Google DeepMind Highlights the Performance Gap in AI Alignment Techniques
Recent advancements in artificial intelligence (AI) have led to breakthroughs in various fields, from healthcare to autonomous vehicles. However, ensuring that AI systems align with human values and goals remains a challenge. Aligning AI systems with human values is crucial to prevent unintended consequences and ensure that AI systems act in ways that are beneficial to humanity.
To address this challenge, researchers at Google DeepMind have been conducting AI research to explore the performance gap between online and offline methods for AI alignment. Their study aims to understand the effectiveness of different approaches and determine the optimal methods for aligning AI systems with human values.
The Performance Gap: Online vs. Offline Methods
The performance gap between online and offline methods for AI alignment refers to the difference in performance and efficiency between these two approaches. Online methods involve actively interacting with the AI system, providing feedback and guidance in real-time. Offline methods, on the other hand, rely on pre-existing datasets for aligning AI systems without active online interaction.
Traditionally, reinforcement learning from human feedback (RLHF) has been the standard approach for aligning AI systems, including language models (LLMs). RLHF involves training AI systems using a combination of human preferences and reward signals. However, recent advancements in offline alignment methods have challenged the necessity of on-policy sampling in RLHF.
Offline methods, such as direct preference optimization (DPO) and its variants, have shown practical efficiency and are simpler and cheaper to implement. These methods leverage pre-existing datasets to align AI systems without the need for active online interaction. This raises the question of whether online RL is essential for AI alignment.
Google DeepMind’s Research and Findings
To investigate the performance gap between online and offline methods, researchers from Google DeepMind conducted a series of controlled experiments. Their initial experiments demonstrated that online methods outperformed offline methods, prompting further investigation into the factors contributing to this performance gap.
The researchers found that the quality and coverage of offline data played a crucial role in explaining the performance gap. While offline methods excelled in pairwise classification tasks, they struggled with generation tasks. The performance gap persisted regardless of the type of loss function used and the scaling of the policy networks. This highlights the challenges associated with offline alignment approaches and the importance of on-policy sampling for AI alignment.
The study by Google DeepMind complemented previous work on RLHF by comparing online and offline RLHF algorithms. The researchers identified a persistent performance gap between online and offline methods, even when using different loss functions and scaling policy networks. This suggests that the challenges observed in offline RL extend to RLHF.
Comparing Online and Offline Alignment Methods
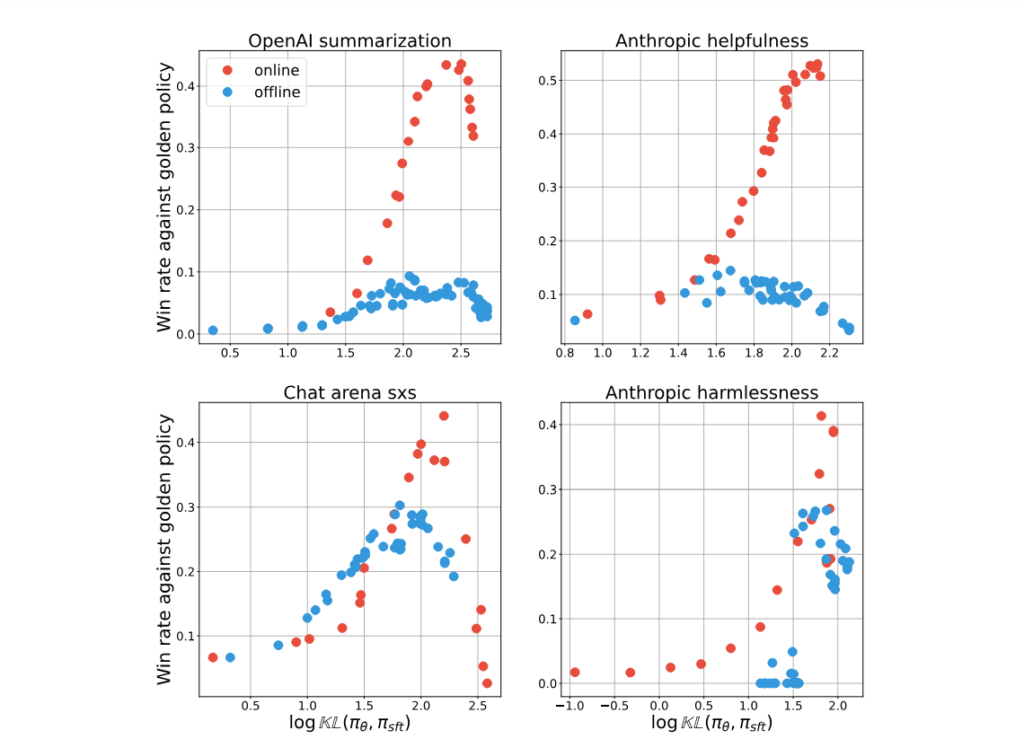
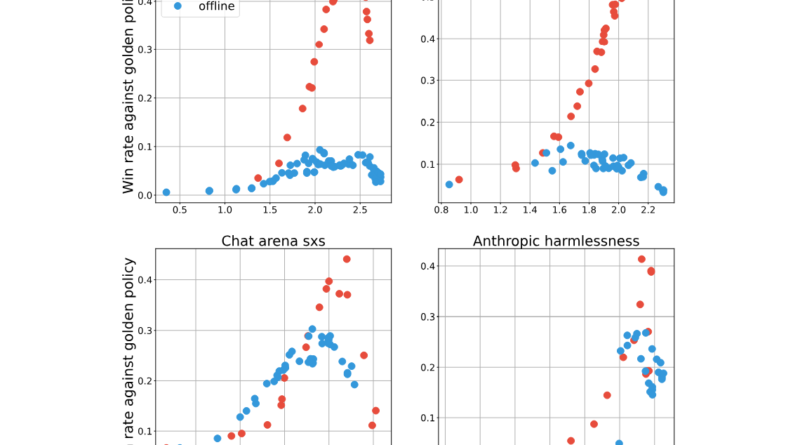
The researchers compared online and offline alignment methods using the Inverse Optimal (IPO) loss across various datasets. The IPO loss involves optimizing the weight of winning responses over losing ones, with differences in sampling processes defining the online and offline methods.
Online algorithms sample responses on-policy, meaning they actively interact with the AI system and provide feedback based on their observations. Offline algorithms, on the other hand, use a fixed dataset and do not have real-time interaction with the AI system.
The experiments revealed that online algorithms achieved better trade-offs between KL divergence (a measure of performance) and performance itself. They utilized the KL budget more efficiently and achieved higher peak performance compared to offline algorithms. The findings suggest that online methods have an advantage in leveraging on-policy data and generating better responses.
Hypotheses to Explain the Performance Gap
The researchers proposed several hypotheses to explain the performance gap between online and offline algorithms. One hypothesis pertains to the classification accuracy of the proxy preference model compared to the policy itself. The proxy preference model tends to achieve higher classification accuracy than the policy when used as a classifier. This difference in classification accuracy may contribute to the observed performance gap between online and offline algorithms. However, further empirical evidence is needed to validate this hypothesis.
The Role of On-Policy Sampling in AI Alignment
In conclusion, the research conducted by Google DeepMind sheds light on the critical role of on-policy sampling in effectively aligning AI systems. The findings highlight the challenges associated with offline alignment approaches and the performance gap between online and offline methods.
While online methods outperform offline methods in current experiments, the researchers acknowledge that offline algorithms can improve by adopting strategies that mimic online learning processes. This opens avenues for further exploration, such as hybrid approaches that combine the strengths of both online and offline methods.
The study also emphasizes the need for deeper theoretical investigations into reinforcement learning for human feedback and the development of effective alignment methods for AI systems. By addressing the performance gap between online and offline methods, researchers can improve the alignment of AI systems with human values and ensure their safe and beneficial deployment.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
If you like our work, you will love our Newsletter 📰