Scaling Multimodal AI with CuMo
Artificial Intelligence (AI) has made significant strides in recent years, particularly in the field of language processing. Large language models (LLMs) like GPT-4 have revolutionized text analysis and comprehension. However, understanding visual data alongside text has proven to be a challenge. This is where multimodal AI comes into play, enabling machines to perceive and reason like humans by integrating text, images, and audio. CuMo, short for “CuMixing Models,” is a cutting-edge approach that breaks down barriers in scaling multimodal AI.
The Challenge of Scaling Multimodal AI
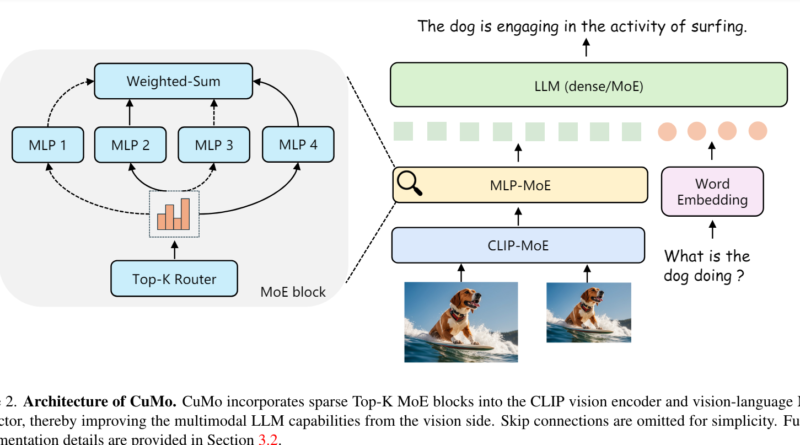
Creating powerful multimodal LLMs poses challenges when it comes to scaling up efficiently while maintaining performance. Traditional approaches often rely on monolithic models to analyze both text and visual data, resulting in increased computational complexity and potential performance degradation. To overcome these challenges, researchers have turned to the concept of mixture-of-experts (MoE) architecture, known for its ability to scale up LLMs by replacing dense layers with sparse expert modules.
Introducing CuMo: Scaling Multimodal AI Efficiently
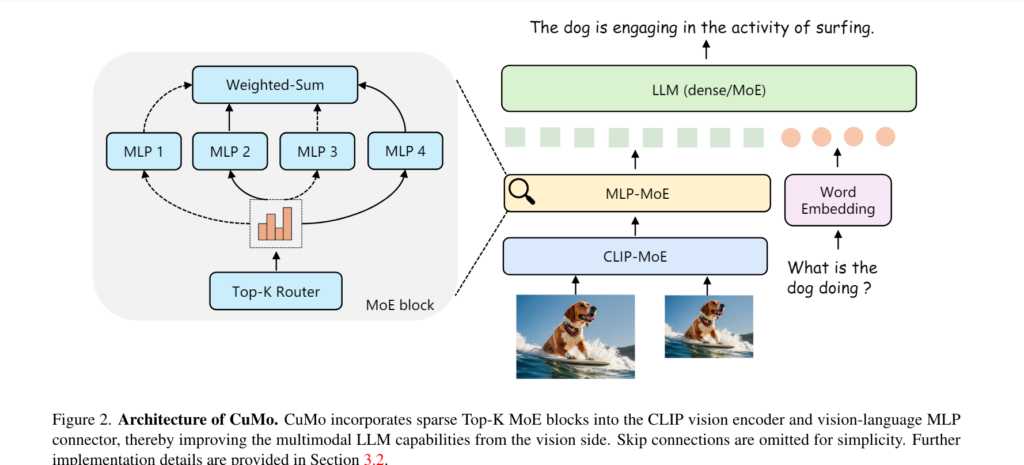
CuMo takes inspiration from the MoE architecture and introduces a novel approach to scaling multimodal AI. Instead of relying on a single large model, CuMo integrates sparse MoE blocks into the vision encoder and the vision-language connector of a multimodal LLM. This allows different expert modules to process different parts of the visual and text inputs in parallel, resulting in more efficient scaling. The key innovation in CuMo is the concept of co-upcycling, which involves initializing the sparse MoE modules from a pre-trained dense model before fine-tuning them. This initialization provides a better starting point for the experts to specialize during training.
CuMo Three-Stage Training Process

CuMo employs a thoughtful three-stage training process to optimize performance and stability:
- Pre-training the vision-language connector: In this stage, only the vision-language connector is pre-trained on image-text data to align the modalities. This step ensures that the model can effectively process both visual and textual information.
- Joint pre-finetuning: Next, all model parameters are pre-finetuned jointly on caption data to warm up the full system. This step helps optimize the overall performance of CuMo.
- Fine-tuning with visual instruction data: Finally, CuMo is fine-tuned with visual instruction data, introducing the co-upcycled sparse MoE blocks along with auxiliary losses to balance the expert load and stabilize training. This comprehensive approach allows CuMo to scale up efficiently without sacrificing performance.
Evaluating CuMo’s Performance



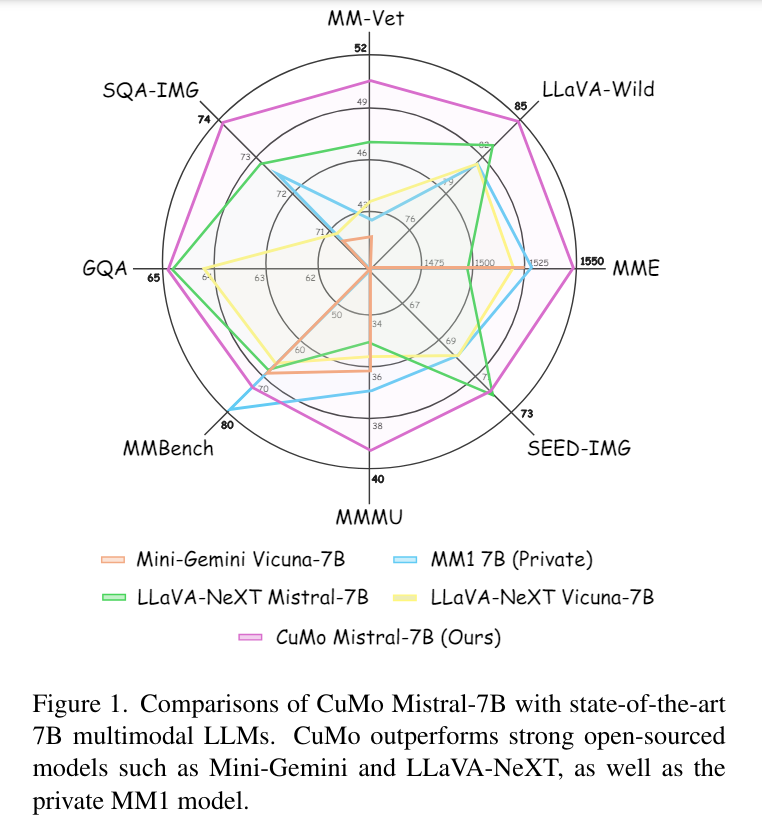
To assess the effectiveness of CuMo, the researchers evaluated its performance on various benchmarks and multimodal reasoning challenges. CuMo models trained solely on publicly available datasets outperformed other state-of-the-art approaches within the same model size categories across the board. Even compact CuMo models with 7 billion parameters matched or exceeded the performance of much larger 13 billion parameter alternatives on many challenging tasks. These results demonstrate the potential of sparse MoE architectures combined with co-upcycling for developing efficient and capable multimodal AI models.
CuMo: Breaking Barriers and Enabling Advanced AI Systems
CuMo’s groundbreaking approach to scaling multimodal AI has the potential to break down barriers in understanding and reasoning about text, images, and beyond. By integrating sparse MoE blocks and employing a comprehensive training process, CuMo achieves efficient scaling without sacrificing performance. This advancement opens up new possibilities for developing AI systems that can seamlessly comprehend and analyze multimodal data.
The integration of CuMo into AI systems can have far-reaching implications across various domains. In the field of language translation and learning, multimodal AI can help break down language barriers more effectively, enabling more accurate and contextually aware translations. In the realm of cross-cultural communication, multimodal AI can play a vital role in fostering understanding and empathy. Furthermore, in areas such as visual question-answering and multimodal reasoning, CuMo’s capabilities can significantly enhance the accuracy and efficiency of AI systems.
Conclusion
CuMo represents a significant breakthrough in scaling multimodal AI. By leveraging sparse MoE blocks and co-upcycling, CuMo enables efficient scaling while maintaining or surpassing the performance of larger models. This approach opens up new avenues for developing advanced AI systems that can seamlessly comprehend and reason about text, images, and other modalities. The integration of CuMo into AI systems has the potential to transform various domains, from language translation to cross-cultural communication. As AI continues to evolve, innovations like CuMo will play a crucial role in breaking down barriers and unlocking the full potential of multimodal AI.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
Read our other blogs on AI Tools 😁
If you like our work, you will love our Newsletter 📰