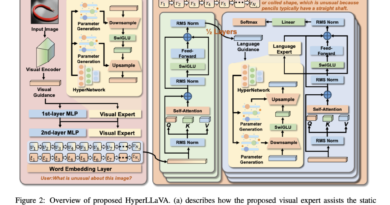
Consistency Large Language Models (CLLMs): A New Family of LLMs Specialized for the Jacobi Decoding Method for Latency Reduction
Artificial Intelligence (AI) has made significant advancements in recent years, with large language models (LLMs) like GPT-4, LLaMA, and PaLM pushing the boundaries of what is possible. However, one of the challenges faced by LLMs is the latency involved in generating responses. This latency can impact user experience and the overall quality of service. To address this issue, researchers have proposed a new family of LLMs called Consistency Large Language Models (CLLMs), which are specialized for the Jacobi decoding method for latency reduction.
The traditional autoregressive (AR) paradigm used by LLMs generates one token at a time, with the attention mechanism relying on previous token states to generate the next token. This sequential generation process can result in high latency, especially when producing longer responses. To overcome this, researchers have explored various methods to improve LLM inference efficiency. One such method is LLM distillation, which uses knowledge distillation (KD) techniques to create smaller models that can replace larger ones. However, traditional KD methods have proven to be less effective for LLMs.

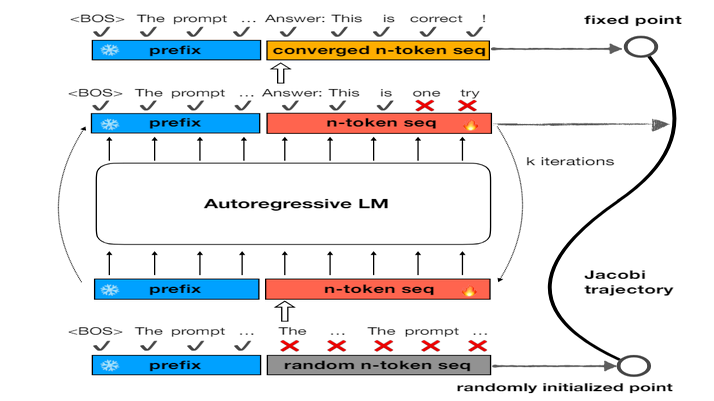
In their research, the team from Shanghai Jiao University and the University of California proposed the use of CLLMs as a specialized solution for the Jacobi decoding method. The Jacobi decoding method is a technique inspired by numerical methods for solving systems of equations. It improves inference efficiency by allowing correct predictions to be made for multiple consecutive tokens in a single forward pass, reducing the overall latency involved.
CLLMs have several advantages over traditional methods such as speculative decoding and Medusa. Unlike other methods, CLLMs do not require additional memory for adjusting auxiliary model components. This makes CLLMs a more efficient and cost-effective solution for reducing latency.
One of the key factors contributing to the speed-up achieved by CLLMs is fast forwarding. Fast forwarding allows correct predictions to be made for multiple consecutive tokens in a single forward pass. This significantly reduces the number of forward passes required to generate a response, leading to a considerable decrease in latency.
Another factor that contributes to the efficiency of CLLMs is the concept of stationary tokens. Stationary tokens are tokens that show correct predictions and do not change through subsequent iterations, even if they are preceded by inaccurate tokens. By identifying and utilizing stationary tokens, CLLMs can further optimize the decoding process.
To evaluate the performance and inference speedup of CLLMs, the researchers conducted experiments on multiple tasks and benchmarks. CLLMs showed outstanding performance compared to state-of-the-art (SOTA) baselines on domain-specific tasks such as GSM8K, CodeSearchNet Python, and Spider. They achieved a speedup of 2.4× to 3.4× using Jacobi decoding without any significant loss in accuracy.
In addition to domain-specific benchmarks, CLLMs also performed well on open-domain benchmarks like MT-bench. They achieved a speedup of 2.4× on ShareGPT while maintaining SOTA performance with a score of 6.4. These results demonstrate the effectiveness of CLLMs in reducing latency without compromising the quality of responses.
The introduction of CLLMs has simplified the architecture design and reduced complexity. Instead of managing two different models in a single system, CLLMs are directly adapted from a target pre-trained LLM. This direct adaptation allows for seamless integration and improves overall efficiency.
In conclusion, CLLMs are a new family of LLMs specialized for the Jacobi decoding method for latency reduction . By leveraging fast forwarding and stationary tokens, CLLMs can achieve significant speedup in inference without sacrificing accuracy. The experiments conducted on various benchmarks demonstrate the effectiveness of CLLMs in reducing latency and improving overall performance. With the continued development of CLLMs and other specialized LLMs, we can expect further advancements in AI-driven applications and services.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
If you like our work, you will love our Newsletter 📰