Meet BiTA: An Innovative AI Method Expediting LLMs via Streamlined Semi-Autoregressive Generation and Draft Verification
Large language models (LLMs) have revolutionized the field of natural language processing (NLP) in recent years. These models, based on transformer architectures, can generate coherent and contextually relevant text. However, the inference delay associated with LLMs has been a significant challenge, especially in contexts with constrained resources such as edge devices and real-time applications like chatbots. In this article, we will explore an innovative AI method called BiTA that aims to expedite LLMs through streamlined semi-autoregressive generation and draft verification.
The Challenge of Inference Delay in LLMs
LLMs, such as Chat-GPT and LLaMA-2, have seen a rapid increase in the number of parameters, ranging from several billion to tens of trillions [1][5]. While these models are powerful generators, the large number of parameters leads to significant inference delay due to the high computing load. This delay can be problematic, especially in applications that require real-time responses.
Most decoder-only LLMs follow an autoregressive (AR) pattern of token generation, where each token undergoes its inference execution, resulting in multiple transformer calls [1][5]. This token-by-token generation pattern leads to reduced computational efficiency and longer wall-clock periods. These outcomes are primarily due to the limitations of memory bandwidth [1].
🔥Explore 3500+ AI Tools and 2000+ GPTs at AI Toolhouse
Semi-Autoregressive (SAR) Decoding for Efficient Inference
To address the challenges of inference delay, researchers at Intellifusion Inc. and Harbin Institute of Technology have proposed an innovative approach called Bi-directional Tuning for lossless Acceleration (BiTA) [1]. BiTA aims to achieve lossless SAR decoding for AR language models by learning a small number of additional trainable parameters [1].
SAR decoding involves synthesizing several tokens simultaneously during model inference, reducing the need for multiple inference executions [1][5]. However, most LLMs are designed to generate AR models, and re-training them as SAR models can be challenging due to the differences in their training objectives. BiTA overcomes this challenge by introducing bi-directional tuning and simplified verification of SAR draft candidates.
BiTA: Bi-directional Tuning and Simplified Verification
BiTA consists of two main components: bi-directional tuning and simplified verification [1][5].
Bi-directional Tuning
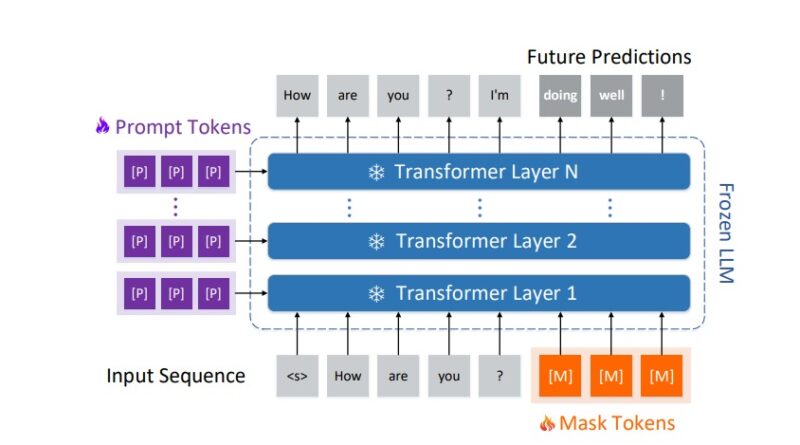
Bi-directional tuning involves incorporating both prompt and mask tokens in the AR model to enable the prediction of future tokens [1]. This goes beyond the next token, allowing for more efficient generation. The introduction of learnable prefix and suffix embeddings in the token sequence enables this approach [1]. The transformed AR model facilitates generation and verification in a single forward pass, thanks to an intricate tree-based attention mechanism. This architecture eliminates the need for additional validation procedures or third-party verification models [1].
Simplified Verification
The second component of BiTA is simplified verification. After the drafting phase, the target LLM evaluates the drafted tokens in parallel, ensuring the quality and coherence of the generated text [3]. The simplified verification process is efficient and does not require additional models or complex validation procedures. This streamlined approach further enhances the speed and efficiency of LLM inference [1].
The Advantages of BiTA
BiTA offers several advantages over traditional LLM inference methods:
- Faster Inference: By synthesizing multiple tokens in a single step, BiTA reduces the number of transformer calls and significantly speeds up LLM inference [1].
- Lossless Generation: BiTA maintains the high-quality generation capabilities of AR language models while achieving efficient SAR decoding [1].
- Universal Architecture: BiTA’s architecture allows it to be used as a plug-and-play module for any publicly available transformer-based LLMs. This adaptability makes it a versatile solution for accelerating various LLM applications [1].
Testing and Results
Extensive testing has been conducted to evaluate the performance of BiTA in various LLM scenarios [1]. These tests involved LLMs of different sizes and demonstrated impressive speedups ranging from 2.1× to 3.3× [1]. The model’s efficient creation and verification processes, combined with its adaptable prompting design, make BiTA a promising solution for resource-constrained and real-time applications [1].
Conclusion
BiTA, an innovative AI method developed by researchers at Intellifusion Inc. and Harbin Institute of Technology, addresses the challenge of inference delay in LLMs. By combining bi-directional tuning and simplified verification, BiTA enables lossless semi-autoregressive decoding and significantly speeds up LLM inference. The model’s efficient creation and verification processes make it a valuable tool for applications where real-time responses are essential. With its universal architecture, BiTA can be easily integrated into existing transformer-based LLMs, enhancing their performance without compromising on quality.
BiTA represents a significant step towards overcoming the challenges associated with LLM inference delay, opening up possibilities for a wide range of applications that require fast and efficient natural language processing.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰