Enhancing Autoregressive Decoding Efficiency: A Machine Learning Approach by Qualcomm AI Research Using Hybrid Large and Small Language Models
In the rapidly evolving field of Natural Language Processing (NLP), large language models (LLMs) have played a crucial role in pushing the boundaries of what machines can achieve in understanding and generating human language. However, the computational demand for autoregressive decoding in LLMs has posed significant challenges to their efficiency and real-time applicability. To address this issue, researchers from Qualcomm AI Research, the University of Potsdam, and Amsterdam have proposed an innovative hybrid approach that combines large and small language models. This groundbreaking technique aims to optimize the efficiency of autoregressive decoding while maintaining high-performance levels.
The Challenge of Autoregressive Decoding in LLMs
Autoregressive decoding is a critical process in NLP tasks such as machine translation and content summarization. It involves generating each token in a sequence one at a time, conditioned on previously generated tokens. This autoregressive nature makes the decoding process computationally intensive and resource-demanding, limiting its feasibility for real-time applications and devices with limited processing capabilities.


Current Methodologies for Improving Efficiency
Existing methodologies to address the computational intensity of LLMs focus on model compression techniques like pruning, quantization, and parallel decoding strategies. These techniques aim to reduce the size or computational requirements of LLMs but often come with trade-offs in terms of model performance or fail to achieve significant efficiency gains.
Another approach is knowledge distillation, where a smaller model learns from the outputs of a larger model. While this technique can improve efficiency to some extent, it may still fall short in achieving substantial speedups in autoregressive decoding.
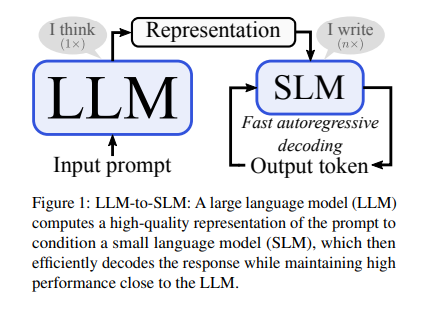
The Hybrid Approach: Combining LLMs and SLMs
The proposed approach by Qualcomm AI Research, the University of Potsdam, and Amsterdam introduces a novel hybrid approach that combines large language models (LLMs) with small language models (SLMs) to enhance autoregressive decoding efficiency.
The hybrid approach leverages the strengths of both LLMs and SLMs. LLMs are known for their comprehensive encoding capabilities, while SLMs offer agility and faster decoding times. By combining these two types of models, the researchers aim to achieve a significant reduction in decoding time without sacrificing performance.
How the Hybrid Approach Works
The LLM-to-SLM method starts by utilizing a pretrained LLM to encode input prompts in parallel. This encoding step generates detailed prompt representations. These representations are then adapted to the embedding space of the SLM using a projector. The adapted representations enable the SLM to generate responses autoregressively, leveraging the prompt information encoded by the LLM. The method ensures seamless integration by replacing or adding LLM representations into SLM embeddings, with a focus on early-stage conditioning to maintain simplicity.
The alignment of sequence lengths is another crucial aspect of the hybrid approach. By using the LLM’s tokenizer, the method ensures that the SLM can accurately interpret the prompt, enabling efficient decoding while maintaining the depth of LLMs.
Achievements and Performance
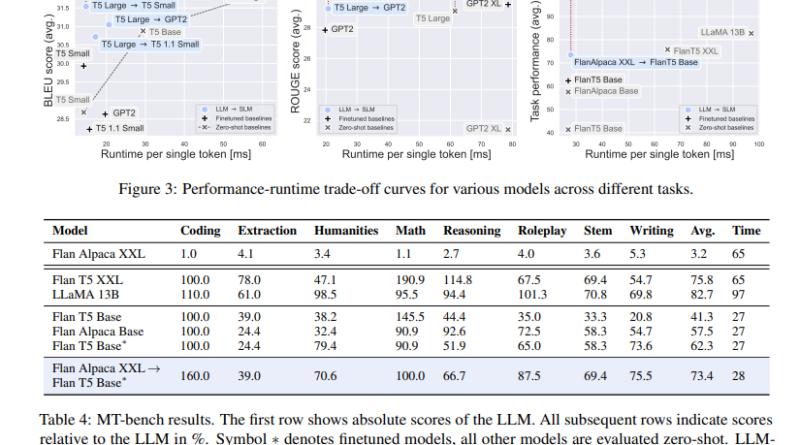
The proposed hybrid approach has achieved substantial speedups of up to 4× compared to using LLMs alone, with minor performance penalties ranging from 1% to 2% for translation and summarization tasks. These speedups demonstrate the efficiency gains made possible by leveraging the hybrid approach.
Compared to using SLMs alone, the LLM-to-SLM approach maintained comparable performance while being 1.5× faster. This performance improvement showcases the effectiveness of the hybrid approach in optimizing autoregressive decoding efficiency.
Future Implications and Advancements
The innovative hybrid approach proposed by Qualcomm AI Research, the University of Potsdam, and Amsterdam has opened new avenues for real-time language processing applications. By combining the comprehensive encoding capabilities of LLMs with the agility of SLMs, researchers have successfully addressed the computational challenges associated with autoregressive decoding.
The findings of this research have significant implications for various NLP applications, including machine translation, content summarization, and dialogue generation. The achieved efficiency gains pave the way for improved real-time performance and the deployment of language models on devices with limited computational resources.
As the field of NLP continues to evolve, further advancements in hybrid approaches and optimization techniques are expected. The proposed method serves as a stepping stone towards more efficient autoregressive decoding in large language models, contributing to the broader goal of enhancing the capabilities of AI-driven language processing systems.
Conclusion
Enhancing autoregressive decoding efficiency is a critical goal in the field of Natural Language Processing. The hybrid approach proposed by Qualcomm AI Research, the University of Potsdam, and Amsterdam represents a significant advancement in optimizing the efficiency of large language models. By combining the strengths of large and small language models, researchers have achieved substantial speedups while maintaining high-performance levels.
The successful integration of LLMs and SLMs opens doors for real-time language processing applications, making AI-driven language models more accessible and efficient. The findings of this research contribute to the continuous progress in NLP and pave the way for future advancements in autoregressive decoding efficiency.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰