From Few-Shot to Many-Shot: Improving Multimodal Foundation Models in AI
In the world of artificial intelligence (AI) research, there is a constant quest to improve the performance of multimodal foundation models. These models, which combine text and other types of data such as images or audio, have shown great promise in various applications. A recent AI paper from Stanford University dives deep into this topic, evaluating the performance of multimodal foundation models as they scale from few-shot to many-shot-in-context learning (ICL).
Introduction to Multimodal Foundation Models
Multimodal foundation models are advanced AI models that can process and understand multiple types of data simultaneously. These models have shown exceptional capabilities in tasks such as image captioning, text-to-image synthesis, and more. By combining different modalities of data, multimodal models can learn rich representations that capture the relationships between different types of information.
The Power of In-Context Learning (ICL)
Incorporating in-context learning (ICL) into large language models (LLMs) and large multimodal models (LMMs) has been shown to enhance their performance without requiring parameter updates. ICL refers to the process of providing demonstrating examples to the model during inference, which helps improve its understanding and generation capabilities. With ICL, the model can benefit from context-specific information and produce more relevant and accurate outputs.
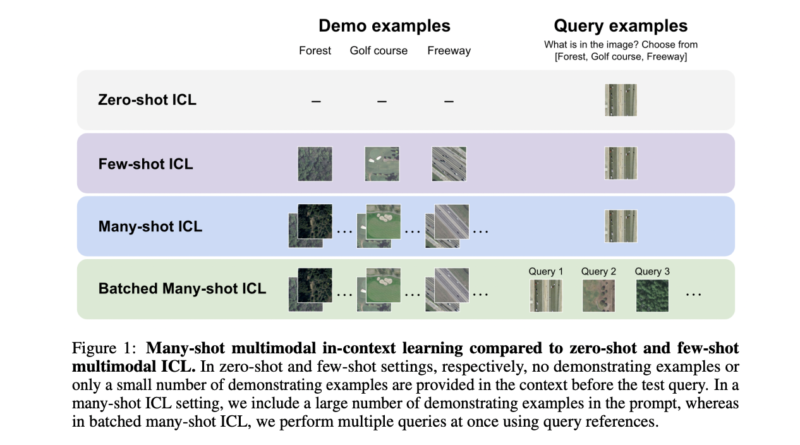
Scaling from Few-Shot to Many-Shot-In-Context Learning
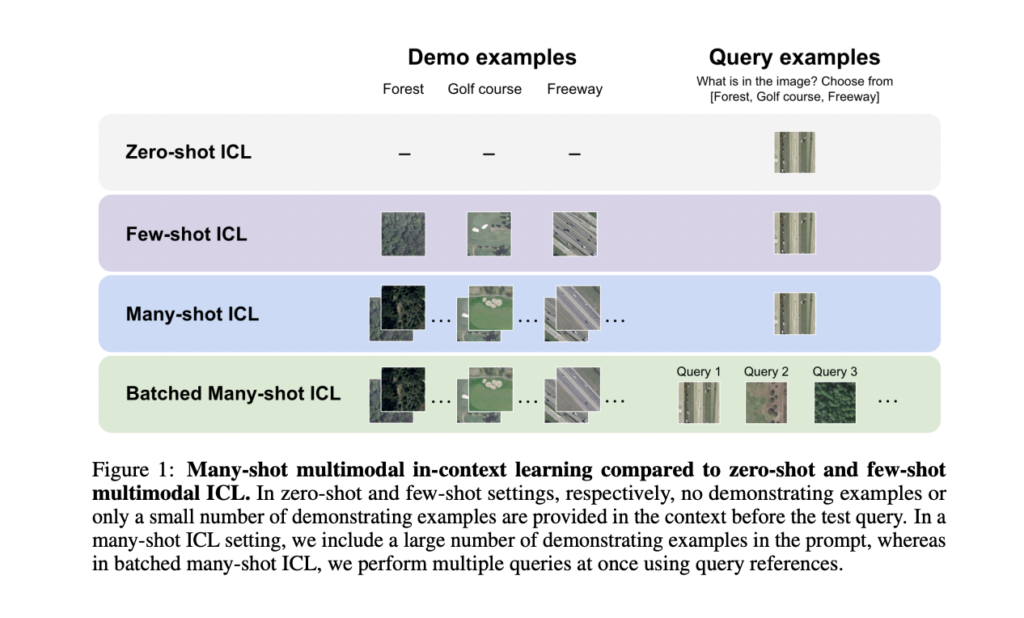
The recent AI paper from Stanford University focuses on evaluating the performance of multimodal foundation models as they scale from few-shot to many-shot ICL. This scaling allows researchers to explore the impact of increasing the number of demonstrating examples, a factor previously limited by context window constraints.
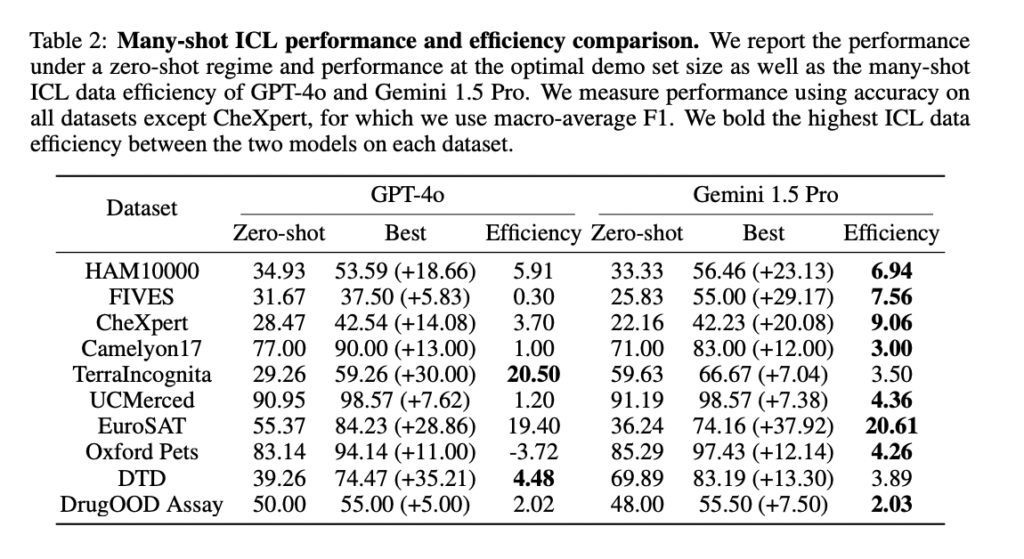
The researchers conducted an extensive array of experiments to assess the efficacy of advanced multimodal foundation models across 10 datasets covering various domains and image classification tasks. They utilized three advanced multimodal models: GPT-4o, GPT-4(V)-Turbo, and Gemini 1.5 Pro. However, the focus was primarily on GPT-4o and Gemini 1.5 Pro due to their superior performance.
Key Findings of the Study
The study yielded several key findings that shed light on the performance of multimodal foundation models scaling from few-shot to many-shot ICL. Here are the highlights:
1. Increased Demonstrating Examples Enhance Model Performance
The researchers found that increasing the number of demonstrating examples significantly enhances the performance of multimodal foundation models. Specifically, Gemini 1.5 Pro demonstrated consistent log-linear improvements compared to GPT-4o.
2. Gemini 1.5 Pro Shows Higher ICL Data Efficiency
Gemini 1.5 Pro, one of the multimodal foundation models evaluated in the study, demonstrated higher ICL data efficiency compared to GPT-4o across most datasets.
3. Combined Queries Enhance Performance in Many-Shot Scenarios
The study also explored the effectiveness of combining multiple queries into a single request. The researchers found that this approach can deliver comparable or even superior performance to individual queries in a many-shot scenario. Furthermore, batched questioning significantly reduces per-example latency and offers a more cost-effective inference process.
4. Batched Querying Improves Zero-Shot Performance
Batched querying, a strategy that involves querying multiple examples simultaneously, was observed to notably enhance performance in zero-shot scenarios. This improvement can be attributed to the domain and class calibrated, as well as self-generated demonstrating examples through autoregressive decoding.
Implications and Future Research
The findings of this study have significant implications for the development and utilization of multimodal foundation models. The ability to scale from few-shot to many-shot ICL opens up possibilities for adapting models quickly to new tasks and domains, without the need for traditional fine-tuning. Future research should focus on investigating the comparative effectiveness and data efficiency of traditional fine-tuning versus many-shot ICL. Additionally, addressing issues like hallucinations and biases in the context of many-shot ICL and batched queries is crucial for model refinement and mitigating biases across diverse sub-groups.
In conclusion, the evaluation of multimodal foundation models scaling from few-shot to many-shot ICL provides valuable insights into their performance and potential applications. The ability to incorporate demonstrating examples and increase the efficiency of inference processes opens up new avenues for AI research and development. As researchers continue to push the boundaries of multimodal models, we can expect further advancements in natural language understanding, image recognition, and other multimodal AI tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
If you like our work, you will love our Newsletter 📰