reduce the tokens to T + M, making it more manageable for further processing.
- The text tokens (prompt) are processed to convert referenced timestamps into specialized time tokens.
- All the input tokens, including video and text tokens, are jointly sequentially processed by the LLM module.
- LITA is fine-tuned using RTL data and other video tasks, such as dense video captioning and event localization.
- Through this training process, LITA learns to use time tokens instead of relying solely on absolute timestamps, improving its temporal understanding and localization capabilities.
Evaluating LITA’s Performance
NVIDIA AI Research compared LITA with existing Video LLMs, including LLaMA-Adapter, Video-LLaMA, VideoChat, and Video-ChatGPT. The evaluation metrics focused on the correctness of information and temporal understanding.
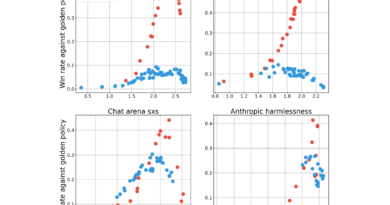
Video-ChatGPT, the best-performing baseline, slightly outperformed other models, including Video-LLaMA-v2. However, LITA significantly outperformed all the baselines in both correctness of information and temporal understanding. LITA achieved a 22% improvement in correctness of information (2.94 vs. 2.40) and a remarkable 36% relative improvement in temporal understanding (2.68 vs. 1.98) 1.
These results demonstrate the effectiveness of LITA in enhancing the temporal localization capabilities of Video LLMs. The emphasis on temporal understanding during training enables LITA to accurately answer questions about temporal events in videos and improve video-based text generation 1.
Conclusion
NVIDIA AI Research’s Language Instructed Temporal-Localization Assistant (LITA) addresses the limitations faced by existing Video LLMs in accurately localizing temporal information. By introducing time tokens, SlowFast tokens, and emphasizing temporal localization data, LITA significantly enhances the representation and understanding of time in videos.
LITA’s breakthrough in temporal localization using Video LLMs opens up new possibilities for applications in video analysis, question-answering systems, and video-based text generation. With LITA’s advanced capabilities, video understanding can reach new heights, enabling more accurate and efficient interaction with large-scale video datasets 1.
As the field of AI continues to evolve, LITA represents a significant step forward in leveraging language models for video analysis. With further advancements and research, we can expect even more sophisticated models that excel in understanding and processing complex multimodal data.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰