Enhancing the Accuracy of Large Language Models with Corrective Retrieval Augmented Generation (CRAG)
In recent years, large language models (LLMs) have made significant strides in natural language processing tasks, exhibiting impressive linguistic capabilities. However, these models often suffer from a critical flaw – the generation of inaccurate or “hallucinated” information. To address this challenge, researchers have developed a groundbreaking methodology called Corrective Retrieval Augmented Generation (CRAG). CRAG aims to enhance the accuracy and reliability of LLMs by fortifying the generation process against the pitfalls of inaccurate retrieval.
The Challenge of Inaccurate Generation
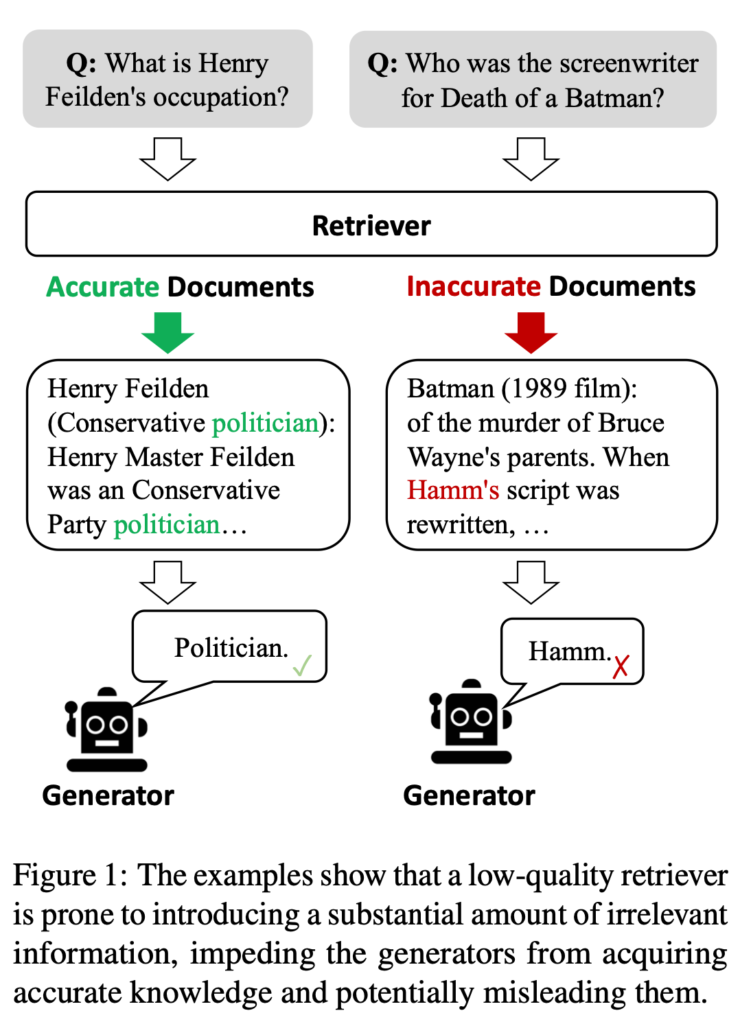
Large language models generate text based on patterns and knowledge acquired during training. While this approach enables them to produce coherent and contextually relevant content, it also introduces the risk of generating incorrect or nonsensical information. This issue becomes more pronounced when LLMs rely solely on their internal knowledge bases, which may not always align with real-world facts.
🔥Explore 3500+ AI Tools and 2000+ GPTs at AI Toolhouse
The concept of retrieval-augmented generation (RAG) was introduced as a solution to this problem. RAG integrates external, relevant knowledge into the generation process to improve the accuracy of LLMs. However, the success of RAG heavily depends on the accuracy and relevance of the retrieved documents. If the retrieval process fails to identify suitable knowledge sources, it can introduce inaccuracies or irrelevant information into the generative process.
Introducing Corrective Retrieval Augmented Generation (CRAG)
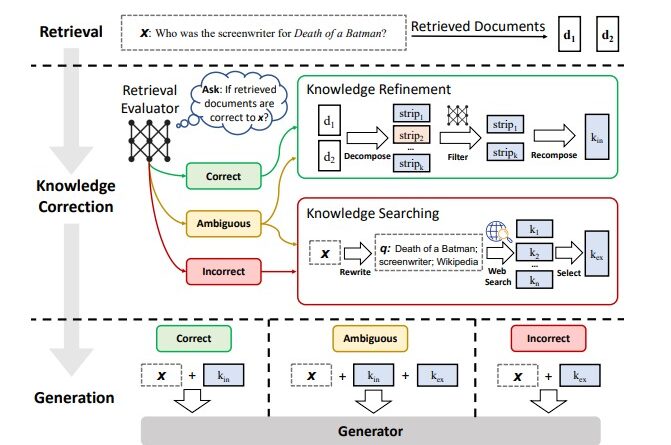
CRAG addresses the limitations of RAG by introducing a corrective mechanism that evaluates the quality of retrieved documents. At its core, CRAG includes a lightweight retrieval evaluator, which assesses the relevance and reliability of the retrieved documents for a given query. This evaluator plays a crucial role in guiding the knowledge retrieval actions, ultimately enhancing the robustness and accuracy of the generated content.
The novelty of CRAG lies in its dynamic approach to document retrieval. When the retrieval evaluator deems the retrieved documents suboptimal, CRAG doesn’t settle for mere acknowledgment. Instead, it employs a sophisticated decompose-recompose algorithm that selectively focuses on the core information while discarding irrelevant details. This ensures that only the most relevant and accurate knowledge is integrated into the generation process.
Furthermore, CRAG leverages the vastness of the web by utilizing large-scale searches to augment its knowledge base beyond static, limited corpora. This approach broadens the spectrum of retrieved information and enriches the quality of the generated content. By tapping into the wealth of internet knowledge, CRAG enhances LLMs’ accuracy and reliability.
Rigorous Testing and Impressive Results
To evaluate the effectiveness of CRAG, researchers conducted rigorous testing across multiple datasets encompassing both short- and long-form generation tasks. The results speak for themselves – CRAG consistently outperformed standard RAG approaches. This improvement demonstrates CRAG’s ability to navigate the complexities of accurate knowledge retrieval and integration.
CRAG showcases its prowess by generating highly relevant and factually accurate responses in short-form question-answering tasks, where precision and accuracy are crucial. Similarly, in long-form biography generation, CRAG demonstrates its capability to provide detailed and accurate information, enhancing the depth and quality of the generated content.
A Leap Forward in Language Model Accuracy
The development of CRAG marks a significant milestone in the pursuit of more reliable and accurate language models. By refining the retrieval process and ensuring high relevance and reliability in the external knowledge it leverages, CRAG addresses the immediate challenge of “hallucinations” in LLMs. It sets a new standard for integrating superficial knowledge into the generation process.
The implications of CRAG’s advancements are far-reaching. The methodology promises to enhance the utility of LLMs across various applications, including automated content creation, sophisticated conversational agents, and more. With CRAG, language models can reliably mirror the richness and accuracy of human knowledge, unlocking new possibilities in natural language processing.
In conclusion, Corrective Retrieval Augmented Generation (CRAG) represents a significant advancement in the accuracy and reliability of large language models. By incorporating a corrective mechanism that evaluates the quality of retrieved documents, CRAG enhances the generation process and mitigates the risks of inaccuracies. This groundbreaking methodology sets a new standard for language model accuracy, paving the way for more reliable and contextually accurate natural language processing applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰