Revolutionizing Question Answering With Google AI GRANOLA QA
In the field of natural language processing, large language models (LLMs) have made significant strides in providing accurate answers to factual questions. However, evaluating the quality of these answers can be challenging due to their varying levels of granularity. To address this issue, Google AI has introduced GRANOLA QA, a revolutionary question-answering framework that incorporates multi-granularity evaluation [2].
The Challenge of Evaluating Factual Answers
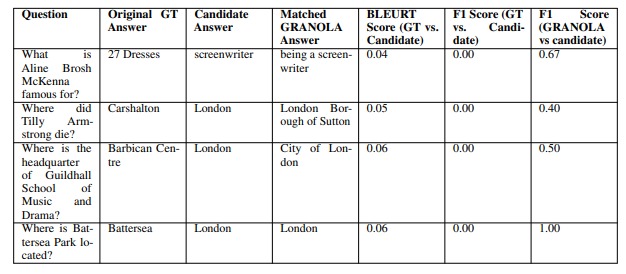
Factual answers can be provided at different levels of granularity. For instance, the question “When was Barack Obama born?” could be answered with “1961” or “August 4, 1961.” Traditional question-answering evaluation settings do not consider this versatility of answers and typically assess the predicted answer against a fixed set of reference answers of the same granularity. This approach often underestimates the knowledge of LLMs, leading to a knowledge evaluation gap [1].
Introducing GRANOLA QA
To overcome the limitations of traditional evaluation settings, Google AI has developed GRANOLA QA, a multi-granularity question-answering framework. GRANOLA QA evaluates answers not only based on their accuracy but also on their informativeness [2].
The answer generation process of GRANOLA QA consists of two steps. First, a description of the answer entity is obtained using an external knowledge graph. Any entities mentioned in the question are also included in this description. Second, an LLM is prompted to generate an ordered list of answers with varying levels of granularity. These answers are evaluated based on their accuracy and informativeness [1].
🔥Explore 3500+ AI Tools and 2000+ GPTs at AI Toolhouse
Evaluating Accuracy and Informativeness
GRANOLA QA measures the accuracy of answers by matching them against any of the GRANOLA answers. This approach allows for flexible matching, as answers can be correct at different levels of granularity. However, accuracy alone is not sufficient to evaluate the quality of an answer. GRANOLA QA also considers the informativeness of answers by comparing them to fine-grained answers using an appropriate weighting scheme [1].
To verify the correctness of an answer, the researchers used WikiData, a structured knowledge base. Additionally, they checked whether the response was a trivial answer that could be generated solely based on the question template. The researchers also assessed the granularity of the answers by comparing them to their preceding answers [1].
Enhancing the ENTITYQUESTIONS Dataset
In addition to introducing GRANOLA QA, the researchers at Google AI have developed GRANOLA-EQ, a multi-granularity version of the ENTITYQUESTIONS dataset. They evaluated models using different decoding methods, including a novel strategy called DRAG (Decoding with Random Auxiliary Goals). DRAG encourages LLMs to tailor the granularity level of their responses based on their uncertainty levels. The results showed that DRAG improved the average accuracy of LLMs by 20 points, particularly for rare entities [1].
Limitations and Future Research
While GRANOLA QA and DRAG have shown promising results, there are still some limitations to consider. The approach for enhancing the QA benchmark with multi-granularity answers relies on extracting entities from the original QA pairs and matching them to a knowledge graph entry. This process may be more challenging when dealing with less-structured datasets. Additionally, for a more comprehensive assessment, distinguishing between correct answers based on true knowledge instead of educated guesses is essential [1].
Looking forward, the work of Google AI in revolutionizing question answering with multi-granularity evaluation serves as a starting point for future research. By aligning the granularity of LLM responses with their uncertainty levels, it becomes possible to enhance the accuracy and informativeness of these models. With further advancements, question answering systems can provide more reliable and detailed answers, ultimately benefiting various industries and domains that rely on accurate information retrieval [1].
Conclusion
The introduction of GRANOLA QA by Google AI marks a significant advancement in the field of question answering. By incorporating multi-granularity evaluation, GRANOLA QA provides a more comprehensive assessment of answers generated by large language models. This approach not only improves the accuracy of answers but also ensures their informativeness. While there are still challenges to overcome and further research to be conducted, the work of Google AI paves the way for more reliable and detailed question-answering systems in the future [2].
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰