CMU Researchers Introduce OWSM v3.1: A Better and Faster Open Whisper-Style Speech Model-Based on E-Branchformer
Speech recognition technology has revolutionized the way we interact with machines, enabling them to understand and process human speech. It has found applications in various fields, from virtual assistants to transcription services. As the demand for accurate and efficient speech recognition continues to grow, researchers are constantly pushing the boundaries of what is possible. One such breakthrough comes from researchers at Carnegie Mellon University (CMU) and Honda Research Institute Japan, who have introduced OWSM v3.1, a better and faster open Whisper-Style Speech Model based on the E-Branchformer architecture.
🔥Explore 3500+ AI Tools and 2000+ GPTs at AI Toolhouse
The Challenge of Speech Recognition
Speech recognition is a complex task that involves capturing and interpreting human speech. It presents several challenges, including variability in speech patterns, accents, intonation, and background noise. To overcome these challenges, researchers have been exploring different methods and architectures to improve the accuracy and efficiency of speech recognition systems.
The Limitations of Transformers
Transformers have been widely used in speech recognition systems due to their effectiveness in handling sequential data. However, they do have certain limitations, particularly in processing speed and handling the nuances of speech. Recognizing and interpreting variations in speech patterns, accents, and dialects is a nuanced task that requires more robust and versatile solutions.
Introducing OWSM v3.1 and the E-Branchformer Architecture
The research team at CMU and Honda Research Institute Japan recognized the limitations of existing speech recognition models and sought to develop a better solution. They introduced OWSM v3.1, an improved and faster open Whisper-Style Speech Model based on the E-Branchformer architecture.
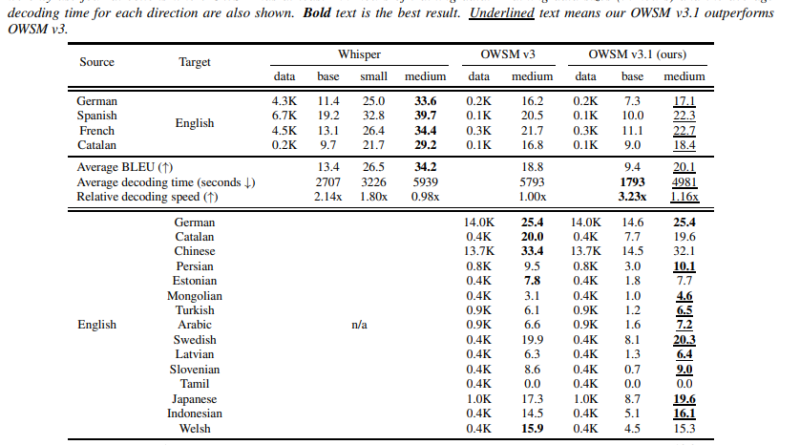
OWSM v3.1 leverages the advancements in speech encoders, particularly the E-Branchformer architecture, to address the challenges of speech recognition. The E-Branchformer architecture demonstrates its effectiveness at a scale of 1B parameters. By employing the E-Branchformer as the encoder, OWSM v3.1 achieves better results and faster inference speed compared to its predecessor, OWSM v3.
The Advantages of OWSM v3.1
OWSM v3.1 offers several advantages over previous speech recognition models. Firstly, it excludes the WSJ training data used in OWSM v3, which had fully uppercased transcripts. This exclusion leads to a significantly lower Word Error Rate (WER) in OWSM v3.1, indicating improved accuracy in transcribing speech.
OWSM v3.1 also outperforms its predecessor in most evaluation conditions. In English-to-X translation, OWSM v3.1 shows improvements in 9 out of 15 directions. While there may be a slight degradation in some directions, the average BLEU score, a metric used to evaluate the quality of machine-translated text, is slightly improved from 13.0 to 13.3 1.
Furthermore, OWSM v3.1 achieves faster inference speed, making it more efficient for real-time applications that require quick and accurate speech recognition.
The Implications and Future of Speech Recognition
The introduction of OWSM v3.1 has significant implications for the field of speech recognition. By leveraging the E-Branchformer architecture, the researchers have improved upon previous models in terms of accuracy and efficiency. This breakthrough sets a new standard for open-source speech recognition solutions.
The open-source nature of OWSM v3.1 allows other researchers and developers to build upon the work and further enhance the technology. The availability of the model and training details fosters transparency and open science, promoting collaboration and driving future advancements in the field.
As speech recognition technology continues to evolve, we can expect further improvements in accuracy, speed, and versatility. This progress will enable the development of more sophisticated applications and services that leverage the power of speech recognition.
In conclusion, CMU researchers, in collaboration with the Honda Research Institute Japan, have introduced OWSM v3.1, a better and faster open Whisper-Style Speech Model based on the E-Branchformer architecture. This model represents a significant advancement in speech recognition technology, addressing the limitations of previous models and achieving improved accuracy and efficiency. By releasing the model and training details publicly, the researchers have contributed to the open-source community, paving the way for further advancements and collaborations in the future.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰