FinTextQA: A Game-Changer for Long-Form Question Answering in Finance
In the era of artificial intelligence (AI) and data-driven decision making, question-answering (QA) systems play a crucial role in various domains. One such domain is finance, where accurate and comprehensive answers to complex financial questions are essential. To address the need for a specialized dataset for long-form question answering (LFQA) in the financial domain, researchers from HSBC Lab, Hong Kong University of Science and Technology (Guangzhou), and Harvard University have introduced FinTextQA.
The Importance of LFQA in Finance
The financial domain is characterized by its complexity, domain-specific terminology, market uncertainty, and decision-making processes. Traditional financial QA systems, which heavily rely on numerical calculations and sentiment analysis, often struggle to handle the diversity and complexity of open-domain questions. Long-form question answering scenarios have gained significance in the financial domain due to the complex tasks involved, such as information retrieval, summarization, data analysis, comprehension, and reasoning.
Existing LFQA Datasets and the Gap in the Market
While there are several LFQA datasets available in the public domain, such as ELI5, WikiHowQA, and WebCPM, none of them are specifically tailored to the financial sector. This creates a significant gap in the market, as complex financial questions often require extensive paragraph-length replies and relevant document retrievals. Existing financial QA standards are not designed to handle the intricacies and specificity of the financial domain.
Introducing FinTextQA: A Dataset Tailored for the Financial Domain
To address the limitations of existing datasets and the need for specialized financial QA systems, the researchers introduced FinTextQA. This dataset comprises 1,262 high-quality question-answer pairs and document contexts selected from textbooks in the financial field and government agencies’ websites. The questions cover a wide range of topics related to general finance, regulation, and policy. Each question-answer pair is carefully curated and attributed to its source, ensuring the dataset’s excellence and reliability.
Benchmarking State-of-the-Art Models Using FinTextQA
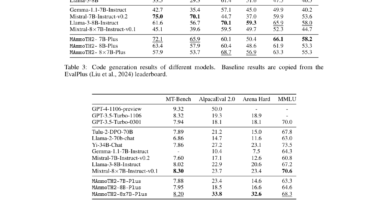
To set standards for future studies and evaluate the effectiveness of existing models in the financial domain, the researchers benchmarked state-of-the-art (SOTA) models using FinTextQA. Many existing LFQA systems rely on pre-trained language models that have been fine-tuned, such as GPT-3.5-turbo, LLaMA2, and Baichuan2. However, these models may not always provide accurate and thorough answers to complex financial inquiries.
To overcome this limitation, the researchers leveraged the RAG framework, which improves language models’ performance and explanation capacities by pre-processing documents in multiple steps and providing the most relevant information for answering questions. This approach enhances the accuracy and comprehensiveness of the answers provided by LFQA models trained on FinTextQA.
The Limitations and Future Directions of FinTextQA
Despite its professional curation and high quality, FinTextQA has a relatively smaller number of question-answer pairs compared to larger AI-generated datasets. This limitation may restrict the applicability of models trained on FinTextQA to more general real-world scenarios. Acquiring high-quality financial data is challenging, and copyright constraints often hinder data sharing. Therefore, future studies should focus on cutting-edge approaches to address data scarcity and explore data augmentation techniques to expand the dataset’s scope.
Additionally, the researchers suggest investigating more sophisticated RAG capabilities and retrieval methods to further enhance the performance of LFQA systems in the financial domain. Expanding the dataset to include more diverse sources, such as financial news articles and research papers, can also contribute to a more comprehensive and representative dataset for financial question answering.
Conclusion
The introduction of FinTextQA represents a significant step forward in improving financial concept understanding and support through LFQA. By providing a specialized dataset tailored for the financial domain and benchmarking state-of-the-art models, FinTextQA enables the development and testing of robust LFQA systems in general finance. The research emphasizes the importance of continuously improving existing approaches to make financial question-answering systems more accurate and easier to understand, ultimately benefiting various stakeholders in the financial domain.
Through the advancements in LFQA and specialized datasets like FinTextQA, financial institutions can enhance their customer service, risk management, and decision-making processes. The ability to accurately and comprehensively answer complex financial questions provides a competitive advantage and contributes to more informed and confident financial decision making.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
If you like our work, you will love our Newsletter 📰