IBM’s 6.48 TB Dataset: Setting New Standards in Legal, High-Quality AI Training Data
IBM has made its Large Language Model (LLM), Granite 13B’s extensive 6.48 TB dataset used for training publicly available––a remarkable transformation. This is a key step in AI and machine learning domain that sets standards for a new level of transparency and availability concerning data. This article will provide information on what this dataset entails, its sources, processing, and enterprise level uses among others.
The Dataset: An Overview
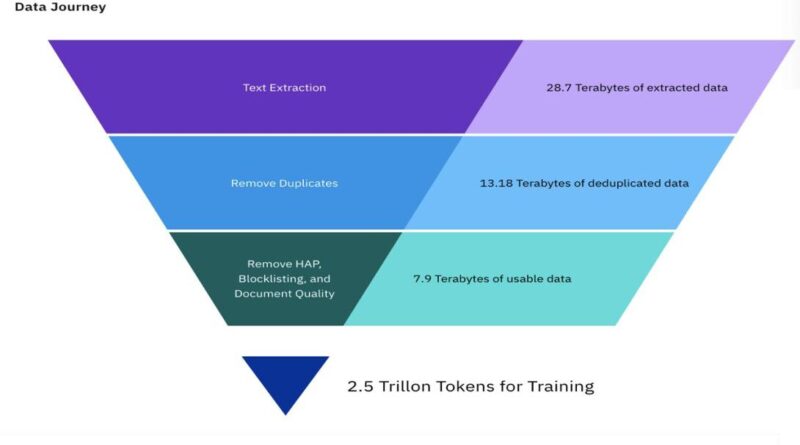
IBM’s dataset originally spans a colossal 6.48 TB, but through meticulous pre-processing, it has been condensed to a more manageable 2.07 TB. This reduction is achieved without compromising the quality and integrity of the data, ensuring it remains robust for training advanced LLMs.
Data Sources
The dataset comprises a rich tapestry of high-quality, legally compliant, and unbiased data from a variety of reputable sources:
- arXiv: A repository of research papers across numerous scientific disciplines.
- Common Crawl: A corpus of web data collected over years, providing a vast array of information.
- Pubmed Central: A free full-text archive of biomedical and life sciences journal literature.
- Wikimedia: A comprehensive collection of content from Wikimedia projects, including Wikipedia.
- GitHub: Repositories and documentation for a multitude of open-source projects and codebases.
- Stack Exchange: A network of question-and-answer sites on diverse topics, including Stack Overflow for programming questions.
- US Patent Office: A comprehensive database of patents and trademarks, providing insights into innovation and technological advancements.
- Project Gutenberg (PG-19): Free e-books with a focus on older works.
These sources ensure a diverse and comprehensive dataset, fostering the development of well-rounded and capable language models.
Pre-Processing and Data Quality
IBM’s focus on quality is shown by their strict preprocessing methods. They filter raw data hard enough to eliminate interference, retaining only the useful one. At the same time, this method increases dataset’s efficiency while cutting down its size to 2.07 TB which makes it easier for other investigations.
The Granite Models
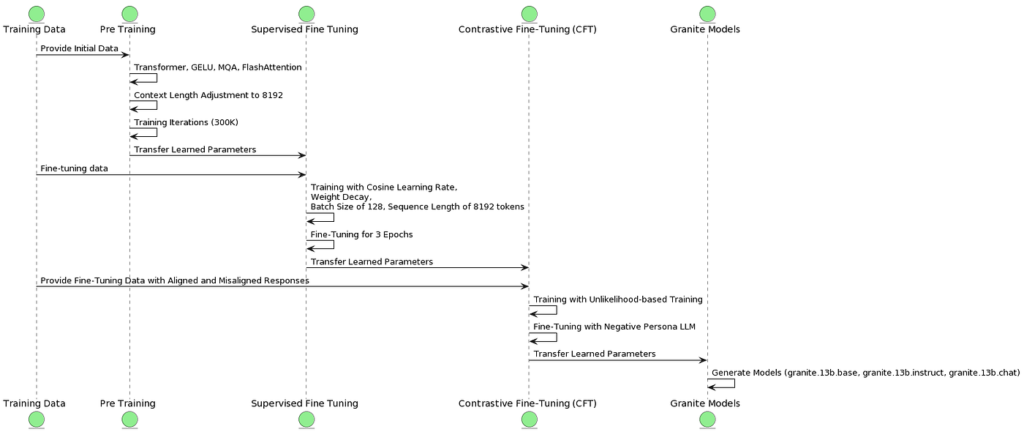
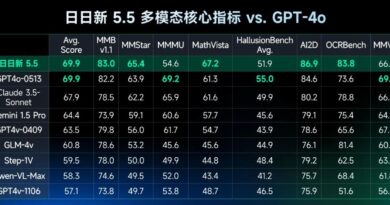
IBM has introduced four variations of the Granite 13B model with the dataset available. These models have undergone thorough testing, performing consistently well with different benchmarks compared to others within their category. The quality and endurance of the database are illustrated articulately by this scenario as well as the supremacy of IBM in constructing AI models.
Enterprise Applications
IBM’s dataset is particularly geared towards enterprise use cases, offering unparalleled opportunities for businesses to leverage advanced AI technologies. The dataset’s diverse and comprehensive nature makes it ideal for developing AI solutions tailored to various industry needs, from healthcare to finance and beyond.
Implications for the AI Community
The AI community is celebrating the release of this dataset, as it ushers in a new era of openness as well as accountability as far as information is concerned. IBM has made it available online for anyone to use, thus fostering open innovation that bases itself on the belief that little is impossible in this field. This basically means that there will be increased participation of people who can further develop ideas through building upon them in order to push the boundaries of what is possible with AI.
Conclusion
IBM’s release of its 6.48 TB LLM training dataset is a landmark moment in the field of AI. It not only provides a rich resource for developing advanced language models but also exemplifies a commitment to transparency and collaboration. As the AI community continues to evolve, such initiatives will play a crucial role in driving innovation and unlocking new potentials.
Got an incredible AI tool or app? Let’s make it shine! Contact us now to get featured and reach a wider audience.
Explore 3600+ latest AI tools at AI Toolhouse 🚀. Don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Read our other blogs on AI Tools 😁
If you like our work, you will love our Newsletter 📰