NVIDIA Introduces RankRAG: A Groundbreaking Framework That Instruction-Tunes a Single LLM for Superior Context Ranking and Answer Generation
Introduction
Artificial Intelligence (AI) has been growing exponentially during the recent years, giving the rise to the large language models (LLMs) like GPT-4 or Llama which have brought about a revolution in processing natural languages. However, these models that are capable of processing vast corpus usually find it challenging to process huge amounts of context efficiently resulting in inaccurate responses. Given this backdrop, NVIDIA has come up with RankRAG which is a fresh methodology for tuning one single LLM to address both context rank and answer generation. Such an innovation will put the large language models into optimal performance levels when it comes to retrieval-augmented generation (RAG) task.
What is RankRAG?
RankRAG is a novel framework that instructs an LLM to perform dual tasks: answer generation and context ranking. Unlike traditional RAG pipelines that divide these tasks, RankRAG brings them together, yielding more efficient and precise results.
How Does RankRAG Work?
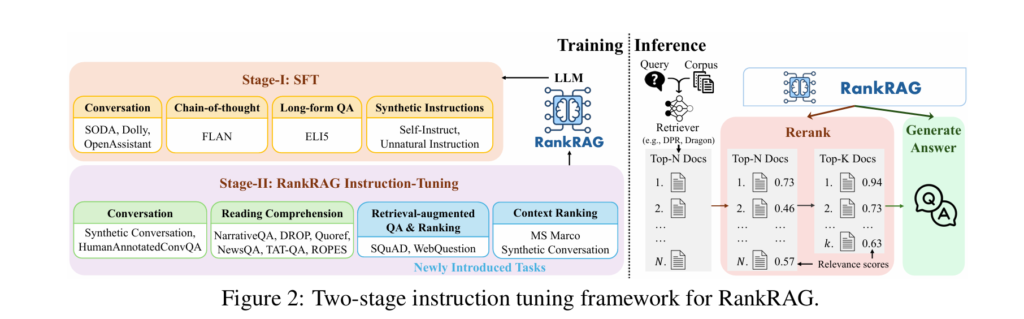
1. Two-Stage Training Process:
- Stage I
Supervised Fine-Tuning (SFT) – During this phase, the LLM is fine-tuned on a mix of high-quality datasets for instructional following purposes, which in turn assists it in being able to understand and follow instructions more effectively.
- Stage II
Unified Instruction-Tuning for Ranking and Generation – This stage involves training the LLM to ranking contexts and generating answers concurrently, with the training dataset being a hybrid of context-rich QA, retrieval-augmented QA and ranking datasets, which help in optimizing the LLM’s capacity to disregard less-pertinent contexts and concentrate more on the relevant ones.
2. Retrieve-Rerank-Generate Pipeline:
- Retrieve – The retriever fetches the top-N contexts from a corpus based on a given question.
- Rerank – The RankRAG model then reorders the material, preserving only the most important ones among the top k
- Generate – The LLM then generates the final answer based on these refined top-k contexts.
Benefits of RankRAG
- Improved Accuracy – By combining context ranking and answer generation, RankRAG dramatically enhances the accuracy of generated responses, outperforming GPT4, GPT4-turbo, ChatQA-1.5 among existing models on multiple benchmarks.
- Efficiency – Although RankRAG includes an extra reranking step, it remains efficient and requires minimal additional data or training time, making it a practical choice for improving LLM performance.
- Versatility – Given its dual-purpose training model, RankRAG is designed to be used in a variety of tasks and fields. In fact, it has shown outstanding results when used for general-purpose as well as for biomedical RAG tasks without additional domain-specific fine-tuning.
Experimental Results
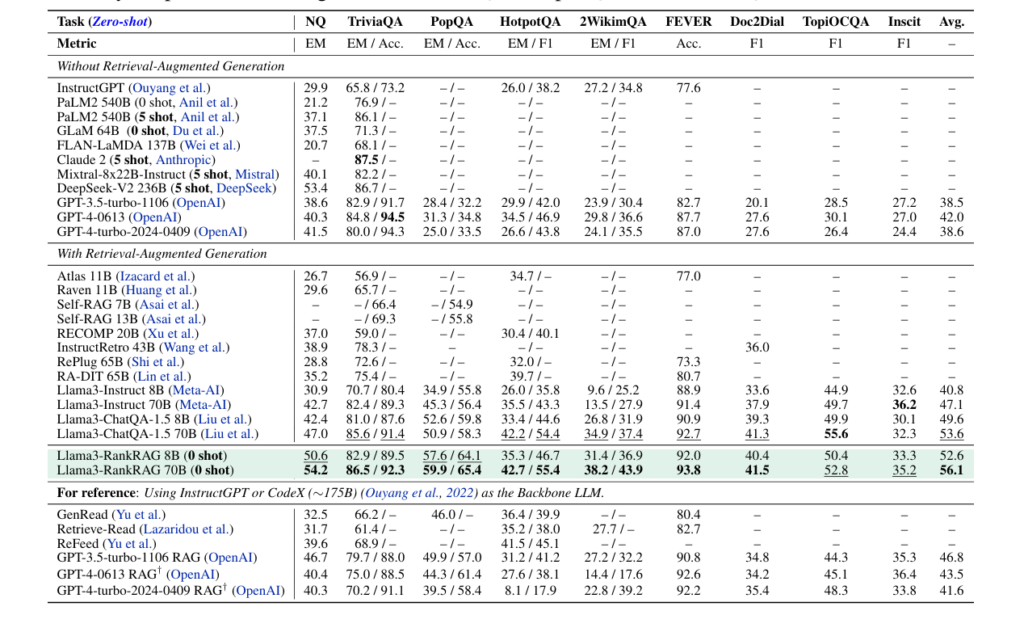
RankRAG has been fully tested against strong baselines and has performed consistently better. Here are the keynotes –
Open-Domain QA (OpenQA) Tasks –
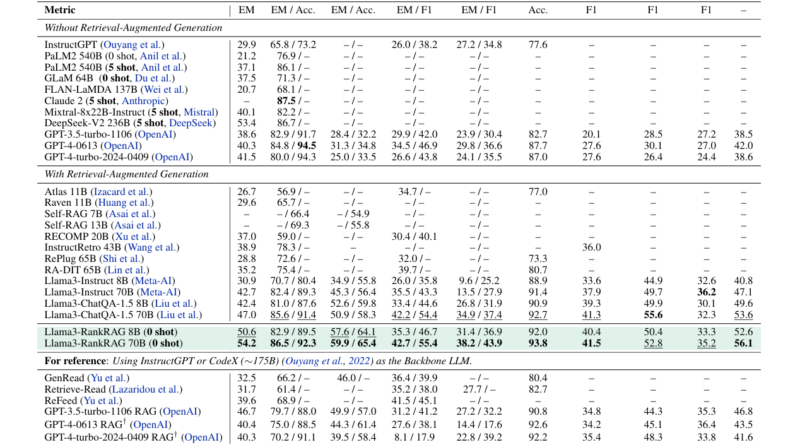
Datasets like NQ (Natural Questions), TriviaQA, PopQA, HotpotQA, and 2WikimQA were used to evaluate RankRAG. For example, RankRAG-70B achieved 54.2 Exact Match (EM) on the NQ dataset thereby outperforming Llama3-ChatQA-1.5-70B which obtained 47.0. RankRAG-70B had an accuracy of 92.3 but Llama3-ChatQA-1.5-70B was slightly lesser at 85.6/91.4 in TriviaQA.
Fact Verification –
Llama3-ChatQA-1.5-70B achieved 91.7% accuracy while RankRAG-70B scored 91.9% in the FEVER dataset concerning fact verification.
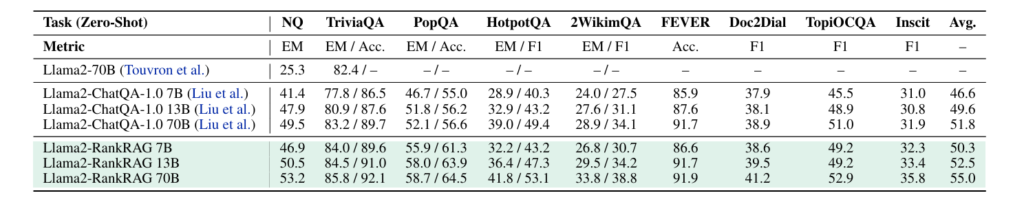
Conversational QA (ConvQA) –
RankRAG was tested on Doc2Dial, TopiOCQA, and INSCIT datasets. Where, on TopiOCQA, RankRAG-70B achieved an F1 score of 52.8, higher than the 49.9 scored by Llama3-ChatQA-1.5-70B.

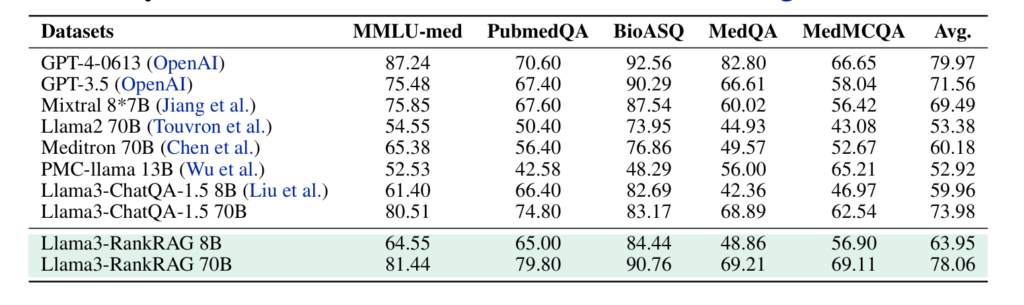
Biomedical Domain –
RankRAG was able to compete with GPT-4 on some of the biomedical domain’s five RAG benchmarks even without any further adaptation. For instance, RankRAG-70B was rated 79.8 against GPT’s 70.6 on PubMedQA dataset. Similarly, RankRAG-70B scored higher than GPT-4 by getting a score of 90.8 against GPT-4 which scored 92.6 on BioASQ dataset.
Conclusion
RankRAG denotes a key improvement in terms of LLMs and augmented generation of retrieval. It handles fundamental drawbacks in earlier RAG pipelines by fine-tuning a solitary LLM to rank context as well as generate an answer, which leads to responses that are more accurate and take less time. NVIDIA’s RankRAG is on the verge of creating a new norm concerning how to develop and utilize big language models.
FAQs
1. Can RankRAG be applied to specialized domains?
Indeed, it is highly versatile — adaptable to various domains and applications. So far, it has demonstrated such great capabilities across general domain and specialized biomedical genres for RAG without the need for any additional fine-tuning.
2. What benchmarks has RankRAG been tested on?
RankRAG has been experimented on nine benchmarks which are general knowledge oriented and have a lot of knowledge as well as five RAG benchmarks from the field of medicine. In all these tests, it always performs better than Llama3-ChatQA-1.5 and GPT-4 which are considered to be strong baselines.
3. How efficient is RankRAG compared to other models?
Despite adding a reranking step, RankRAG remains highly efficient. It requires minimal additional training time and data, making it a practical solution for enhancing LLM performance.
4. What makes RankRAG different from traditional RAG pipelines?
The traditional RAG pipelines typically separate context ranking and answer generation tasks, which can lead to inefficiencies and inaccuracies. RankRAG connects these tasks in a single LLM thereby increasing efficiency and accuracy.
5. How does RankRAG ensure the high recall of relevant contents?
RankRAG’s instruction-tuning process includes context-rich QA, retrieval-augmented QA, and ranking datasets. This enhances the LLM’s ability to filter out irrelevant contexts and ensure high recall of relevant contents during both retrieval and generation phases.
Got an incredible AI tool or app? Let’s make it shine! Contact us now to get featured and reach a wider audience.
Explore 3600+ latest AI tools at AI Toolhouse 🚀. Don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Read our other blogs on AI Tools 😁
If you like our work, you will love our Newsletter 📰