Unveiling the Paradox: A Groundbreaking Approach to Reasoning Analysis in AI by the University of Southern California Team
Artificial Intelligence (AI) has made remarkable progress in recent years, with large language models (LLMs) leading the way in natural language understanding and generation. These models have revolutionized how machines interact with humans, enabling them to answer questions, summarize text, and perform various other tasks that require language comprehension. However, as impressive as these models are, there is a growing concern about their reasoning capabilities and the consistency of their logic and conclusions.
The Challenge of Self-Contradictory Reasoning
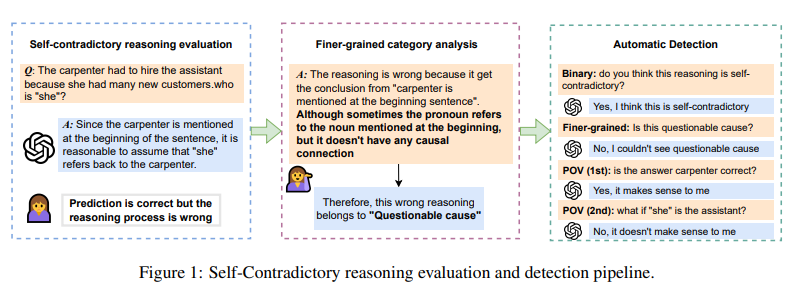
One particular area of concern is self-contradictory reasoning, where a model’s logic does not align with its conclusions. This discrepancy raises doubts about the reliability and soundness of the reasoning process employed by LLMs. Even if these models provide correct answers, their underlying logic may be flawed, leading to inconsistent reasoning.
Traditional evaluation metrics, such as accuracy, fall short in scrutinizing the reasoning process and assessing its consistency. By focusing solely on outcomes, these metrics fail to detect instances where the model’s logic is inconsistent or self-contradictory. Consequently, models may receive high scores for correct answers, despite flaws in their reasoning process.
A Novel Approach by the University of Southern California Team
Addressing the need for a more comprehensive evaluation of LLMs, researchers from the University of Southern California (USC) have introduced a groundbreaking approach to reasoning analysis. Their method aims to scrutinize and detect instances of self-contradictory reasoning in LLMs, providing a more granular view of where and how the models’ logic falters.
This approach goes beyond surface-level performance indicators and delves into the reasoning processes of LLMs. By identifying and categorizing inconsistencies, the USC team offers a deeper understanding of the alignment, or lack thereof, between the models’ reasoning and predictions. This breakthrough promises a more holistic evaluation of LLMs, shedding light on their reasoning quality and facilitating targeted improvements in model training and evaluation practices.
Assessing Reasoning Quality Across Datasets
The USC research team’s methodology involves evaluating reasoning across various datasets to pinpoint inconsistencies that previous metrics might overlook. This comprehensive evaluation is crucial in understanding the trustworthiness and reliability of LLMs in making logical and consistent conclusions.
To probe the depths of reasoning quality, the USC team leverages the power of LLMs like GPT-4. By carefully examining different types of reasoning errors and classifying them into distinct categories, the researchers shed light on specific areas where the models struggle. This classification provides valuable insights for enhancing model training and evaluation practices, leading to more reliable AI systems.
The Paradox of Self-Contradictory Reasoning
Despite achieving high accuracy on numerous tasks, LLMs, including GPT-4, have shown a propensity for self-contradictory reasoning. This paradoxical observation indicates that models often rely on incorrect or incomplete logic pathways to arrive at correct answers. This flaw highlights the limitations of outcome-based evaluation metrics like accuracy, which can mask the underlying reasoning quality of LLMs.
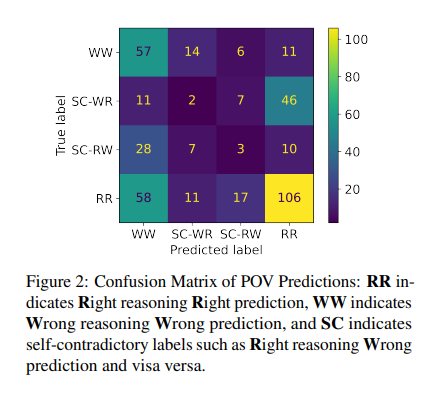


The discovery of self-contradictory reasoning in LLMs calls for a paradigm shift in how we assess and understand the capabilities of these advanced models. It emphasizes the need for more nuanced and comprehensive evaluation frameworks that prioritize the integrity of reasoning processes. Merely focusing on the correctness of answers is insufficient; the logical coherence of the reasoning leading to those answers must also be considered.
Toward a More Reliable and Consistent AI
The USC research on reasoning analysis in AI serves as a wake-up call to reevaluate how we gauge the capabilities of LLMs. By proposing a detailed framework for assessing reasoning quality, the researchers pave the way for more reliable and consistent AI systems. This endeavor is not only about critiquing current models but also about laying the groundwork for future advancements in AI.
Moving forward, researchers and developers must prioritize logical consistency and reliability in the next generation of LLMs. Emphasizing these qualities will ensure that AI systems are not only powerful but also trustworthy. By addressing the paradox of self-contradictory reasoning, the USC team’s groundbreaking approach sets the stage for improved AI technologies that can make a positive impact in various domains.
In conclusion, the research conducted by the University of Southern California team sheds light on the critical issue of self-contradictory reasoning in LLMs. The researchers advocate for a more comprehensive evaluation of AI systems by proposing a detailed framework for assessing reasoning quality. This endeavor calls for a shift in focus from outcome-based metrics to the logical coherence and reliability of reasoning processes. Ultimately, this research contributes to the development of more reliable and trustworthy AI systems that can benefit society as a whole.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰