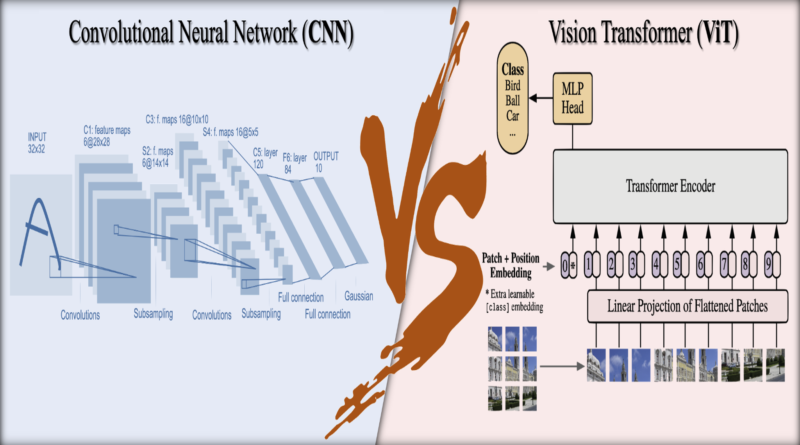
ViTs vs CNNs in AI Image Processing
Artificial Intelligence (AI) has made significant advancements in image processing, thanks to the emergence of powerful technologies such as Vision Transformers (ViTs) and Convolutional Neural Networks (CNNs). These two approaches have revolutionized the way machines perceive and understand visual data. In this article, we will delve into the intricacies of ViTs and CNNs, discussing their strengths, weaknesses, and broader implications in the field of AI image processing.
Vision Transformers(ViTs): A Paradigm Shift in Image Processing
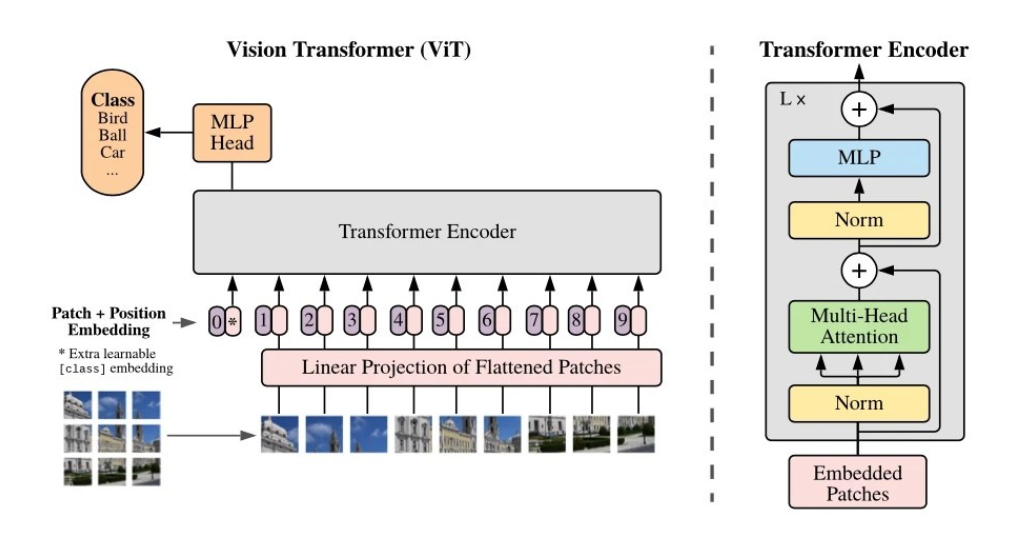
Originally designed for natural language processing, transformer models have now found their way into the visual domain through the development of Vision Transformers (ViTs). Unlike traditional CNNs, which rely on convolutional layers for localized feature extraction, ViTs take a different approach.
ViTs treat an image as a sequence of non-overlapping patches, which are then converted into vectors and processed by the transformer architecture. This methodology allows ViTs to capture global information across the entire image, enabling them to understand complex patterns and relationships that extend beyond just local features. By leveraging the power of self-attention mechanisms, ViTs excel in learning long-range dependencies and semantic relationships within images.
The ability of ViTs to process images as sequences of patches brings several advantages. Firstly, it eliminates the need for handcrafted architectures specifically designed for different tasks, as the transformer framework can be applied uniformly across various domains. Secondly, ViTs can effectively handle images of different sizes without the need for resizing or cropping. This scalability makes them ideal for processing high-resolution images.
One of the key benefits of ViTs is their ability to capture context and semantic understanding across the entire image. This global view allows them to excel in tasks that require holistic understanding, such as image captioning, visual question answering, and image generation.
Convolutional Neural Networks: The Cornerstone of Image Processing
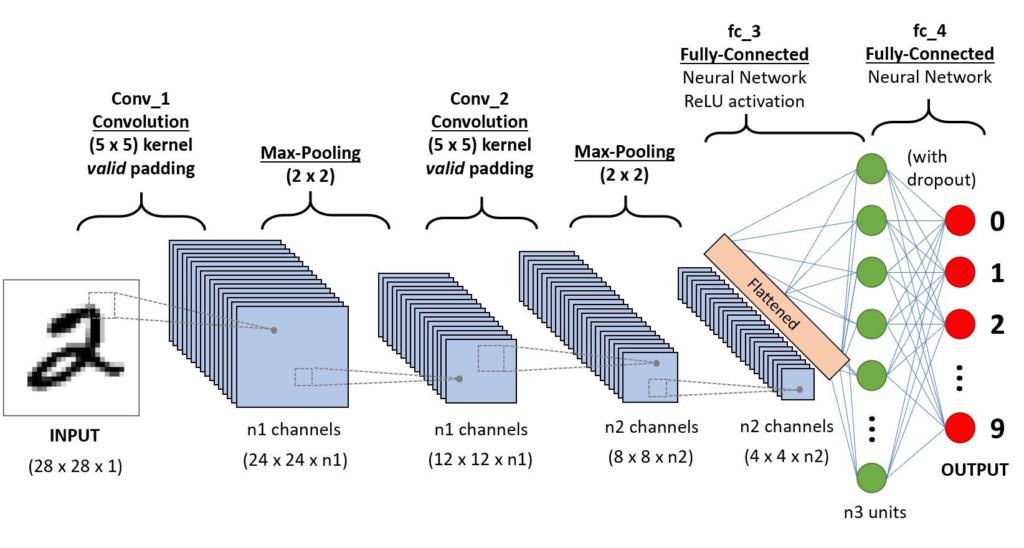
Convolutional Neural Networks (CNNs) have long been the go-to choice for image processing tasks, and for good reason. CNNs are specifically designed to extract local features from images, making them highly effective at tasks such as image classification, object detection, and semantic segmentation.
The architecture of CNNs is built around convolutional layers, which apply filters to the input image in a sliding window fashion. These filters capture relevant features at different spatial scales, allowing the network to learn hierarchical representations. By stacking multiple convolutional layers followed by pooling operations, CNNs progressively reduce the spatial dimensions of the input, leading to a compact representation that preserves the most salient features.
CNNs have proven to be highly efficient in handling large-scale datasets and have achieved state-of-the-art performance in various computer vision tasks. Their localized feature extraction capabilities make them particularly effective when the focus is on capturing fine-grained details within images.
Key Differences between Vision Transformers(ViTs) and Convolutional Neural Networks(CNNs)
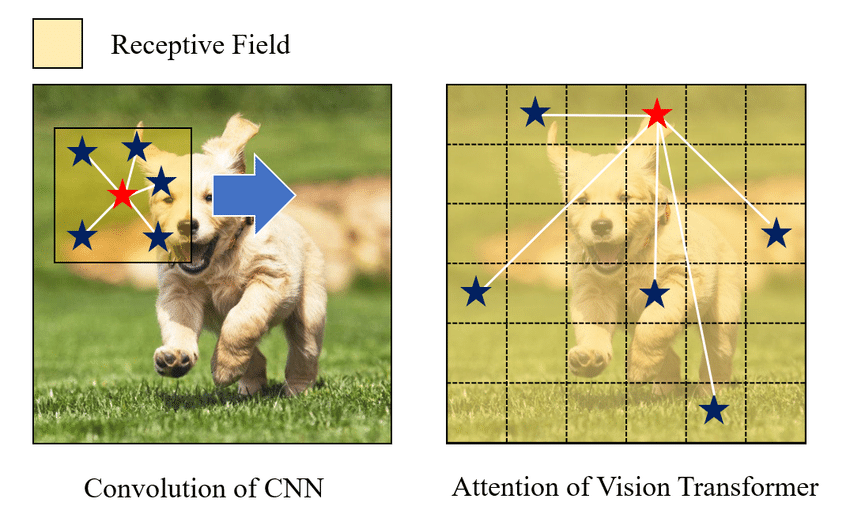
While both Vision Transformers and Convolutional Neural Networks have their strengths, there are some key differences that set them apart.
- Global vs Local Information: ViTs excel at capturing global information and understanding complex patterns across the entire image, while CNNs focus on extracting local features.
- Adaptability: ViTs offer scalability and flexibility, allowing them to handle images of different sizes without the need for resizing or cropping. CNNs, on the other hand, require fixed-size inputs.
- Hierarchical Representation: CNNs naturally learn hierarchical representations through their architecture, whereas ViTs rely on the transformer framework to capture relationships between patches.
- Computational Efficiency: CNNs are known for their computationally efficient operations, making them favorable for real-time applications. ViTs, on the other hand, may require more resources due to their self-attention mechanisms.
The choice between Vision Transformers and Convolutional Neural Networks depends on specific use cases, available resources, and the nature of the data at hand. For tasks that require a global understanding of the image and the ability to capture complex relationships, ViTs may be the preferred choice. On the other hand, if the focus is on extracting local features and achieving high computational efficiency, CNNs remain a strong contender.
Implications on Copyright Issues within the AI Industry
As ViTs and CNNs continue to advance, they bring to light significant copyright issues within the AI industry. The use of copyrighted images in training datasets poses legal and ethical challenges that become increasingly pronounced as these technologies become more capable and widespread.
The legal ramifications of using copyrighted images in AI training datasets are considerable. Recent cases, such as the January 2023 lawsuit against Stability AI, highlight the growing concerns over intellectual property rights in the era of transformative AI tools. It is crucial for the AI community to address these copyright issues and establish clear guidelines to ensure ethical and legal practices in image processing.
The Future of AI Image Processing
The development of Vision Transformers and Convolutional Neural Networks represents a technological competition and a challenge of balancing innovation with ethical and legal constraints. The ongoing advancements in these technologies will continue to redefine the landscape of image processing in AI.
It is essential for researchers and practitioners in the field of AI to foster technological developments while addressing the pressing copyright issues accompanying such advancements. Moreover, it is crucial to engage in broader discussions about the future of AI, encompassing not only technological advancements but also legal, ethical, and societal implications.
In conclusion, Vision Transformers and Convolutional Neural Networks have revolutionized the field of AI image processing. While ViTs offer the ability to capture global information and understand complex patterns, CNNs excel at extracting local features and achieving computational efficiency. The choice between these two approaches depends on specific use cases, available resources, and considerations of copyright issues within the AI industry. As AI continues to evolve, it is imperative to strike a balance between technological advancements and ethical practices for a sustainable and responsible AI future.
References –
- Convolutional Neural Networks vs Vision Transformers
- Vision Transformers vs. Convolutional Neural Networks
- Vision Transformers vs CNNs: Navigating Image Processing
- Introduction to Vision Transformers (ViT)
- Comparison of Convolutional Neural Networks and Vision Transformers (ViTs)
- Comparing Vision Transformers and Convolutional Neural Networks for Image Classification: A Literature Review
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
Read our other blogs on AI Tools 😁
If you like our work, you will love our Newsletter 📰