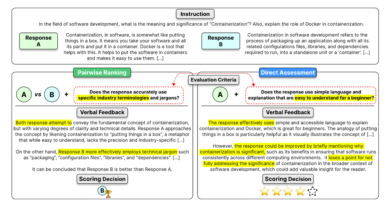
Meet the Matryoshka Embedding Models that Produce Useful Embeddings of Various Dimensions
In the rapidly evolving field of Natural Language Processing (NLP), embedding models play a crucial role in converting complex data, such as text, images, and audio, into numerical representations that can be easily understood and interpreted by computers. These embeddings, which are fixed-size dense vectors, serve as the foundation for a wide range of applications, including clustering, recommendation systems, and similarity searches.
However, as the complexity of these models increases, so does the size of the embeddings they generate. This can lead to efficiency issues for downstream tasks, such as storage and processing speed requirements. To address this challenge, a team of researchers has introduced a groundbreaking approach called Matryoshka Embedding Models that produce useful embeddings of various dimensions.
The Concept of Matryoshka Embeddings
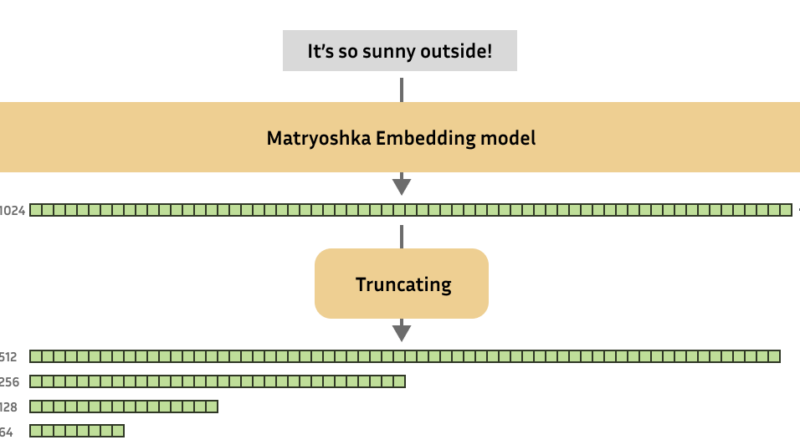
Matryoshka Embedding Models are named after the traditional Russian nesting dolls that contain smaller dolls within them. Just like these dolls, Matryoshka Embeddings operate on the concept of nested dimensions. These models are designed to generate embeddings that capture the most important information in the initial dimensions, allowing them to be truncated to smaller sizes without significant loss in performance.
The key advantage of Matryoshka Embeddings is their ability to produce variable-size embeddings that can be scaled according to storage requirements, processing speed, and performance trade-offs. This flexibility in controlling the size of embeddings without sacrificing accuracy offers significant benefits in terms of efficiency and scalability.
Applications of Matryoshka Embeddings
Matryoshka Embeddings have wide-ranging applications in the field of NLP. For example, reduced embeddings can be used to quickly shortlist candidates before performing more computationally intensive analysis using the complete embeddings. This is particularly useful in tasks like closest neighbor search shortlisting, where the ability to control the size of embeddings without compromising accuracy provides a significant advantage in terms of economy and scalability.
Training Matryoshka Embedding Models
Training Matryoshka Embedding Models requires a more sophisticated approach compared to traditional models. The training procedure involves evaluating the quality of embeddings at different reduced sizes, as well as at their full size. A specialized loss function is used to assess the embeddings at various dimensions, allowing the model to prioritize the most important information in the initial dimensions.
Frameworks such as Sentence Transformers support Matryoshka Embedding Models, making it relatively easy to implement this strategy in practice. These models can be trained with minimal overhead by using a Matryoshka-specific loss function across different truncations of the embeddings.
Efficiency and Performance Benefits
When using Matryoshka Embeddings in practical applications, embeddings are generated as usual but can be optionally truncated to the required size. This technique reduces the computational load, significantly improving the efficiency of downstream tasks without compromising the quality of the embeddings.
To demonstrate the effectiveness of Matryoshka Embeddings, two models trained on the AllNLI dataset were compared. The Matryoshka model outperformed the regular model in various aspects and maintained approximately 98% of its functionality when reduced to slightly over 8% of its initial size. This highlights the potential for substantial savings in processing and storage time while still achieving high accuracy.
The team behind Matryoshka Embeddings has also developed an interactive demo that allows users to dynamically adjust the output dimensions of an embedding model and observe how it affects retrieval performance. This practical demonstration not only showcases the adaptability of Matryoshka Embeddings but also illustrates their transformative potential for embedding-based applications.
Conclusion
Matryoshka Embedding Models offer a solution to the growing challenge of maintaining the efficiency of embedding models as they become larger and more complex. By enabling dynamic scaling of embedding sizes without significant loss in accuracy, Matryoshka Embeddings provides new opportunities for optimizing NLP applications across various domains.
The ability to control the size of embeddings according to specific requirements, such as storage limitations or computational constraints, opens up avenues for improved efficiency and scalability. Matryoshka Embeddings have demonstrated their effectiveness in reducing the computational load without compromising the quality of the embeddings, leading to substantial savings in processing time and storage resources.
As the field of NLP continues to advance, Matryoshka Embedding Models have the potential to revolutionize the way embedding-based applications are developed and deployed. By harnessing the power of nested dimensions, these models unlock new possibilities for optimizing the performance and efficiency of NLP systems, ultimately enhancing the user experience and driving further innovation in the field.