UC Berkeley and UCSF Researchers Propose Cross-Attention Masked Autoencoders (CrossMAE): A Leap in Efficient Visual Data Processing
One of the most exciting areas of research in computer vision is the efficient processing of visual data. From analyzing images to developing intelligent systems, efficient visual data processing is crucial for a wide range of applications. In recent years, researchers have made significant strides in this field, but the quest for more efficient and effective techniques is ongoing.
Traditional methods in visual data processing have relied on self-supervised learning and generative modeling techniques. While these approaches have been groundbreaking, they face limitations when it comes to efficiently handling complex visual tasks, particularly in the case of masked autoencoders (MAE). MAEs are designed to reconstruct images from a limited set of visible patches, but they often require high computational resources due to their reliance on self-attention mechanisms.
To address these challenges, researchers from UC Berkeley and UCSF have proposed a new framework called Cross-Attention Masked Autoencoders (CrossMAE). This innovative approach departs from traditional MAEs by exclusively utilizing cross-attention for decoding masked patches. Unlike traditional MAEs, which use a combination of self-attention and cross-attention, CrossMAE simplifies and expedites the decoding process by focusing solely on cross-attention between visible and masked tokens.
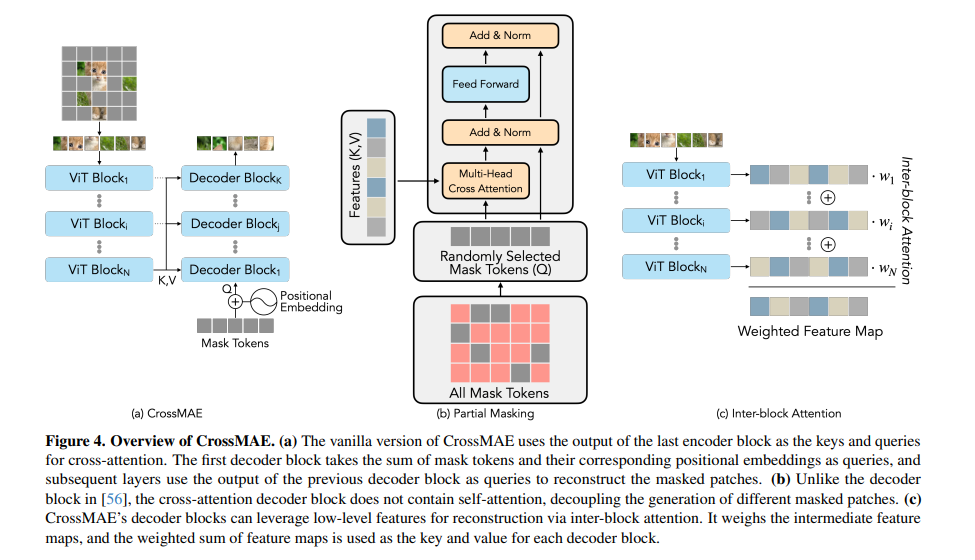
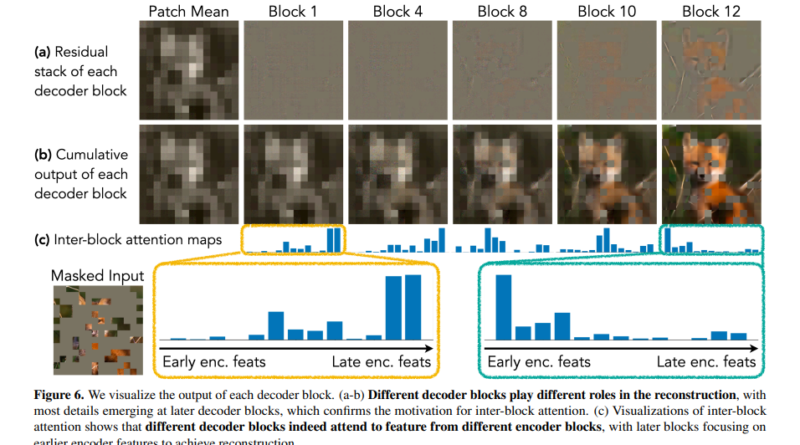
The key to CrossMAE’s efficiency lies in its unique decoding mechanism, which leverages only cross-attention between masked and visible tokens. This eliminates the need for self-attention within mask tokens, a significant departure from traditional MAE approaches. By focusing on decoding a subset of mask tokens, CrossMAE enables faster processing and training without compromising the quality of the reconstructed image or the performance in downstream tasks.
In benchmark tests such as ImageNet classification and COCO instance segmentation, CrossMAE performed on par with or outperformed traditional MAE models while significantly reducing decoding computation. The quality of image reconstruction and the effectiveness in performing downstream tasks remained unaffected, demonstrating CrossMAE’s ability to handle complex visual tasks with enhanced efficiency.
The introduction of CrossMAE in computer vision represents a significant advancement in the field. By reimagining the decoding mechanism of masked autoencoders and offering a more efficient path for processing visual data, CrossMAE has the potential to redefine approaches in computer vision and beyond. Even simple yet innovative changes in approach can yield substantial improvements in computational efficiency and performance in complex tasks.
In conclusion, the research conducted by UC Berkeley and UCSF researchers on Cross-Attention Masked Autoencoders (CrossMAE) has paved the way for a leap in efficient visual data processing. By focusing on cross-attention and adopting a partial reconstruction strategy, CrossMAE offers a groundbreaking alternative that combines efficiency and effectiveness. This research has profound implications for computer vision and holds promise for advancements in various domains that rely on visual data processing.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰