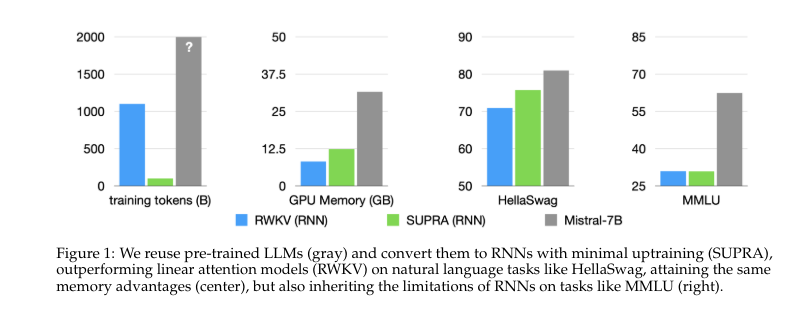
SUPRA: Toyota’s Innovative Methodology Combining Transformers and RNNs for NLP
In the field of natural language processing (NLP), transformer models have revolutionized the way we process and understand textual data. These models, with their attention mechanisms and self-attention layers, have achieved remarkable performance across a wide range of NLP tasks. However, they suffer from high memory requirements and computational costs, making them less practical for applications that involve long-context work. Addressing this challenge, researchers from the Toyota Research Institute have introduced a novel methodology called SUPRA (Scalable UPtraining for Recurrent Attention), which enhances transformer efficiency by leveraging recurrent neural networks (RNNs).
The Challenge of Transformer Models
Transformer models have undoubtedly contributed to the significant advancements in NLP. However, their high memory requirements and computational costs limit their practicality in certain contexts. These limitations have motivated researchers to explore more efficient alternatives that can maintain high performance while reducing resource consumption.
The memory and processing requirements of transformer models have been a persistent challenge. Although these models excel at NLP tasks, they could be more widely applicable if they were less computationally expensive. Finding a solution to this problem would significantly increase the usability and accessibility of modern NLP technology in various applications.
Exploring Efficient Alternatives
To address the efficiency challenge of transformer models, researchers have explored various alternatives. Linear Transformers aim to improve efficiency over softmax transformers, while models like RWKV and RetNet incorporate linear attention mechanisms to achieve competitive performance. State-space models such as H3 and Hyena integrate recurrent and convolutional networks to handle long-sequence tasks. Other methods, including Performers, Cosformer, and LUNA, focus on enhancing transformer efficiency through innovative approaches. The Griffin model combines sliding window and linear attention techniques to achieve better results.
Introducing SUPRA: Combining Transformers and RNNs
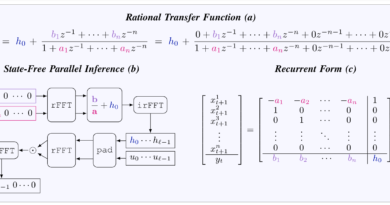
The Toyota Research Institute’s breakthrough AI paper introduces SUPRA, a methodology that enhances transformer efficiency by converting pre-trained transformers into recurrent neural networks (RNNs). SUPRA leverages the high-quality pre-training data from transformers while employing a linearization technique that replaces softmax normalization with GroupNorm. This unique approach combines the strengths of transformers and RNNs, achieving competitive performance with reduced computational cost.
The SUPRA Methodology and Process
The SUPRA methodology involves uptraining transformers such as Llama2 and Mistral-7B. The process replaces softmax normalization with GroupNorm and includes a small multi-layer perceptron (MLP) for projecting queries and keys. The models were trained using the RefinedWeb dataset, which consists of an impressive 1.2 trillion tokens. Training and fine-tuning were performed using a modified version of OpenLM, and evaluations were conducted with the Eleuther evaluation harness on standard NLU benchmarks.
Competitive Performance and Results
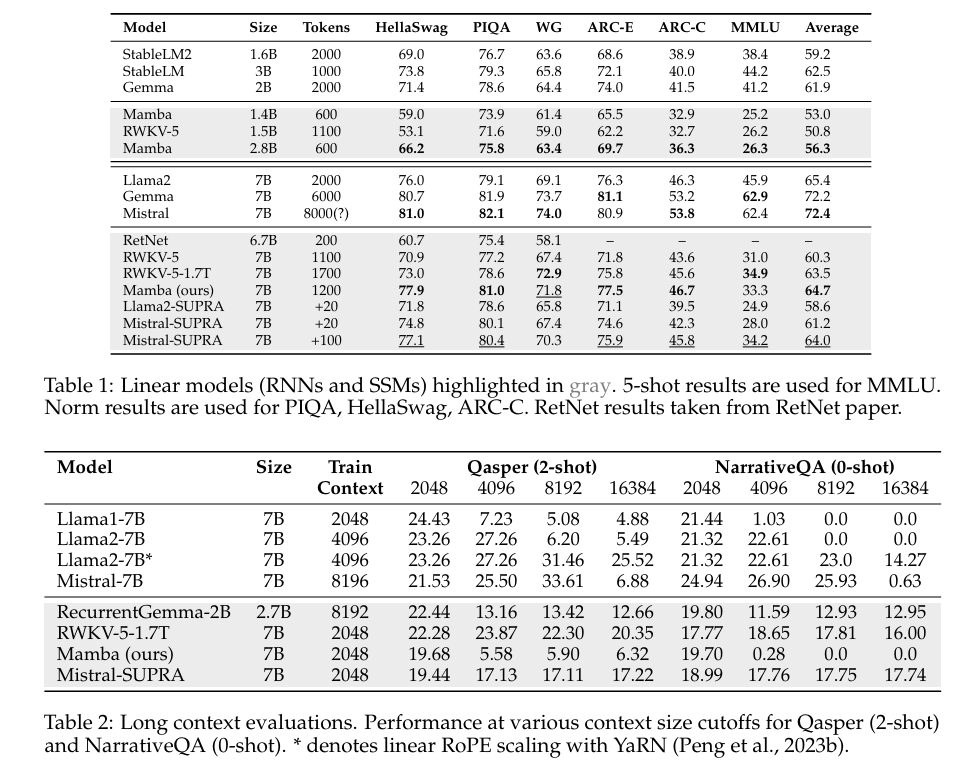
The SUPRA method has shown competitive performance on various benchmarks. On the HellaSwag benchmark, it outperformed RWKV and RetNet, achieving a score of 77.9 compared to 70.9 and 73.0, respectively. The model also demonstrated strong results on other tasks, with scores of 76.3 on ARC-E, 79.1 on ARC-C, and 46.3 on MMLU. Notably, SUPRA achieved these results with significantly less training data, with only 20 billion tokens required for training. While there may be some performance drops in long-context tasks, SUPRA maintains robust results within its training context length.
Implications and Future Directions
The introduction of SUPRA opens up exciting possibilities for more efficient and cost-effective NLP models. By converting pre-trained transformers into efficient RNNs, SUPRA addresses the high computational costs associated with traditional transformers. The replacement of softmax normalization with GroupNorm, coupled with the use of a small MLP, allows SUPRA models to achieve competitive performance on benchmarks like HellaSwag and ARC-C with significantly reduced training data. This research paves the way for more accessible and scalable advanced language processing technologies.
In conclusion, the AI paper by the Toyota Research Institute introduces SUPRA, a methodology that enhances transformer efficiency with recurrent neural networks. By combining the strengths of transformers and RNNs, SUPRA achieves competitive performance while reducing computational costs. This breakthrough research highlights the potential for scalable and cost-effective NLP models, making advanced language processing technologies more accessible to a wide range of applications and industries.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
If you like our work, you will love our Newsletter 📰