OpenAI Unveils GPT-OSS-120B and GPT-OSS-20B: The Most Powerful Open-Weight Language Models Ever Released
Introduction
OpenAI has just redrawn the boundaries of what’s possible in open-weight AI. On August 5, 2025, the company released gpt-oss-120B and gpt-oss-20B, two open-weight large language models (LLMs) that bring state-of-the-art reasoning, tool use, and performance to developers, researchers, and enterprises—without the need for proprietary APIs or cloud access.
This isn’t just another model release. It marks a pivotal moment in the evolution of artificial intelligence—where openness, scalability, and real-world usability collide.
From local deployment to enterprise integration, these models are built to empower. The gpt-oss-120B model delivers near-parity with OpenAI’s commercial o4-mini, while the lighter gpt-oss-20B is optimized for devices as small as a smartphone. Both models are available under the permissive Apache 2.0 license, unleashing new possibilities for private AI, edge deployment, academic research, and custom fine-tuning.
Let’s dive deep into the technology, benchmarks, architecture, and real-world use cases of GPT-OSS—and explore why this is being hailed as a historic release in the world of open-source AI.
1. Why GPT-OSS is a Milestone in Open AI
OpenAI, once known for maintaining strict control over its model weights, has now taken a radical turn. With GPT-OSS, the company is not only releasing open weights—it’s doing so at scale and with performance that rivals proprietary LLMs.
Key reasons this release is game-changing:
- Open weights under Apache 2.0 license: Full commercial use is now possible, no strings attached.
- Unmatched deployment flexibility: From phones to high-end GPUs.
- State-of-the-art reasoning: Chain-of-thought, agentic behavior, API calling, and code execution.
- No reliance on cloud APIs: Complete freedom from rate limits, latency issues, and data privacy concerns.
- Multi-device compatibility: Efficient deployment across desktops, laptops, edge devices, and mobile hardware.
This positions GPT-OSS as a foundational tool for AI democratization, enterprise autonomy, and next-gen research.
2. GPT-OSS Model Comparison: 120B vs 20B
| Feature | gpt-oss-120B | gpt-oss-20B |
|---|---|---|
| Parameters | 117 billion total, 5.1B active per token (MoE) | 21 billion total, 3.6B active per token (MoE) |
| Performance Benchmark | Near OpenAI o4-mini | Between o3-mini and o4-mini |
| Context Length | 128,000 tokens | 128,000 tokens |
| Inference Hardware | Single high-end GPU (H100, A100 80GB, etc.) | Laptop or mobile device (16GB RAM or less) |
| Target Use | Research, enterprise, local deployment | Mobile, edge AI, on-device assistants |
| Licensing | Apache 2.0 (open, commercial) | Apache 2.0 (open, commercial) |
| Quantization | MXFP4 | MXFP4 |
| Architecture | Mixture-of-Experts (8 experts, 2 active per token) | Mixture-of-Experts (same) |
| Reasoning Features | Tool use, API calling, chain-of-thought, code exec | Same |
3. Technical Architecture: Mixture-of-Experts + MXFP4 Quantization
Both GPT-OSS models employ Mixture-of-Experts (MoE)—an architecture where only a fraction of the total parameters (2 out of 8 experts) are activated per token. This results in:
- Massive parameter counts without excessive memory usage
- Reduced compute requirements
- Fast inference speed
Additionally, OpenAI uses MXFP4 quantization, a cutting-edge technique for reducing memory footprint while preserving accuracy. MXFP4 outperforms older FP16 or INT8 schemes by achieving near-full precision at significantly lower bitwidths.


This combo allows gpt-oss-120B to run on a single 80GB GPU, while gpt-oss-20B fits on laptops and even smartphones—a feat previously unimaginable for models of this caliber.
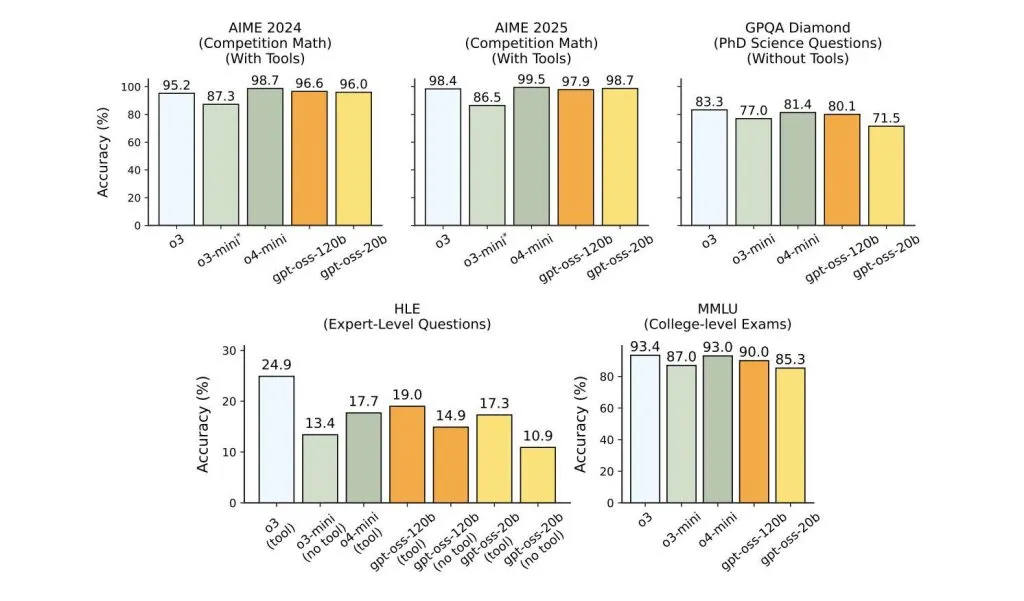
4. Performance Benchmarks: How Does GPT-OSS Compare?
According to internal and third-party benchmarks:
- GPT-OSS-120B achieves parity with OpenAI’s o4-mini, a powerful proprietary reasoning model known for its performance in chain-of-thought tasks, coding, and structured generation.
- GPT-OSS-20B outperforms open-weight competitors like LLaMA-2-13B, Mistral 7B, and Falcon 180B when scaled appropriately.
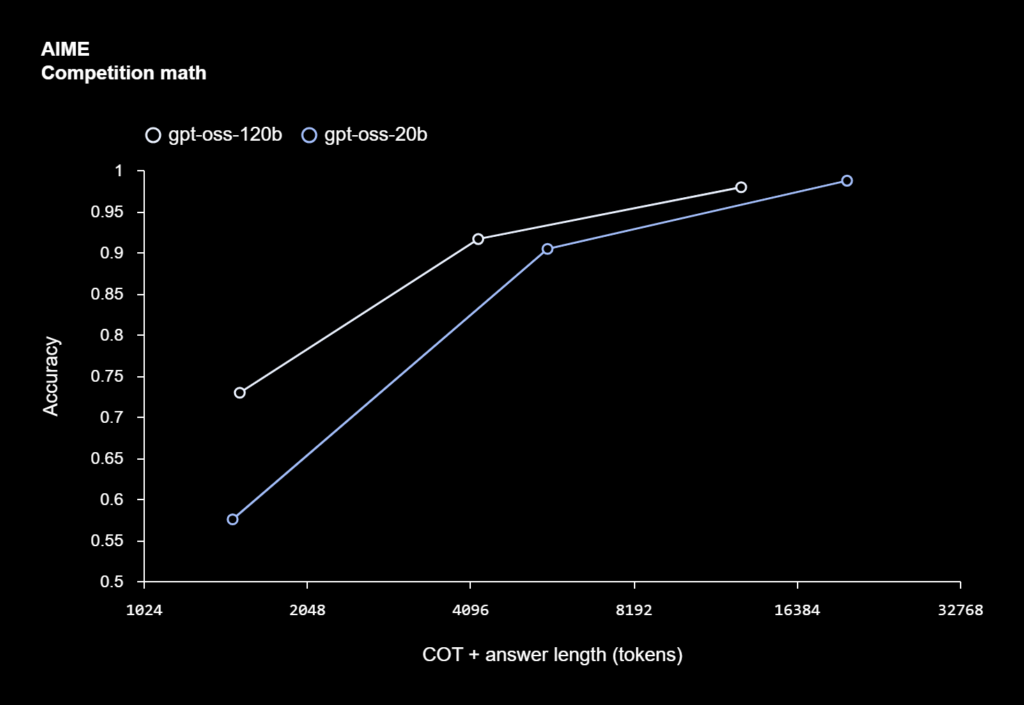
Notably, GPT-OSS models excel in:
- Code generation and debugging
- Chain-of-thought reasoning
- Tool use and agentic workflows
- Instruction-following and API orchestration
This positions them as ideal building blocks for AI agents, autonomous pipelines, and local assistants.
5. Real-World Use Cases: From Enterprise to Edge
Enterprise-Grade AI, Now On-Premise
GPT-OSS enables full on-premises deployment of high-performance LLMs—particularly valuable for industries like:
- Healthcare (patient privacy, HIPAA compliance)
- Finance (no cloud dependencies, low-latency predictions)
- Legal (document summarization, privacy preservation)
Research and Academia
Researchers now have a fully inspectable, modifiable model for studying:
- Language understanding
- Long-context modeling
- Agentic planning
- Tool invocation
- Reasoning paths
This level of transparency is unprecedented for models of this scale and opens new avenues in AI interpretability.
Mobile & Edge Deployment
GPT-OSS-20B is specifically tuned for on-device inference, supporting:
- Smartphones (e.g., Snapdragon AI-capable chips)
- Edge devices (e.g., Raspberry Pi + TPU/NPU)
- Autonomous drones, robots, or wearables
With ~3.6B active parameters per token and low-latency performance, 20B unlocks new potential for personal AI without needing the cloud.
Developers and Startups
No API rate limits. No black boxes. Total customization.
GPT-OSS allows developers to:
- Fine-tune on private datasets
- Deploy in offline scenarios
- Build secure assistants or AI agents
- Integrate with internal apps, CRMs, ERPs
6. Availability and Ecosystem Support
OpenAI’s GPT-OSS models are hosted and ready for use on platforms like:
- Hugging Face – preloaded with weights, config files, and quantized versions
- Ollama – for easy local deployment
- Docker + vLLM – for scalable inference servers
- Transformers Library – full compatibility with
transformers,accelerate,bitsandbytes
With proper setup, anyone can go from download to deployment in under 30 minutes.
7. GPT-OSS in Context: How It Stacks Up Against Other Open-Weight LLMs
| Model | Params | MoE | Context | Device Target | License | Performance |
|---|---|---|---|---|---|---|
| GPT-OSS-120B | 117B | Yes | 128K | High-end GPU | Apache 2.0 | Near o4-mini |
| GPT-OSS-20B | 21B | Yes | 128K | Laptops/Phones | Apache 2.0 | Mid-tier |
| Mistral 7B | 7B | No | 32K | Consumer GPU | Apache 2.0 | Solid |
| LLaMA-2 70B | 70B | No | 4K | High-end GPU | Custom | Good |
| Falcon 180B | 180B | No | 4K | Multi-GPU | Apache 2.0 | Mixed |
GPT-OSS not only scales more efficiently thanks to MoE and MXFP4—it also outperforms larger models on reasoning while requiring less memory and fewer FLOPs per token.
8. The Road Ahead: OpenAI’s New Direction?
OpenAI’s release of GPT-OSS signals a broader philosophical shift:
- From closed, SaaS-only models → to open, community-powered innovation
- From cloud dependency → to local, private compute
- From opaque black-boxes → to transparent research-grade tools
While proprietary models like GPT-4o remain closed, GPT-OSS provides a critical bridge between open innovation and high performance—an answer to the community’s long-standing call for powerful, permissively licensed models.
Conclusion: A New Era of Open-Weight AI Begins
The release of gpt-oss-120B and gpt-oss-20B isn’t just about model weights. It’s about unlocking autonomy, empowering the edge, and democratizing AI capabilities that were previously gated behind paywalls, APIs, and NDAs.
With top-tier performance, on-device flexibility, and community-first licensing, GPT-OSS paves the way for a future where developers own their tools, researchers understand their models, and enterprises control their data.
The message is loud and clear: Open is powerful again.
Check out the gpt-oss-120B, gpt-oss-20B and Technical Blog. All credit for this research goes to the researchers of this project. Explore one of the largest MCP directories created by AI Toolhouse containing over 4500+ MCP Servers: AI Toolhouse MCP Servers Directory