HyperLLaVA: Enhancing Multimodal Language Models with Dynamic Visual and Language Experts
Multimodal Large Language Models (MLLMs) have revolutionized natural language processing by enabling models to understand and generate human language. These models have proven to be highly versatile in various language-centric applications. However, extending their capabilities to handle multimodal inputs, such as text, images, videos, and audio, has been a significant challenge.
To bridge this gap, researchers have developed the HyperLLaVA framework, which enhances multimodal language models by incorporating dynamic visual and language experts. This article explores the innovative features of HyperLLaVA and its impact on improving the performance of MLLMs in handling diverse multimodal tasks.
Understanding MLLMs and their Limitations
Before delving into HyperLLaVA, let’s first understand the concept of Multimodal Large Language Models (MLLMs) and the challenges they face. MLLMs, like the popular LLaVA model, follow a two-stage training protocol to handle multimodal inputs effectively.
Explore 3600+ latest AI tools at AI Toolhouse 🚀
In the first stage, known as Vision-Language Alignment, a static projector is trained to synchronize visual features with the language model’s word embedding space. This alignment allows the language model to understand and process visual content. The second stage, Multimodal Instruction Tuning, fine-tunes the language model on multimodal instruction data to enhance its ability to respond to user requests involving visual content.
However, existing research often neglects the exploration of the projector’s structure and the language model’s tuning strategy. Most studies focus on scaling up the pretraining data, instruction-following data, visual encoders, or language models themselves. This limitation poses a potential hurdle in effectively handling diverse multimodal tasks.
Introducing HyperLLaVA and its Dynamic Experts
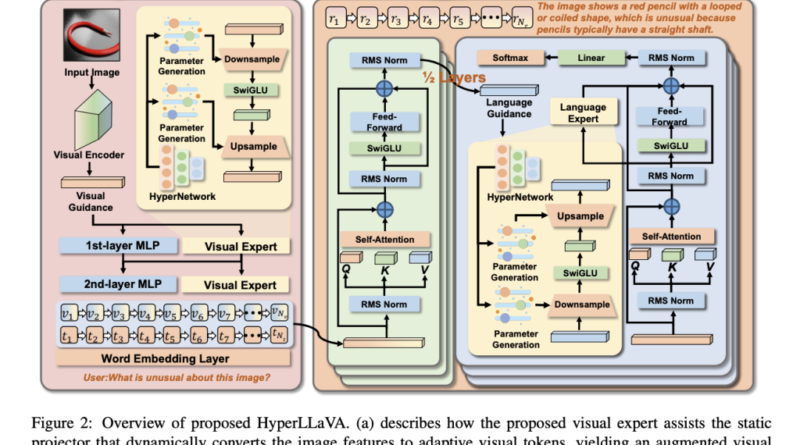
To address the limitations of traditional MLLMs, researchers have proposed the HyperLLaVA framework, which introduces dynamic visual and language experts. This innovative approach stems from the utilization of HyperNetworks, a technique that generates dynamic parameters based on input information.
By leveraging a carefully designed expert module derived from HyperNetworks, HyperLLaVA allows the model to adaptively tune both the static projector and language model layers. This dynamic adjustment facilitates enhanced reasoning abilities across diverse multimodal tasks.
The expert module in HyperLLaVA serves as a parameter-efficient fine-tuning approach for MLLMs, offering comparable performance to the original LLaVA model while significantly improving the model’s ability to handle various multimodal tasks. The integration of dynamic visual and language experts empowers the static projector and language model, enabling them to facilitate different multimodal tasks effectively.
Empirical Evaluation and Performance
To assess the effectiveness of HyperLLaVA, researchers conducted extensive experiments on multiple datasets, including well-known Visual Question Answering (VQA) datasets and Benchmark Toolkits. The evaluation aimed to compare HyperLLaVA against existing state-of-the-art approaches in the field.
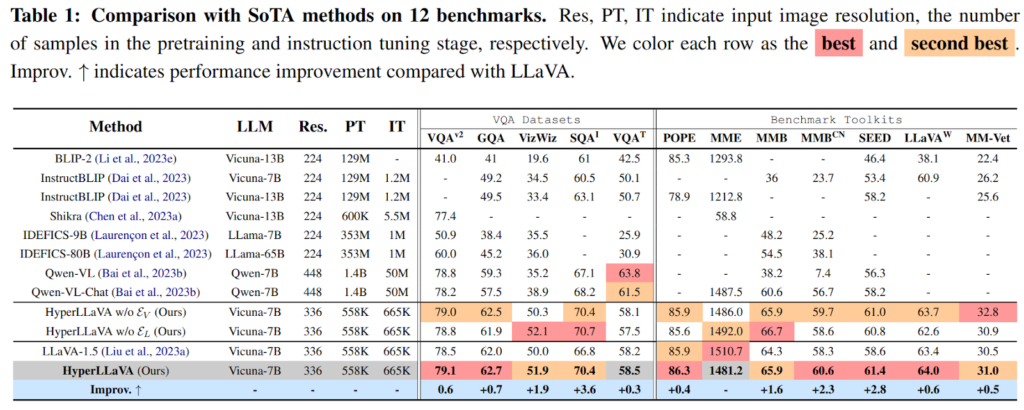
The results from these experiments showcased the superiority of HyperLLaVA over other approaches. Table 1 demonstrates that HyperLLaVA outperforms larger MLLMs with billions of trainable parameters across almost all multimodal scenarios. The carefully designed lightweight visual and language experts in HyperLLaVA enable the model to surpass the performance of the original LLaVA model in 11 out of 12 benchmarks.
These findings highlight the potential of HyperLLaVA’s dynamic tuning strategy in advancing multimodal learning systems. The adaptability to dynamically adjust projector and language model parameters, along with the integration of dynamic visual and language experts, provide a parameter-efficient methodology that outperforms existing benchmarks. This approach opens new avenues for understanding and seamlessly integrating multimodal information.
Conclusion
The HyperLLaVA framework presents an exciting development in the field of multimodal learning models. By introducing dynamic visual and language experts, HyperLLaVA enhances the performance of Multimodal Large Language Models (MLLMs) in handling diverse multimodal tasks.
Through its adaptive tuning strategy and lightweight expert module, HyperLLaVA surpasses existing state-of-the-art approaches in numerous benchmarks. This framework offers a parameter-efficient methodology that enables MLLMs to understand and integrate multimodal information more seamlessly.
The potential applications of HyperLLaVA are vast, ranging from developing flexible, general-purpose language assistants to improving multimodal understanding in various domains. As research in multimodal learning continues to evolve, HyperLLaVA provides a strong foundation for future advancements in this field.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰