SliCK: A Revolutionary Framework for Mitigating Hallucinations in Language Models
In recent years, large language models (LLMs) have made tremendous strides in understanding and generating human language. These models, such as GPT-3 and BERT, have been deployed in a wide range of applications, from chatbots to language translation. However, as LLMs become more sophisticated, a new challenge arises: the risk of hallucinations.
Hallucinations refer to instances where language models generate responses that are factually incorrect or misleading. For example, if asked about the capital of France, a language model might respond with “Paris is a small village in the countryside.” These hallucinations can have severe consequences in critical applications such as medical diagnosis or legal document analysis.
To address this issue, a team of researchers from Technion – Israel Institute of Technology and Google Research has developed SliCK, a groundbreaking knowledge categorization framework for mitigating hallucinations in language models through structured training 1. SliCK stands for Structured Knowledge Categorization, and it aims to provide a systematic approach to integrating new knowledge into language models while maintaining accuracy and reducing the risk of hallucinations.
The Challenge of Integrating New Knowledge
One of the key challenges in training language models is integrating new knowledge without compromising the integrity of the existing information. Traditional approaches, such as supervised fine-tuning, have shown mixed results. Fine-tuning involves training the language model on specific data that aligns with or extends beyond its pre-training. While popular, this method can lead to overfitting or biases in the model’s responses.
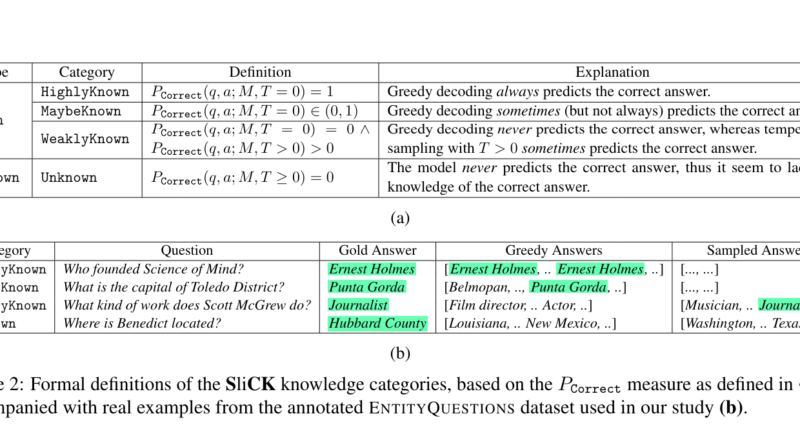
SliCK offers a novel solution to this challenge. It categorizes knowledge into distinct levels, ranging from HighlyKnown to Unknown, providing a granular analysis of how different types of information affect model performance. By categorizing knowledge in this way, SliCK allows for a precise evaluation of the model’s ability to assimilate new facts while maintaining the accuracy of its existing knowledge base.
The SliCK Framework in Action
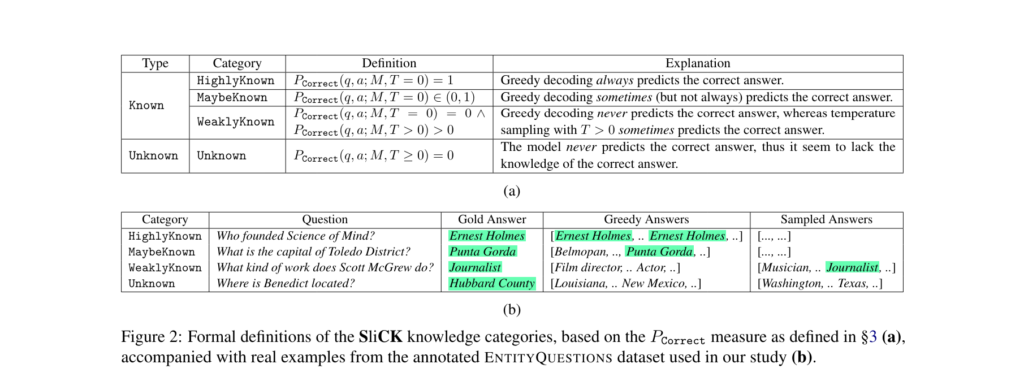
To validate the effectiveness of the SliCK framework, the researchers leveraged the PaLM model, a robust language model developed by Google. They fine-tuned the PaLM model using datasets carefully designed to include varying proportions of knowledge categories: HighlyKnown, MaybeKnown, WeaklyKnown, and Unknown 1. These datasets were derived from a curated subset of factual questions mapped from Wikidata relations, ensuring a controlled examination of the model’s learning dynamics.
The researchers then quantified the model’s performance across these categories using exact match (EM) metrics. This evaluation helped assess how effectively the model integrates new information while avoiding hallucinations. By following this structured approach, the researchers gained valuable insights into the impact of fine-tuning with both familiar and novel data on model accuracy.
The Findings: Balancing Accuracy and Risk
The study’s findings demonstrated the effectiveness of the SliCK categorization in enhancing the fine-tuning process. Models trained using the SliCK framework, particularly with a 50% Known and 50% Unknown mix, achieved a 5% higher accuracy in generating correct responses compared to models trained with predominantly Unknown data 1.
Conversely, when the proportion of Unknown data exceeded 70%, the models’ propensity for hallucinations increased by approximately 12%. This observation highlights the delicate balance required in the fine-tuning process. Too much unfamiliar information can lead to unreliable responses, while too little new knowledge restricts the model’s ability to adapt to novel scenarios.
The SliCK framework acts as a guiding principle for machine learning practitioners, helping them assess and manage the risk of error when integrating new information during the fine-tuning of language models. By employing a structured approach to knowledge categorization, developers can optimize model reliability and performance, reducing the chance of hallucinations and ensuring accurate responses in various language processing applications.
Implications and Future Developments
The research by Technion – Israel Institute of Technology and Google Research sheds light on the importance of strategic data categorization in enhancing the reliability and performance of language models. The SliCK framework offers valuable insights for future developments in machine learning methodologies, providing a blueprint for mitigating hallucinations and maintaining accuracy.
As language models continue to evolve, the challenges of integrating new knowledge will persist. Researchers and developers must remain vigilant to address these challenges and explore innovative approaches to enhance language models’ capabilities. The SliCK framework serves as a promising step in that direction, bridging the gap between accuracy and adaptability in language processing.
In conclusion, the SliCK framework presents a revolutionary approach to mitigating hallucinations in language models. By categorizing knowledge and employing a structured training methodology, developers can ensure accurate responses while integrating new information. As the field of natural language processing progresses, frameworks like SliCK will play a crucial role in advancing the reliability and performance of language models, paving the way for more sophisticated and dependable AI systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
Read our other blogs on AI Tools 😁
If you like our work, you will love our Newsletter 📰