Cosmo: A Revolutionary Open-Source AI Framework for Image and Video Processing
Artificial Intelligence (AI) has made significant strides in recent years, particularly in the field of computer vision. Researchers from Microsoft and the National University of Singapore (NU Singapore) have introduced a groundbreaking open-source AI framework called Cosmo. This framework, meticulously crafted for image and video processing, represents a significant advancement in multimodal data analysis and interpretation.
The Challenge of Multimodal Learning
Multimodal learning involves processing and interpreting diverse data inputs, such as images, videos, and text. Integrating different types of data in AI systems presents unique challenges and opportunities. By enabling machines to understand and analyze various data sources simultaneously, multimodal learning opens doors to a more nuanced understanding of complex information.
One of the key challenges in multimodal learning is effectively integrating and correlating different forms of data, particularly text and visual elements. While Language Models (LMs) have shown proficiency in processing textual inputs, aligning them with visual elements remains a challenge. Existing models often struggle to precisely align text and images or videos, limiting their ability to draw meaningful insights from multimodal data.
Introducing the Cosmo Framework
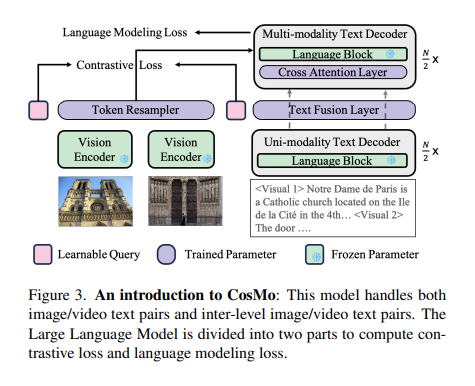
To address the limitations of existing models, researchers from Microsoft and NU Singapore have developed the Cosmo framework. Cosmo, short for Contrastive Streamlined Multimodal Model, offers a novel approach to multimodal data processing.
The Cosmo framework strategically divides a language model into specialized segments dedicated to processing unimodal text and adept multimodal data. This partitioning enhances the model’s efficiency and effectiveness in dealing with diverse data types. Additionally, Cosmo introduces a contrastive loss to the language model, refining its ability to align different forms of data.
The researchers have leveraged the Howto-Interlink7M dataset, a pioneering resource in the field of multimodal learning. This dataset provides detailed annotations of video-text data, addressing the lack of high-quality, long-text video datasets. By utilizing this rich and comprehensive dataset, Cosmo’s performance in tasks involving image-text alignment is significantly improved.

Advancements and Performance
The Cosmo framework has demonstrated remarkable advancements over existing models, particularly in tasks that require precise alignment between textual and visual data. In a specific 4-shot Flickr captioning task, Cosmo’s performance improved from 57.2% to 65.1%. This substantial improvement highlights the framework’s enhanced capability in understanding and processing multimodal data.
Cosmo’s methodology and design have proven to be instrumental in achieving these impressive results. By dividing the language model into specialized segments and incorporating contrastive loss, the framework effectively addresses the challenges of multimodal data processing.
Open-Source and Collaborative Development
One of the key strengths of the Cosmo framework lies in its open-source nature. By making the framework freely available to the community, Microsoft and NU Singapore have fostered collaboration and knowledge sharing in the field of multimodal learning. Researchers and developers worldwide can access and build upon Cosmo, driving further advancements in AI-driven image and video processing.
The open-source approach also allows for the integration of the Cosmo framework into existing AI systems and applications. Developers can leverage the framework’s capabilities to enhance their own projects, enabling more sophisticated interpretation and analysis of multimodal data.
Future Implications and Applications
The introduction of the Cosmo framework holds immense potential for various industries and applications. Here are a few examples of how Cosmo can revolutionize image and video processing:
- Automated Image Captioning: Cosmo’s improved performance in captioning tasks can enable more accurate and contextually relevant automated image captioning systems. This has implications in areas such as content creation, accessibility, and image indexing.
- Video Analysis and Surveillance: The ability to process and interpret multimodal data can significantly enhance video analysis and surveillance systems. Cosmo’s alignment capabilities can aid in activities like object recognition, activity detection, and anomaly identification.
- Content Moderation: With the rise of user-generated content, content moderation becomes increasingly challenging. Cosmo’s ability to understand and analyze both textual and visual elements can enhance content moderation systems, allowing for more effective detection of inappropriate or harmful content.
- Visual Search and Recommendation: Cosmo’s multimodal processing capabilities can revolutionize visual search and recommendation systems. By understanding the context of images and videos, these systems can provide more accurate and personalized recommendations to users.
Conclusion
The introduction of the Cosmo framework by researchers from Microsoft and NU Singapore marks a significant milestone in the field of multimodal learning and AI-driven image and video processing. Through its innovative design and methodology, Cosmo addresses the challenges of aligning textual and visual elements, opening doors to a more nuanced understanding of multimodal data.
The open-source nature of Cosmo encourages collaboration and knowledge sharing, propelling further advancements in the field. With its enhanced performance in tasks requiring multimodal data processing, Cosmo has the potential to revolutionize various industries and applications, from automated image captioning to video analysis and content moderation.
As AI continues to evolve, frameworks like Cosmo play a crucial role in pushing the boundaries of what machines can achieve in understanding and interpreting complex data. The future of multimodal learning looks promising, thanks to pioneering research efforts like the Cosmo framework.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.


Thanks for sharing. I read many of your blog posts, cool, your blog is very good.