NVIDIA Launches Llama Nemotron Nano VL: A Lightweight Vision-Language Model for Advanced Document Understanding
Introduction
As enterprises increasingly digitize document workflows, the need for efficient, intelligent AI systems capable of understanding scanned forms, financial reports, and multi-modal content has never been greater. Addressing this growing demand, NVIDIA has introduced Llama Nemotron Nano VL—a compact yet powerful vision-language model (VLM) optimized for document-level understanding. Built on the Llama 3.1 foundation, this model sets a new benchmark in OCR performance and context-aware document parsing.
What Is Llama Nemotron Nano VL?
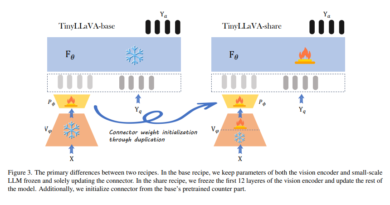
NVIDIA’s Llama Nemotron Nano VL is a vision-language model that integrates Llama 3.1 8B Instruct with a lightweight CRadioV2-H vision encoder. This hybrid architecture is specifically tuned for high-accuracy document intelligence and scalable deployment, even in constrained edge environments.
The model supports a context window of up to 16,000 tokens, allowing it to process long, multi-page documents combining both images and text. Designed to run efficiently with minimal latency, it provides enterprise-ready performance in diverse use cases—from OCR-based automation to complex visual reasoning.
Architecture and Design
The architecture behind Nemotron Nano VL consists of:
- CRadioV2-H Vision Encoder: A compact and efficient visual component that processes scanned images, tables, charts, and diagrams.
- Llama 3.1 8B Language Model: Fine-tuned for instruction following and multi-turn dialogue, adapted here for structured text extraction and question answering.
- Token-Efficient Inference: Custom projection layers and rotary positional encodings enable seamless alignment between image patches and text embeddings.
- Persistent Multi-Modal Memory: Supports long-form reasoning across multiple document pages.
The model is trained using a three-stage curriculum:
- Multimodal Pretraining: Using a diverse corpus of image-text pairs from both image and video datasets.
- Instruction Tuning: Enabling interactive query-based use through prompt conditioning.
- Reblending with Text-Only Instructions: Enhancing generalization across standard NLP tasks and benchmarks.
Training utilized NVIDIA Megatron-LLM, the Energon dataloader, and a cluster of A100 and H100 GPUs for large-scale optimization.
Performance on OCRBench v2
Nemotron Nano VL tops the leaderboard in OCRBench v2, a rigorous benchmark for document VLMs. OCRBench features over 10,000 human-verified question-answer pairs across:
- Financial reports
- Medical records
- Legal documents
- Scientific publications
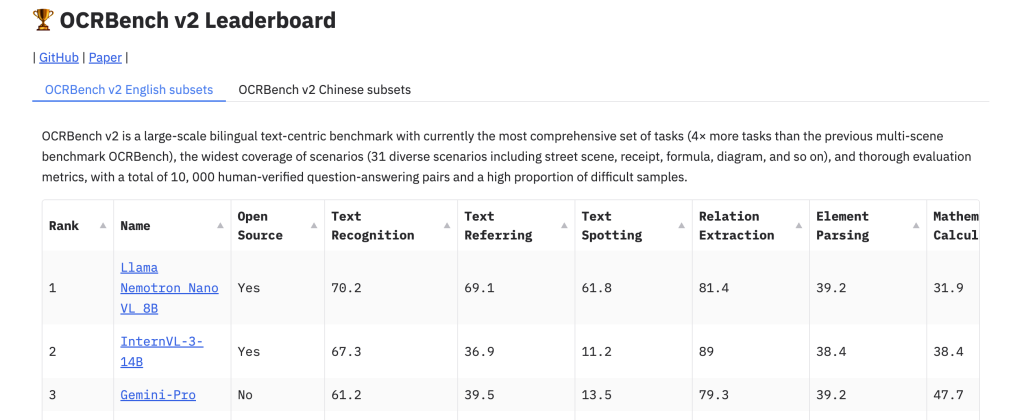


Key Strengths:
- Table Parsing: High precision in identifying rows, headers, and merged cells.
- Key-Value Extraction: Accurate reading of form fields and labels.
- Diagram Reasoning: Robust comprehension of charts, graphs, and visual annotations.
- Multilingual Generalization: Performs well even on non-English content and degraded scans.
These results establish Nemotron Nano VL as the leading compact VLM in the document intelligence category.
Deployment and Inference Efficiency
Designed with developers in mind, Nemotron Nano VL supports:
- Quantized 4-bit Inference: Through AWQ (Activation-aware Weight Quantization), enabling faster inference on constrained hardware.
- NVIDIA TinyChat and TensorRT-LLM: For optimized runtime environments.
- ONNX and TensorRT Export: For seamless hardware acceleration.
- Support for Jetson Orin and Edge AI Devices: Extending deployment beyond cloud servers.
One standout capability is precomputed vision embeddings. For static documents (e.g., legal contracts), the model can skip image processing during runtime, drastically reducing latency.
Integration and Real-World Use Cases
The model fits naturally into AI workflows that require structured document parsing:
- Enterprise Automation: Automating invoice processing, contract review, and compliance.
- Healthcare Informatics: Extracting diagnoses and lab values from scanned charts.
- Financial Services: Parsing earnings reports and tabular balance sheets.
- Education and Research: Summarizing academic papers and annotated figures.
- Public Sector: Processing multilingual forms and administrative documents.
Its architecture also integrates with Model Context Protocol (MCP), enabling agents to access external documents dynamically during query resolution—making it ideal for retrieval-augmented generation (RAG) systems.
Comparison with Other Vision-Language Models
| Model | Params | OCR Accuracy | Context Length | Deployment Efficiency |
|---|---|---|---|---|
| Llama Nemotron Nano VL | 8B | Best-in-Class | 16K | Quantized, Edge Ready |
| Flamingo | 80B | Moderate | 1K | Heavy, Cloud-Only |
| Kosmos-2 | 11B | Good | 4K | Limited Edge Support |
| Bard Gemini-VLM | Unknown | Variable | Unknown | Limited Documentation |
Nemotron Nano VL offers a competitive blend of accuracy, efficiency, and deployment versatility, making it one of the few VLMs viable for production document workflows.
Final Thoughts
With the release of Llama Nemotron Nano VL, NVIDIA advances the state of vision-language intelligence—bringing compact, production-ready multimodal models to the forefront of document automation. For enterprises looking to streamline back-office operations, scale knowledge extraction, or embed AI into edge devices, Nemotron Nano VL delivers high performance without compromising speed or compatibility.
As more organizations seek to integrate document understanding into their AI stacks, models like Nemotron Nano VL will become the foundation for intelligent OCR, smart form processing, and real-time analytics.
Check out the Technical details and Model on Hugging Face. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to subscribe to our Newsletter.