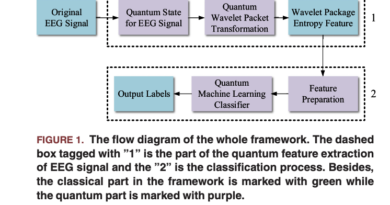
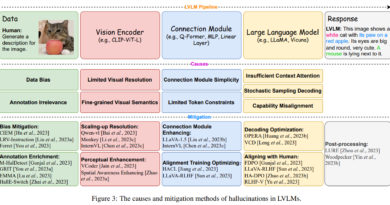
Panda-70M: A Large-Scale Dataset with 70M High-Quality Video-Caption Pairs
In the field of AI and machine learning, the availability of high-quality datasets is crucial for training robust models. One such dataset that has recently gained attention is Panda-70M. This large-scale dataset consists of 70 million video-caption pairs, making it a valuable resource for various tasks such as video captioning, video and text retrieval, and text-to-video generation.
The Challenge of Generating High-Quality Video Captions
Generating accurate and meaningful captions for videos is a challenging task. While there are existing vision-language datasets that provide captions, such as HD-VILA-100M and HowTo100M, they often suffer from limitations like low resolution, misalignment in timing, or insufficiently descriptive captions. These limitations hinder the effectiveness of these datasets for multimodal training.
To address these challenges, researchers from Snap Inc., the University of California, Merced, and the University of Trento collaborated to create Panda-70M. This dataset leverages multimodal inputs, including textual video descriptions, subtitles, and individual video frames, to curate a collection of high-quality video-caption pairs.
The Construction of Panda-70M
To construct the Panda-70M dataset, the researchers curated 3.8 million high-resolution videos from publicly available HD-VILA-100M datasets. These videos were split into semantically consistent video clips, which were then used to fine-tune a fine-grained retrieval model to obtain captions for each video.
In addition to the curated videos, Panda-70M incorporates five base models as teacher models: Video LLaMA, VideoChat, VideoChat Text, BLIP-2, and MiniGPT-4. These models are used to generate captions for the video clips, ensuring a diverse range of captions and high-quality annotations.
Evaluation Metrics and Superiority
To evaluate the performance of Panda-70M, the researchers used established metrics such as BLEU-4, ROGUE-L, METEOR, and CIDEr. The models trained on the Panda-70M dataset consistently outperformed other vision-language datasets on these metrics, demonstrating their superiority in various tasks.
Compared to other vision-language datasets, Panda-70M also proves to be the most efficient. It took an average of 8.5 seconds to process a video of length 166.8Khr, making it a practical choice for large-scale video processing tasks.
Leveraging Multimodal Information
One of the key strengths of Panda-70M is its ability to leverage multimodal information for video captioning and related tasks. By incorporating textual video descriptions, subtitles, and individual video frames, the dataset captures a comprehensive understanding of the video content. This multimodal approach aids in generating more accurate and descriptive captions.
Researchers have also explored integrating the Panda-70M dataset with different models. For example, a familiar framework similar to Video LLaMA has been utilized to derive video representations compatible with LLM. This approach enhances the performance of video captioning models and facilitates other downstream tasks such as video and text retrieval, as well as text-to-video generation.
Limitations and Future Directions
While Panda-70M offers a large-scale dataset with high-quality video-caption pairs, it does have some limitations. One of the limitations is the content diversity within a single video. Because the dataset primarily consists of video clips, it may not capture the full context or narrative of longer videos. Additionally, the average video duration is reduced, which may limit the dataset’s potential for tasks involving longer videos.
In the future, efforts could be made to expand the dataset to include longer videos and enhance the diversity of content representation. This would enable researchers to train models that can handle a wider range of video lengths and capture more complex video narratives.
Conclusion
Panda-70M is a significant contribution to the field of AI and machine learning, providing a large-scale dataset with 70 million high-quality video-caption pairs. By leveraging multimodal information and incorporating base models, Panda-70M enables researchers to train robust models for video captioning, video and text retrieval, and text-to-video generation.
The dataset’s superior performance on evaluation metrics and its efficiency in video processing make it a valuable resource for various applications. While there are limitations regarding content diversity and video duration, Panda-70M sets the stage for future advancements in large-scale video datasets.
With the availability of Panda-70M, researchers and practitioners can continue to push the boundaries of AI and machine learning, leading to more accurate and meaningful video understanding and generation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰