Infini-Gram: Revolutionizing N-Gram Models Beyond Traditional Limits
The field of artificial intelligence (AI) has witnessed significant advancements in recent years, especially in the domain of natural language processing (NLP). Large neural language models (LLMs) pretrained on massive corpora have demonstrated remarkable performance gains. However, traditional n-gram language models (LMs) still hold relevance, and their scalability benefits remain unexplored. In a groundbreaking research paper titled “Infini-Gram: A Groundbreaking Approach to Scale and Enhance N-Gram Models Beyond Traditional Limits,” a team of researchers from the University of Washington and the Allen Institute for Artificial Intelligence proposes a revolutionary approach to modernize n-gram models and unleash their potential beyond traditional limitations.
The Relevance of N-Gram Language Models in the Era of Neural LMs
N-gram LMs have long been used in various NLP applications, offering insights into language patterns and aiding in text analysis. However, with the advent of large neural LMs, the significance of n-gram models has been questioned. The research paper affirms the continued utility of n-gram LMs and explores their potential to enhance the performance of neural LMs.
The authors argue that by scaling training data to an unprecedented scale and leveraging larger n values, traditional n-gram LMs can achieve enhanced predictive capacity. Departing from historical constraints on n (e.g., n ≤ 5), the authors introduce the concept of an ∞-gram LM with unbounded n, representing the largest n-gram LM to date. This expansion brings forth the need for innovative approaches to handle the increased complexity.
Introducing Infini-Gram: Scaling and Enhancing N-Gram Models
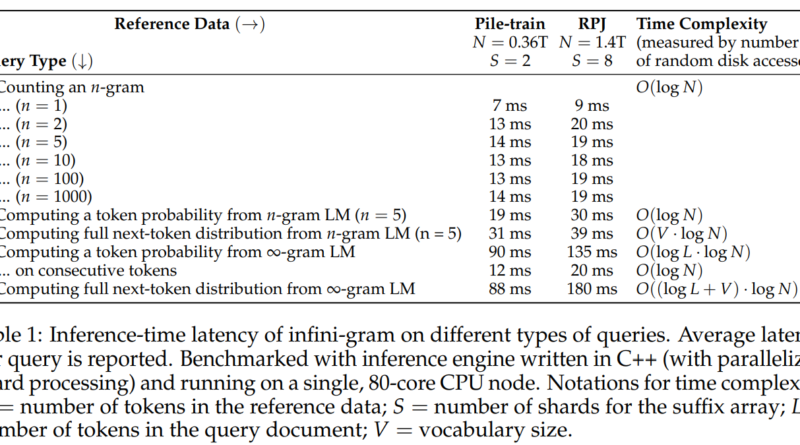
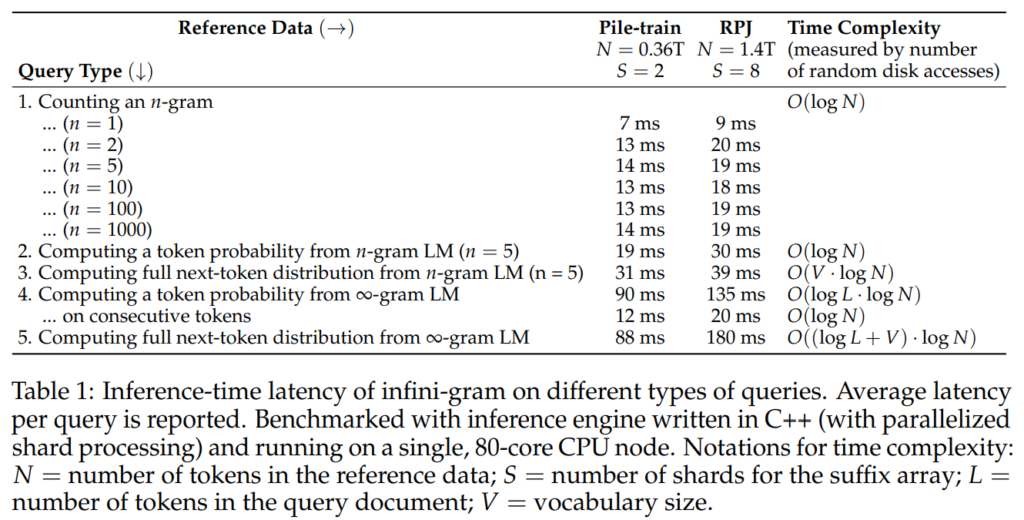
To tackle the limitations of traditional n-gram LMs, the researchers propose the Infini-Gram approach. This approach modernizes n-gram LMs by utilizing a suffix array instead of impractical n-gram count tables. The resulting implementation, known as the “infini-gram engine,” offers remarkable efficiency and low-latency querying.
The ∞-gram LM leverages a suffix array, which is built on an enormous training corpus of 1.4 trillion tokens. This implementation achieves a storage efficiency of 7 bytes per token, making it feasible to store and query such vast quantities of data. The ∞-gram engine ensures resource-efficient querying, with less than 20 milliseconds of latency for n-gram counting.
Advantages of the ∞-gram LM and Backoff Variants
The Infini-Gram approach introduces the concept of the ∞-gram LM with unbounded n. By utilizing larger n values, the predictive capacity of n-gram LMs is significantly enhanced. Figure 1 in the research paper illustrates the improved predictive capacity achieved with larger n values, challenging conventional limitations.
To address the sparsity issue in ∞-gram estimates, the authors incorporate backoff variants. Backoff allows the LM to interpolate with neural LMs, effectively addressing perplexity concerns. By combining the strengths of ∞-gram LMs and neural LMs, the authors pave the way for improved accuracy and performance.
Efficient Implementation and Applications of Infini-Gram
The implementation of the ∞-gram LM using the Infini-Gram approach involves efficient methods for n-gram counting, occurrence position retrieval, and document identification. The research paper outlines clever strategies, such as sharding, to reduce latency and optimize processing times. Additional optimizations, such as reusing search results and on-disk search, further enhance the speed of ∞-gram computation.
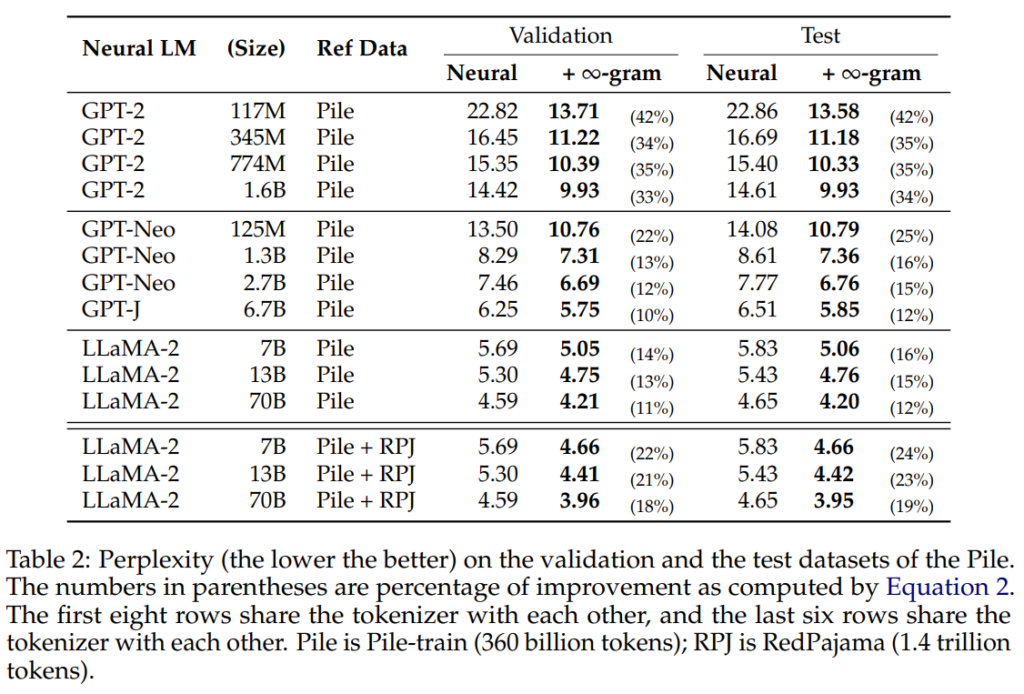
The Infini-Gram approach has been successfully applied across various neural LMs, including GPT-2, GPT-Neo, LLaMA-2, and SILO. The research paper highlights consistent improvements in perplexity, further reinforcing the efficacy of ∞-gram models in enhancing neural LMs across different model series.
Unveiling Insights with Infini-Gram
An analysis conducted using the Infini-Gram approach sheds light on both human-written and machine-generated text. Notably, ∞-gram models demonstrate high accuracy in predicting the next token based on human-written document prefixes. This finding establishes a positive correlation between neural LMs and ∞-gram models, suggesting the potential of ∞-gram models to enhance LM performance in predicting human-written text.
Future Outlook and Innovative Applications
The research paper concludes with a visionary outlook, presenting preliminary applications of the Infini-Gram engine. The possibilities for leveraging Infini-Gram are diverse, ranging from understanding text corpora to mitigating copyright infringement. The authors anticipate further insightful analyses and innovative applications fueled by the Infini-Gram approach.
In conclusion, the research paper “Infini-Gram: A Groundbreaking Approach to Scale and Enhance N-Gram Models Beyond Traditional Limits” introduces a revolutionary approach to modernizing n-gram models. By leveraging larger n values and backoff variants, the authors demonstrate the enhanced predictive capacity of n-gram LMs. The Infini-Gram approach, implemented through the efficient infini-gram engine, offers remarkable efficiency, low-latency querying, and consistent improvements in perplexity. With its potential applications across diverse neural LMs, the Infini-Gram engine opens up new avenues for leveraging the strengths of n-gram and neural language models.