A Breakthrough in Optical Flow Estimation: Introducing a Small and Efficient Model
Optical flow estimation is a fundamental task in computer vision that allows us to predict per-pixel motion between consecutive images. It plays a crucial role in various applications such as action recognition, video interpolation, autonomous navigation, and object tracking systems. Traditionally, the pursuit of higher accuracy in optical flow estimation has led to the development of complex models. However, these models often come with increased computational demands and the need for diverse training data to generalize effectively across different environments.
🔥Explore 3500+ AI Tools and 2000+ GPTs at AI Toolhouse
To address these challenges, a recent AI paper from China proposes a groundbreaking methodology that introduces a small and efficient model for optical flow estimation. This model offers a scalable and effective solution by bridging the gap between model complexity and generalization capability. In this article, we delve into the details of this innovative approach, exploring its unique features and the impact it has on the field of computer vision.
The Power of Spatial Recurrent Encoder Network
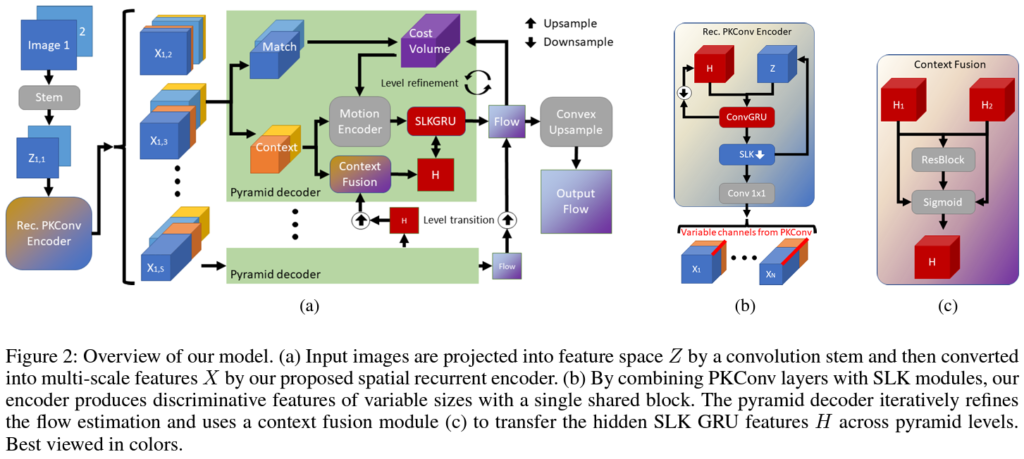
At the heart of this small and efficient optical flow estimation model lies the spatial recurrent encoder network. This network leverages a novel Partial Kernel Convolution (PKConv) mechanism, enabling the model to process features across varying channel counts within a single shared network. By doing so, the model achieves a significant reduction in size and computational demands.
PKConv layers are designed to produce multi-scale features by selectively processing parts of the convolution kernel. This selective processing allows the model to efficiently capture essential details from images while minimizing computational overhead 1. This innovative approach strikes a balance between feature extraction and computational efficiency, paving the way for a more streamlined and powerful optical flow estimation model.
Empowering Contextual Understanding with SLK Modules
To further enhance the model’s ability to understand and predict motion accurately, the researchers introduced Separable Large Kernel (SLK) modules 1. These modules leverage large 1D convolutions to efficiently grasp broad contextual information. By incorporating SLK modules into the model architecture, the researchers have successfully improved the model’s performance on optical flow estimation tasks.
The combination of PKConv and SLK modules creates a unique synergy that enables the model to capture both fine-grained details and contextual information effectively. This architectural design sets a new standard in the field of optical flow estimation, offering a compact yet powerful solution.
Unparalleled Generalization Performance
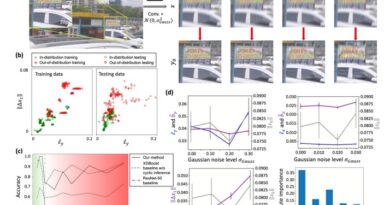
One of the remarkable aspects of this small and efficient model is its exceptional generalization performance. Through empirical evaluations, the researchers demonstrated the model’s robustness and adaptability across various datasets 1. The model achieved unparalleled performance on the Spring benchmark, surpassing existing methods without the need for dataset-specific tuning. This achievement showcases the model’s capacity to deliver accurate optical flow predictions in diverse and challenging scenarios.
In addition to its impressive generalization performance, the model’s efficiency is also noteworthy. Despite its compact size, the model outperforms traditional methods in terms of computational cost and memory requirements. This makes it an ideal solution for applications where resources are limited, opening up possibilities for real-time optical flow estimation in resource-constrained environments.
A Shift in Optical Flow Estimation Paradigm
The introduction of this small and efficient model marks a pivotal shift in optical flow estimation. By challenging the conventional wisdom that higher accuracy necessitates increased model complexity, this research offers a scalable and effective solution to the field. The spatial recurrent encoder network, combined with PKConv and SLK modules, demonstrates that high efficiency and exceptional performance can coexist.
This breakthrough not only revolutionizes optical flow estimation but also paves the way for the development of more advanced computer vision applications. The success of this model encourages future exploration to strike an optimal balance between model complexity and generalization capability.
Conclusion
The AI paper from China proposing a small and efficient model for optical flow estimation introduces a groundbreaking approach to the field of computer vision. By leveraging a spatial recurrent encoder network, Partial Kernel Convolution (PKConv) mechanism, and Separable Large Kernel (SLK) modules, the researchers have created a model that achieves outstanding generalization performance while maintaining a compact size and computational efficiency.
This breakthrough in optical flow estimation challenges the conventional notion that higher accuracy requires increasingly complex models. It opens up new possibilities for real-time optical flow estimation in resource-constrained environments and serves as a stepping stone for developing more advanced computer vision applications.
As we continue to explore the potential of artificial intelligence and machine learning in computer vision, breakthroughs like this small and efficient optical flow estimation model bring us closer to unlocking the full capabilities of this exciting field.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰