AI Paper from China Introduces ‘AGENTBOARD’: An Open-Source Evaluation Framework Tailored to Analytical Evaluation of Multi-Turn LLM Agents
The field of artificial intelligence (AI) continues to evolve rapidly, with new advancements and breakthroughs being made regularly. One such recent development comes from researchers in China who have introduced a groundbreaking AI paper called “AGENTBOARD.” This paper introduces an open-source evaluation framework specifically tailored to the analytical evaluation of multi-turn LLM (Large Language Model) agents. In this article, we will delve into the details of this AI paper, exploring the significance of AGENTBOARD and its potential impact on the field of AI.
Introduction to AGENTBOARD
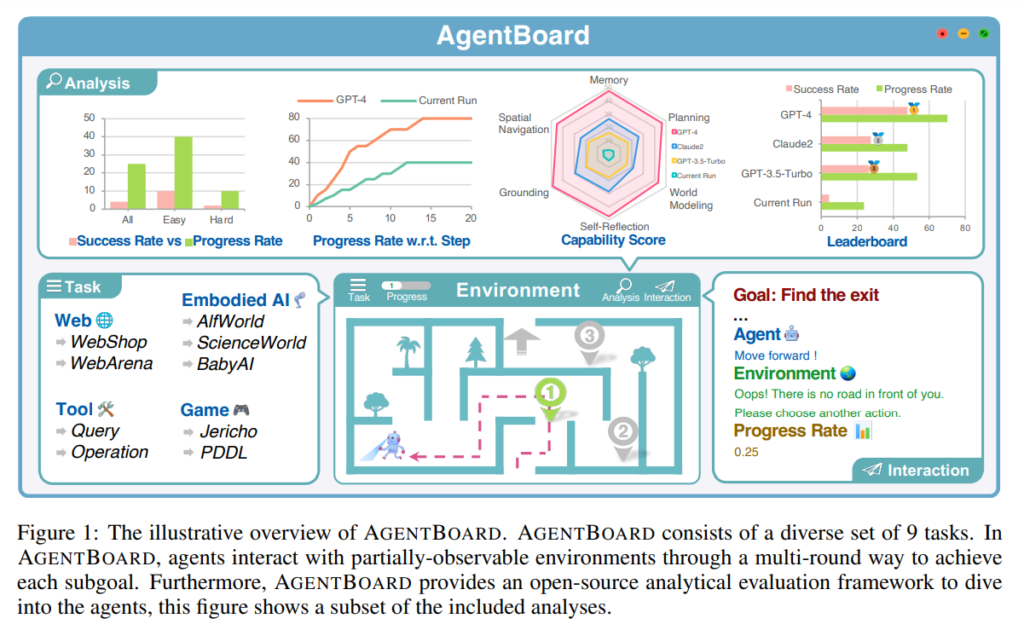
AGENTBOARD, developed by researchers from the University of Hong Kong, Zhejiang University, Shanghai Jiao Tong University, Tsinghua University, School of Engineering, Westlake University, and The Hong Kong University of Science and Technology, is an innovative benchmark and open-source evaluation framework for analyzing LLM agents [1]. The framework aims to address the challenges faced by existing evaluation frameworks, such as benchmarking diverse scenarios, maintaining partially observable environments, and capturing multi-round interactions.
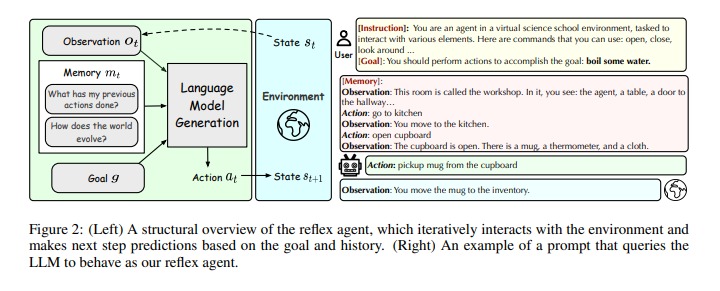
The Need for Analytical Evaluation of Multi-Turn LLM Agents
Evaluating LLM agents is crucial for their integration into practical applications. However, existing evaluation frameworks often provide limited insights due to their focus on simplified metrics like final success rates. To truly understand the capabilities and limitations of LLM agents, a more detailed and systematic evaluation approach is required. AGENTBOARD aims to fill this gap by introducing a fine-grained progress rate metric and a comprehensive toolkit for interactive visualization, enabling a nuanced analysis of LLM agents [1].
🔥Explore 3500+ AI Tools and 2000+ GPTs at AI Toolhouse
The Capabilities of LLM Agents
LLMs, such as GPT-3 and GPT-4, have demonstrated remarkable decision-making abilities and zero-shot generalization skills. These models excel in tasks that involve emergent reasoning and instruction-following skills. Techniques like contextual prompting enable LLMs to generate executable actions, while specialized training methods further enhance their performance as decision-making agents [2].
The Features of AGENTBOARD
AGENTBOARD offers several features that make it a valuable tool for evaluating LLM agents. With nine diverse tasks and over 1000 environments, AGENTBOARD covers a wide range of scenarios, including embodied AI, game agents, web agents, and tool agents. This ensures that the evaluation framework captures the multi-round and partially observable characteristics of real-world AI applications [1].
The framework also provides a fine-grained progress rate metric, which goes beyond traditional success rates to measure incremental advancements. This metric allows researchers to track the progress of LLM agents more accurately and understand the factors contributing to their performance [1].
Additionally, AGENTBOARD includes a comprehensive toolkit for interactive visualization. This toolkit enables researchers to analyze LLM agents’ capabilities and limitations in a more nuanced and detailed manner. The interactive visualization web panel provides insights into agent behavior, decision-making processes, and model advancements, offering a deeper understanding of LLM agents’ performance [1].
Comparison with Existing Evaluation Frameworks
AGENTBOARD stands out from existing evaluation frameworks due to its focus on analytical evaluation and its comprehensive nature. While some evaluation frameworks may provide a high-level assessment of LLM agents’ performance, AGENTBOARD offers a more detailed analysis by considering multi-round interactions, partially observable environments, and fine-grained progress rates.
The fine-grained progress rate metric introduced by AGENTBOARD enables researchers to track incremental advancements in LLM agents’ performance. This metric provides a more accurate representation of their capabilities and allows for a better understanding of the factors contributing to their success.
The interactive visualization toolkit offered by AGENTBOARD further enhances the evaluation process. Researchers can explore agent behavior and decision-making processes in a user-friendly interface, facilitating in-depth analysis and interpretation of LLM agents’ performance.
Potential Impact on the Field of AI
The introduction of AGENTBOARD has the potential to significantly impact the field of AI. By providing a comprehensive evaluation framework tailored to multi-turn LLM agents, AGENTBOARD enables researchers to gain a deeper understanding of these agents’ capabilities and limitations. This knowledge can inform the development of more advanced and effective AI systems, leading to improved performance in various applications.
Moreover, AGENTBOARD’s open-source nature fosters collaboration and knowledge sharing among researchers. The availability of the evaluation framework and toolkit allows for reproducibility and facilitates the comparison of different LLM models and techniques. This collaboration can accelerate advancements in the field of AI and drive innovation in the development of LLM agents.
Conclusion
The introduction of AGENTBOARD, an open-source evaluation framework tailored to the analytical evaluation of multi-turn LLM agents, is a significant development in the field of AI. This framework addresses the limitations of existing evaluation frameworks and provides researchers with a comprehensive toolkit for analyzing the capabilities and limitations of LLM agents. With its fine-grained progress rate metric and interactive visualization features, AGENTBOARD offers a nuanced and detailed evaluation approach. The potential impact of AGENTBOARD on the field of AI is significant, paving the way for advancements in LLM agent development and fostering collaboration among researchers.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰