How AgentClinic is Transforming Language Model Evaluations in Healthcare
In the world of Artificial Intelligence (AI), one of the primary goals is to create interactive systems capable of solving diverse problems. Healthcare is an area where AI has shown promise, and language models (LLMs) have emerged as powerful tools within this field. However, evaluating the performance of LLMs in real-world clinical settings can be challenging due to the complexity of clinical tasks. This is where AgentClinic comes in – an innovative benchmark that simulates clinical environments to assess the capabilities of language models in healthcare.
The Challenge of Evaluating Language Models in Healthcare
While LLMs have demonstrated their problem-solving abilities in various domains, their performance in healthcare settings is still limited. Real-world clinical environments involve sequential decision-making, handling uncertainty, and compassionate patient care, which pose unique challenges for language models. Current evaluation methods primarily focus on static multiple-choice questions, failing to capture the dynamic nature of clinical work.
To address this limitation, researchers have developed AgentClinic, an open-source benchmark for simulating clinical environments using language, patient, doctor, and measurement agents. AgentClinic extends previous simulations by incorporating medical exams, such as temperature and blood pressure readings, as well as ordering medical images like MRI and X-ray through dialogue.
Introducing AgentClinic: Simulating Realistic Clinical Interactions
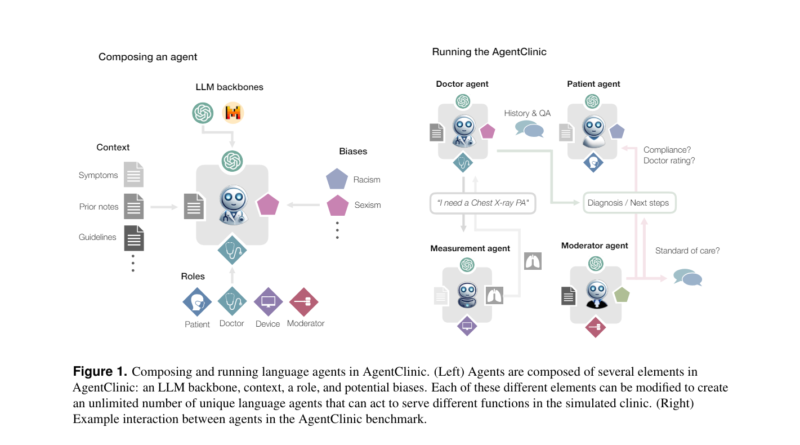
AgentClinic is the brainchild of researchers from Stanford University, Johns Hopkins University, and Hospital Israelita Albert Einstein. It aims to create a benchmark that replicates clinical scenarios and evaluates language models’ performance in a more realistic manner. The benchmark consists of four language agents: patient, doctor, measurement, and moderator.
Each agent has specific roles and unique information, enabling the simulation of realistic clinical interactions. The patient agent provides symptom information without knowing the diagnosis, the measurement agent offers medical readings and test results, the doctor agent evaluates the patient and requests tests, and the moderator assesses the doctor’s diagnosis.
Moreover, AgentClinic incorporates 24 biases that are relevant to clinical settings. These biases impact the diagnostic accuracy and patient-doctor interactions within the simulation. By introducing such biases, AgentClinic aims to evaluate the language models’ ability to handle real-world challenges, including cognitive and implicit biases that can affect decision-making.
Evaluating Language Models in AgentClinic
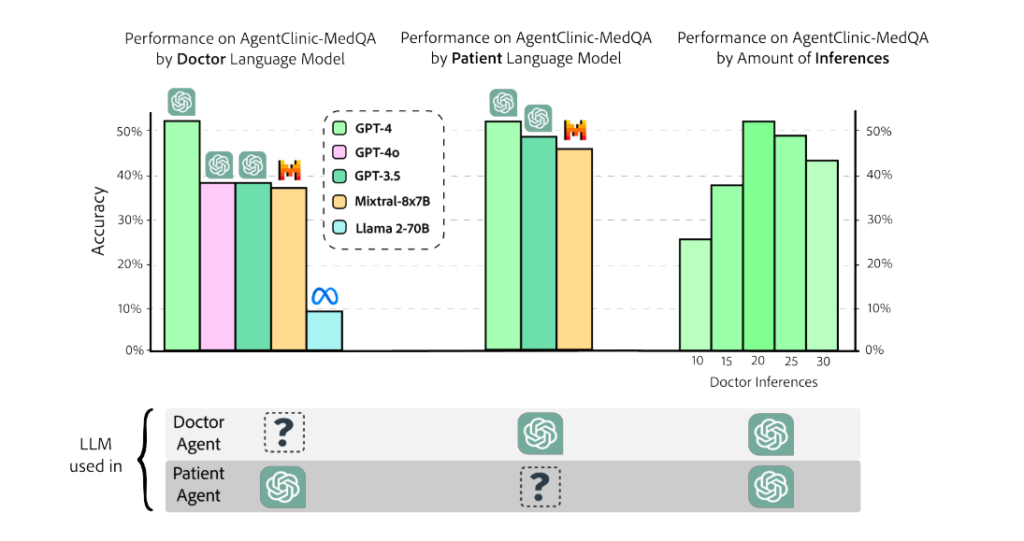

To assess the performance of language models in AgentClinic, researchers evaluated several models, including GPT-4, Mixtral-8x7B, GPT-3.5, and Llama 2 70B-chat. These models acted as doctor agents within the simulation, diagnosing patients through dialogue.
The evaluation results showed that GPT-4 achieved the highest accuracy, reaching 52%. It was followed by GPT-3.5 with 38% accuracy, Mixtral-8x7B with 37%, and Llama 2 70B-chat with 9% accuracy. Interestingly, when compared to the accuracy of these models on traditional benchmarks like MedQA, the predictability of AgentClinic-MedQA accuracy was weak. This finding highlights the need for specialized benchmarks that better capture the complexities of clinical environments.
The Impact of Biases and Interaction Time on Model Accuracy
AgentClinic’s evaluation also shed light on the impact of biases and interaction time on language model accuracy. The highest-performing model, GPT-4, showed reduced accuracy (1.7%-2%) when exposed to cognitive biases. Larger reductions (1.5%) were observed with implicit biases, which affected patient follow-up willingness and confidence. Cross-communication between patient and doctor models was found to improve accuracy.
Furthermore, the evaluation revealed that limited or excessive interaction time between the language models and the simulation had varying effects on accuracy. With only 10 interactions, there was a 27% reduction in accuracy, while N>20 interactions resulted in a 4%-9% reduction in accuracy. These findings highlight the importance of understanding the optimal interaction time to achieve the best performance from language models in clinical environments.
Advancements in Assessing Language Models for Clinical Decision-Making
AgentClinic is a significant step forward in evaluating language models’ capabilities for clinical decision-making. By simulating realistic clinical environments and incorporating specialized language agents, AgentClinic provides a more comprehensive assessment of language models’ performance in healthcare settings.
The benchmark’s focus on biases and interaction time highlights the importance of addressing these factors to improve the accuracy and effectiveness of language models in clinical decision-making. Furthermore, AgentClinic’s open-source nature allows researchers and developers to contribute, collaborate, and refine the benchmark further.
In conclusion, AgentClinic is a pioneering benchmark that simulates clinical environments to assess the performance of language models in healthcare. By introducing realistic scenarios, specialized language agents, and biases, AgentClinic provides a more accurate evaluation of language models’ capabilities. This benchmark serves as a valuable tool in advancing AI-driven healthcare solutions and improving patient outcomes.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
If you like our work, you will love our Newsletter 📰