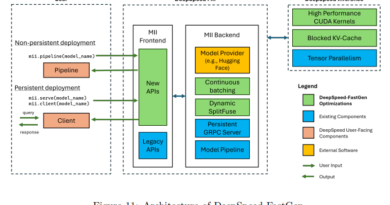
This AI Paper from ByteDance Introduces MegaScale: Revolutionizing Large Language Model Training with Over 10,000 GPUs
Machine learning has revolutionized the field of artificial intelligence, enabling computers to learn and make predictions without being explicitly programmed. One of the most remarkable advancements in machine learning has been the development of large language models (LLMs), which can mimic human language with astonishing accuracy. These models have found applications in various areas such as machine translation, summarization, and conversational AI. However, training LLMs on a large scale has always been a challenge due to the computational demands involved.
ByteDance, a leading technology company, has recently introduced an AI paper called “MegaScale” that addresses this challenge. In collaboration with Peking University, ByteDance has developed a system that revolutionizes large language model training by harnessing over 10,000 GPUs. This article will delve into the details of MegaScale and how it enables the scaling of machine learning to new peaks.


The Challenge of Scaling LLM Training
Training large language models with hundreds of billions of parameters requires enormous computational power. The sheer scale of the models and the vast datasets they are trained on make it a formidable challenge to achieve efficient and stable training. Traditional methods of scaling up LLM training have often faced issues of computational efficiency and stability, limiting the size and capabilities of these models.
Introducing MegaScale: Optimizing Computational Power
MegaScale is designed to address the efficiency and stability challenges associated with scaling up LLM training. It recognizes that simply increasing computational power is not enough; optimizing how that power is utilized is crucial. The system incorporates innovative techniques across model architecture, data pipeline, and network performance to ensure that every bit of computational power contributes to more efficient and stable training.
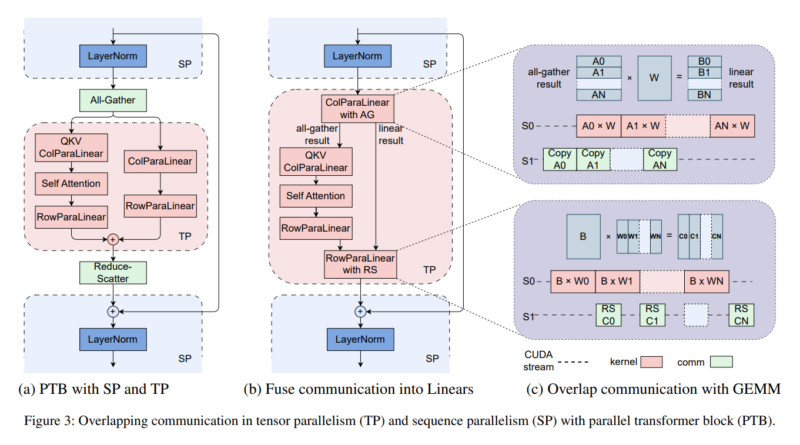
Parallel Transformer Blocks and Sliding Window Attention
MegaScale employs parallel transformer blocks and sliding window attention mechanisms to reduce computational overhead. By dividing the model into smaller parallel blocks, the system can efficiently distribute the computational workload across multiple GPUs. Sliding window attention further enhances efficiency by only attending to a subset of the input tokens at a time, reducing the overall computational requirements.
Optimization Strategies
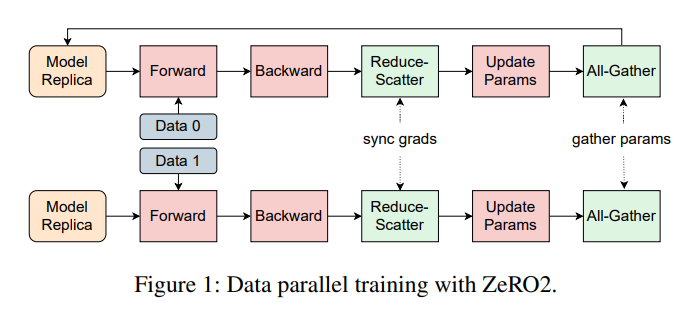
MegaScale utilizes a suite of optimization strategies to maximize resource utilization. These strategies include data, pipeline, and tensor parallelism. Data parallelism involves splitting the input data across multiple GPUs, allowing for parallel processing. Pipeline parallelism divides the model into stages, with each stage processed by a separate set of GPUs. Tensor parallelism, on the other hand, partitions the model’s tensors across multiple GPUs, enabling parallel computation.
Custom Network Design
To facilitate efficient communication between the thousands of GPUs involved in the training process, MegaScale incorporates a custom network design. This design accelerates the exchange of information between GPUs, minimizing latency and maximizing computational efficiency.
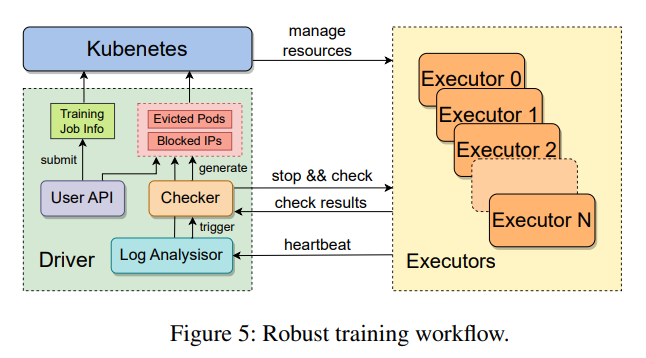
Diagnostic and Recovery Capabilities
MegaScale also offers robust diagnostic and recovery capabilities. The system includes a set of monitoring tools that track system components and events, enabling the rapid identification and rectification of faults. This ensures high training efficiency and maintains stability over time, a critical factor in deploying large-scale LLMs.
Real-World Performance and Impact
The impact of MegaScale is exemplified by its performance in real-world applications. In a test scenario where a 175B parameter LLM was trained on 12,288 GPUs, MegaScale achieved a model FLOPs utilization (MFU) of 55.2%. This efficiency surpasses existing frameworks and significantly shortens training times while enhancing the stability of the training process. MegaScale’s breakthrough in large-scale LLM training makes it a practical and sustainable solution for training models of unprecedented size and complexity.
Conclusion
MegaScale, introduced by ByteDance in collaboration with Peking University, represents a significant milestone in the scaling of machine learning to new peaks. By harnessing over 10,000 GPUs and implementing innovative optimization techniques, MegaScale revolutionizes large language model training. The system addresses the efficiency and stability challenges associated with scaling up LLM training, enabling the training of models with hundreds of billions of parameters. With its diagnostic and recovery capabilities, MegaScale ensures high training efficiency and consistent performance over time. The real-world performance of MegaScale further demonstrates its impact in making large-scale LLM training practical and sustainable.
In conclusion, MegaScale opens up new possibilities for the development of more advanced and sophisticated language models. As the field of machine learning continues to evolve, the scalability of these models will play a crucial role in unlocking their full potential. With MegaScale, the boundaries of machine learning are being pushed further, paving the way for new breakthroughs in language understanding and generation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰