Unleashing the Power of LLaVA-OneVision: A Game-Changer in Visual Task Transfer
In the rapidly evolving field of Artificial Intelligence (AI), the pursuit of building general-purpose assistants has been a core aspiration. The development of Large Multimodal Models (LMMs) has significantly advanced this quest. Among the latest innovations is LLaVA-OneVision, an open large multimodal model that pushes the boundaries of performance in various computer vision scenarios, including single-image, multi-image, and video tasks. This blog delves into the groundbreaking capabilities of LLaVA-OneVision, exploring how it transforms visual task transfer across different modalities.
What is LLaVA-OneVision?
LLaVA-OneVision is a family of open large multimodal models developed by integrating advanced insights into data, models, and visual representations. This model continues the legacy of the LLaVA (Large Vision-and-Language Assistant) series, renowned for its ability to handle diverse computer vision tasks efficiently. By connecting vision encoders with large language models (LLMs) using a simple connection module, LLaVA-OneVision demonstrates unparalleled capabilities in visual task transfer.
Key Capabilities of LLaVA-OneVision
1. State-of-the-Art Performance Across Modalities LLaVA-OneVision excels in three critical computer vision scenarios: single-image, multi-image, and video. This model is the first to achieve state-of-the-art performance across these diverse tasks, making it a versatile tool for various applications. Whether it’s understanding a single image, analyzing multiple images, or interpreting video sequences, LLaVA-OneVision handles each task with exceptional precision.
2. Task Transfer Capabilities One of the standout features of LLaVA-OneVision is its ability to transfer learning across different modalities. For instance, the model can leverage its understanding of images to improve its performance on video tasks. This cross-scenario task transfer opens up new possibilities for AI applications, enabling more efficient and accurate processing of visual data across different contexts.
3. Open-Source and Accessible LLaVA-OneVision is an open model, meaning that its resources, including multimodal instruction data, codebase, model checkpoints, and visual chat demos, are available to the public. This transparency fosters collaboration and innovation, allowing researchers and developers to build upon its capabilities and contribute to the advancement of AI.
The Technology Behind LLaVA-OneVision
1. Minimalist Network Architecture
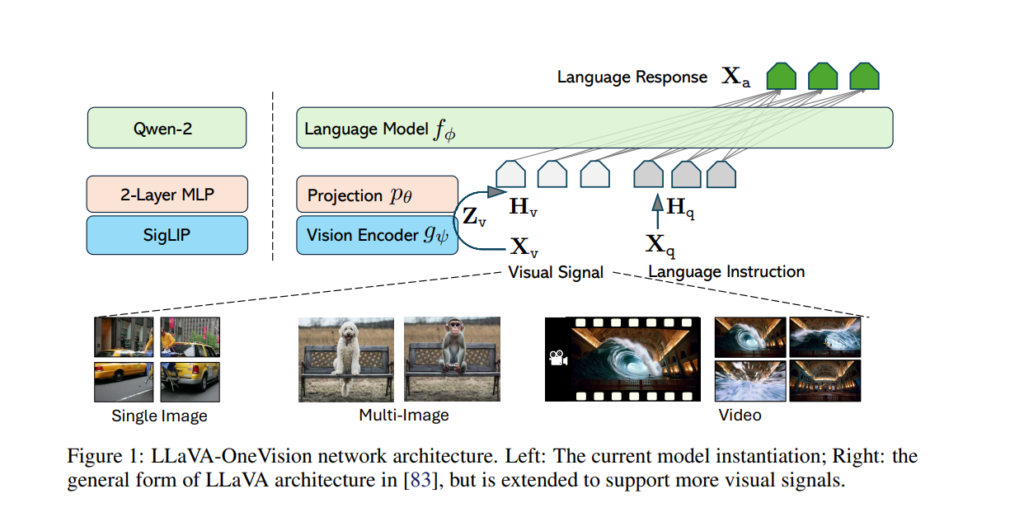
The architecture of LLaVA-OneVision is designed with minimalism in mind, focusing on maximizing the pre-trained capabilities of both the LLM and visual model. This approach not only enhances performance but also ensures scalability, making the model adaptable to future advancements in AI.
2. High-Quality Data and Training
LLaVA-OneVision’s success is partly due to its reliance on high-quality training data. The model is trained using a combination of detailed caption data, document/OCR data, and diverse instruction tuning data. By prioritizing quality over quantity, LLaVA-OneVision achieves superior performance without the need for excessive computational resources.
3. Visual Representations
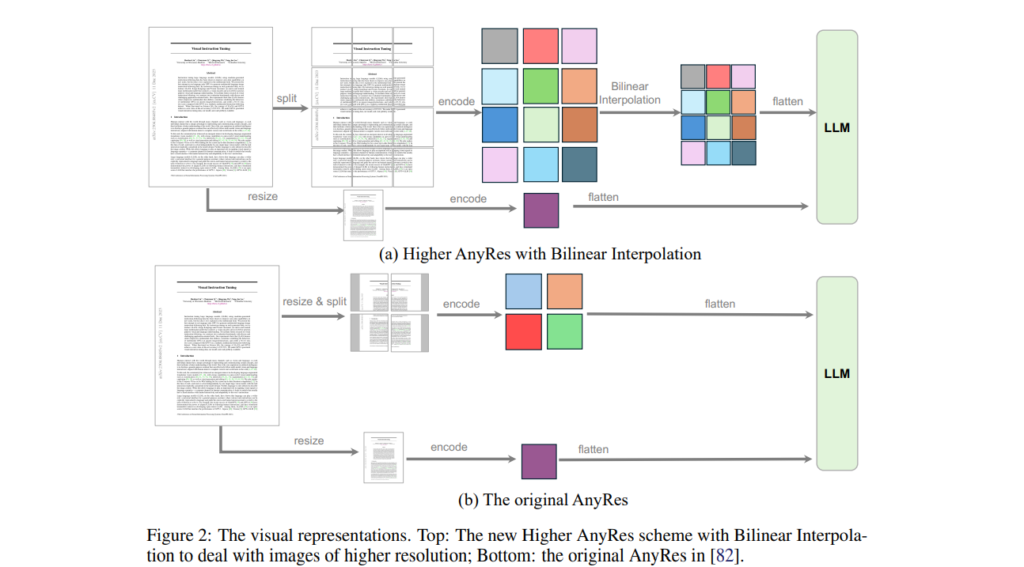
The model employs an innovative visual representation strategy known as Higher AnyRes, which adapts to different resolutions and token numbers to optimize performance. This flexibility allows LLaVA-OneVision to handle various visual inputs, from high-resolution images to complex video sequences, with ease.
Applications and Future Prospects
LLaVA-OneVision’s versatility makes it suitable for a wide range of applications, including:
- Medical Imaging: Enhancing diagnostic accuracy by analyzing medical images and videos.
- Autonomous Vehicles: Improving object detection and scene understanding in real-time driving scenarios.
- Content Moderation: Automatically identifying and moderating inappropriate content in images and videos.
As AI continues to evolve, LLaVA-OneVision is poised to play a crucial role in shaping the future of visual task transfer. Its ability to learn from different modalities and apply this knowledge across various scenarios marks a significant step forward in the development of general-purpose AI assistants.
Conclusion
LLaVA-OneVision represents a major leap in the field of multimodal AI. By combining state-of-the-art performance with innovative task transfer capabilities, it sets a new standard for what large multimodal models can achieve. As the AI community continues to explore and expand upon its potential, LLaVA-OneVision will undoubtedly remain at the forefront of visual task transfer, driving innovation and opening up new possibilities in AI.
Got an incredible AI tool or app? Let’s make it shine! Contact us now to get featured and reach a wider audience.
Explore 3600+ latest AI tools at AI Toolhouse 🚀. Don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Read our other blogs on AI Tools 😁
If you like our work, you will love our Newsletter 📰

Simply wish to say your article is as amazing The clearness in your post is just nice and i could assume youre an expert on this subject Well with your permission let me to grab your feed to keep updated with forthcoming post Thanks a million and please carry on the gratifying work
Loving the information on this site, you have done great job on the content.