Microsoft AI Research Unveils DeepSpeed-FastGen: Elevating LLM Serving Efficiency with Innovative Dynamic SplitFuse Technique
Large language models (LLMs) have revolutionized various AI-infused applications, from chat models to autonomous driving. This evolution has spurred the need for systems that efficiently deploy and serve these models, especially under the increasing demand for handling long-prompt workloads. The major hurdle in this domain has been balancing high throughput and low latency in serving systems, a challenge existing frameworks need help to meet.
Traditional approaches to LLM serving, while adept at training models effectively, falter during inference, especially in tasks like open-ended text generation. This inefficiency stems from the interactive nature of these applications and the poor arithmetic intensity of such tasks, which bottleneck the inference throughput in existing systems. vLLM, powered by PagedAttention, and research systems like Orca have improved LLM inference performance. However, they still face challenges in maintaining a consistent quality of service, particularly for long-prompt workloads.
🔥 Explore 3500+ AI Tools and 2000+ GPTs at AI Toolhouse
Addressing the Challenges in LLM Serving Efficiency
Historical advancements in LLM inference, such as blocked KV caching and dynamic batching, aimed to address memory efficiency and GPU utilization. Blocked KV caching, as implemented in vLLM’s Paged Attention, tackled memory fragmentation caused by large KV caches, increasing total system throughput. Despite its attempts to improve GPU utilization, dynamic batching often required padding inputs or stalling the system to construct larger batches. These methods, while innovative, are still needed to resolve the challenges of efficiently serving LLMs fully, particularly under the constraints of long-prompt workloads.
Introducing DeepSpeed-FastGen
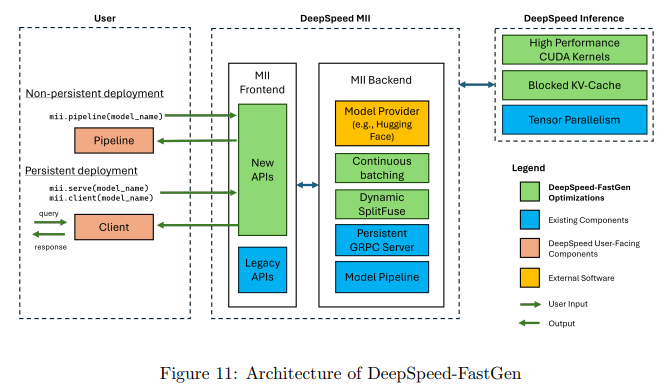
Microsoft DeepSpeed researchers introduced DeepSpeed-FastGen, a revolutionary system utilizing the Dynamic SplitFuse technique in response to the abovementioned challenges. This system delivers up to 2.3x higher effective throughput, 2x lower latency on average, and up to 3.7x lower tail latency compared to state-of-the-art systems like vLLM. DeepSpeed-FastGen combines DeepSpeed-MII and DeepSpeed-Inference to create an efficient, user-friendly serving system for LLMs. It supports a range of models and offers both non-persistent and persistent deployment options, catering to various user scenarios.



The Dynamic SplitFuse Technique
The cornerstone of DeepSpeed-FastGen’s efficiency is the Dynamic SplitFuse strategy, which enhances continuous batching and system throughput. This novel token composition strategy for prompt processing and generation allows long prompts to be decomposed into smaller chunks across multiple forwards passes. This method leads to better system responsiveness and higher efficiency as long prompts no longer necessitate extremely long forward passes. The approach also ensures consistent forward pass sizes, which is a primary determinant of performance, leading to more consistent latency than competing systems. This translates to significant reductions in generation latency, as evidenced in the performance evaluations.
Performance Evaluation and Benchmarking
DeepSpeed-FastGen’s performance was rigorously benchmarked and analyzed. The system was evaluated against vLLM on various models and hardware configurations. The evaluations demonstrated that DeepSpeed-FastGen achieves up to 2.3x higher effective throughput, 2x lower latency on average, and up to 3.7x lower tail latency compared to vLLM. These improvements are particularly notable in LLM serving, where both throughput and latency are crucial metrics.
Conclusion
DeepSpeed-FastGen represents a major advancement in efficiently deploying and scaling large language models. By addressing the critical challenges of throughput and latency in LLM serving, DeepSpeed-FastGen is a notable contribution to the field, paving the way for more efficient and scalable AI applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰