Meet CodeMind: A Machine Learning Framework Designed to Gauge the Code Reasoning Abilities of LLMs
Large Language Models (LLMs) have revolutionized the field of artificial intelligence, particularly in their ability to interpret and generate human language. These models have made significant strides in converting natural language instructions into executable code, showcasing their remarkable potential in machine learning. However, traditional evaluation metrics for LLMs have primarily focused on code synthesis, limiting our understanding of their true reasoning capabilities and the depth of their comprehension of programming logic.
To address this limitation, a team of researchers from the University of Illinois at Urbana-Champaign has introduced CodeMind, a groundbreaking machine learning framework designed to evaluate LLMs’ code reasoning abilities. CodeMind takes a nuanced approach to assessing the proficiency of these models in understanding complex code structures, debugging, and optimization, moving beyond simple code generation benchmarks.
The Need for Code Reasoning Evaluation
Conventional evaluation methods for LLMs often rely on test-passing rates, which provide limited insights into their reasoning abilities. While these models may excel at straightforward code generation tasks, assessing their understanding of programming logic requires more comprehensive evaluation criteria. CodeMind aims to bridge this gap by challenging LLMs to showcase their reasoning skills and comprehension of intricate programming concepts.
Introducing CodeMind: A Comprehensive Evaluation Framework
CodeMind presents three innovative code reasoning tasks: Independent Execution Reasoning (IER), Dependent Execution Reasoning (DER), and Specification Reasoning (SR). These tasks collectively push the boundaries of LLM evaluation by testing models on their ability to generate code based on specifications and understand and reason about code execution, behavior, and adherence to given specifications.


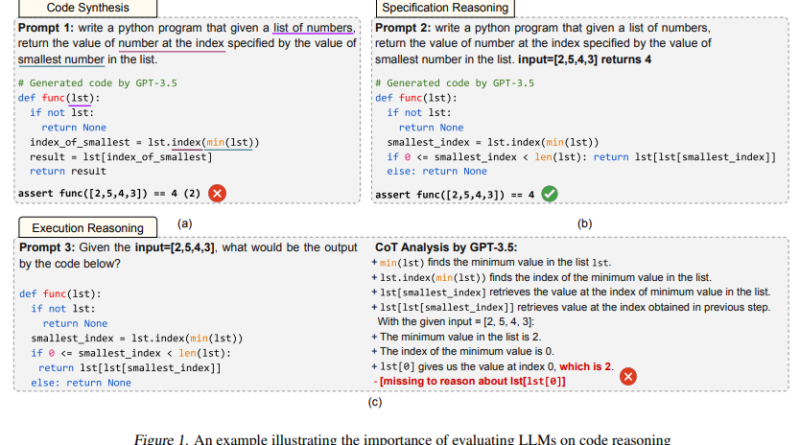
1. Independent Execution Reasoning (IER)
In the IER task, LLMs are evaluated on their capacity to predict the execution outcomes of arbitrary and self-generated code. This task measures the model’s ability to reason about potential errors, logical constructs, and execution paths, showcasing their understanding of programming logic.
2. Dependent Execution Reasoning (DER)
The DER task focuses on evaluating LLMs’ capability to reason about code execution in scenarios involving dependencies and interactions between code segments. This task requires models to analyze complex logic and dependencies, showcasing their ability to reason through intricate programming landscapes.
3. Specification Reasoning (SR)
The SR task assesses LLMs’ ability to implement specified behavior accurately. Models are challenged to generate code that adheres to given specifications and accurately reflects the desired behavior. This task emphasizes the importance of understanding the requirements and translating them into executable code.
Evaluating Leading LLMs with CodeMind
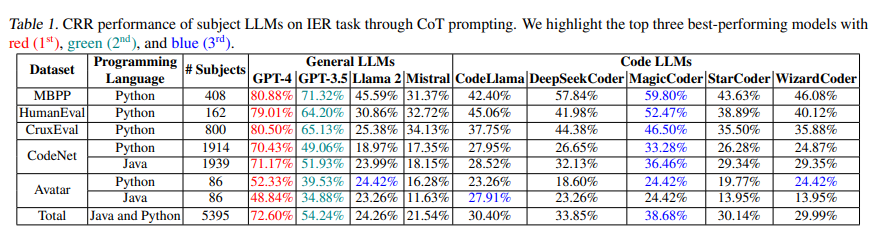
A rigorous evaluation of nine leading LLMs using the CodeMind framework has provided valuable insights into their code reasoning capabilities. The researchers conducted extensive analyses across various programming benchmarks, revealing both strengths and weaknesses in the models’ performance.
The study found that LLMs demonstrated notable proficiency in handling basic code constructs and simple execution paths. However, as the complexity of the tasks escalated, differences in performance became apparent. LLMs struggled with intricate logic, arithmetic operations, and API calls, highlighting the challenges they face in achieving comprehensive understanding and reasoning about code.
Shifting the Focus from Code Generation to Code Reasoning
CodeMind represents a significant shift in the evaluation of LLMs. By emphasizing code reasoning over code generation, this framework provides a more holistic view of models’ strengths and weaknesses in software development tasks. Evaluating LLMs based on their reasoning abilities opens doors for further advancements in developing models with improved code comprehension and reasoning skills.
The Impact of CodeMind in Advancing Artificial Intelligence
CodeMind has profound implications for the field of artificial intelligence. By uncovering the limitations and strengths of LLMs in code reasoning, this framework contributes valuable knowledge to the development of more capable and intelligent models. Understanding the reasoning abilities of LLMs is crucial in enhancing their programming capabilities and enabling them to tackle increasingly complex software development tasks.
The insights gained from CodeMind evaluations pave the way for future advancements, not only in LLMs but also in the broader landscape of machine learning and artificial intelligence. By addressing the gaps in code reasoning evaluation, researchers can refine and improve LLMs, making them more effective and reliable tools for developers and organizations.
Conclusion
CodeMind stands as a groundbreaking machine learning framework designed to gauge the code reasoning abilities of LLMs. By challenging these models to showcase their comprehension of complex programming logic and reasoning skills, CodeMind provides a comprehensive evaluation that surpasses traditional code generation benchmarks.
With the insights gained from CodeMind, researchers can further refine LLMs and advance the field of artificial intelligence. By enhancing models’ programming capabilities and reasoning skills, we can unlock their full potential in software development and enable them to tackle increasingly complex tasks with accuracy and efficiency.
CodeMind represents a significant step towards unleashing the true power of LLMs and shaping the future of artificial intelligence.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰