Enhancing Vision-Language Models with Chain of Manipulations: A Leap Towards Faithful Visual Reasoning and Error Traceability
The field of artificial intelligence (AI) has rapidly advanced in recent years, with significant progress made in vision-language models (VLMs). These models combine the power of natural language processing with computer vision to understand and generate text based on visual input. VLMs have shown great potential in various applications, such as visual question answering, visual grounding, and optical character recognition. However, there are still challenges to overcome to achieve faithful visual reasoning and error traceability.
The Need for Chain of Manipulations
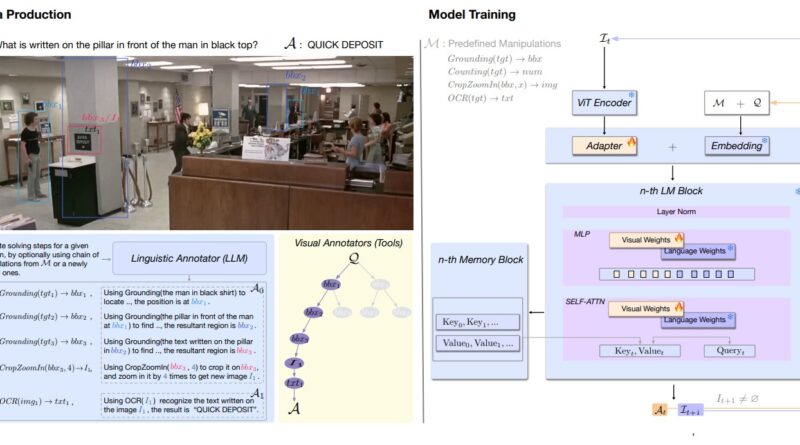
While VLMs have the ability to perform basic visual reasoning tasks, such as cropping and zooming in on images, there is a need for more advanced abilities to enhance their performance. This is where the concept of “Chain of Manipulations” (CoM) comes into play. CoM is a mechanism that allows VLMs to execute evidential visual reasoning by applying a sequence of manipulations to the visual input.
The idea behind CoM is to mimic the way humans manipulate and process visual information to address complex visual challenges. By incorporating a chain of manipulations, VLMs can acquire various visual contents and perform reasoning steps to arrive at the correct answer. This approach enables VLMs to go beyond basic visual reasoning and tackle more complex tasks.
The Research Study
A recent study conducted by researchers from Tsinghua University and Zhipu AI explores the concept of Chain of Manipulations and its impact on enhancing VLMs. The researchers developed an automated data creation platform based on an existing image-question-answer corpus. A linguistic annotator was then tasked with providing reasoning steps for specific queries, along with the corresponding manipulation returns.
To build a comprehensive and reasoning-capable VLM, the researchers introduced CogCoM, a 17B VLM trained with a memory-based compatible architecture. CogCoM utilizes a fusion of four categories of data based on the generated data. The model actively adopts various modifications to gain visual contents and referential regions, enhancing its reasoning capabilities.
Evaluating the Performance
To evaluate the performance of the CoM approach, the research team conducted comprehensive trials on eight benchmarks covering three classes of abilities: visual grounding, hallucination validation, and reasoning examination. The results consistently demonstrated competitive or even improved performance compared to existing models.
One key aspect of the evaluation was the examination of both the final results and the solving process. The researchers introduced a key points-aware measure to investigate the accuracy of the solution process along with the final result. This measure provides insights into the strengths and weaknesses of the model’s reasoning capabilities and helps identify areas for improvement.
Challenges and Recommendations
While the CoM approach shows promise in enhancing VLMs, there are still challenges to overcome. The researchers found that the language solution processes lack variety and that visual tools aren’t always accurate, leading to unfavorable paths. They recommend addressing these limitations by incorporating dedicated reminders and enhanced visual aids.
Furthermore, the researchers highlight the potential performance drops in the current model due to strict instructions for re-inputting altered photos. They suggest incorporating physical manipulations into vector space calculations to enhance the model’s overall performance.
Future Prospects
The research study on enhancing VLMs with Chain of Manipulations represents a significant step toward faithful visual reasoning and error traceability. The proposed visual reasoning process has the potential to accelerate the development of VLMs in the field of complex visual problem-solving.
Moreover, the data generation system introduced in this study has broader applications beyond VLMs. It can be utilized in various training scenarios to advance data-driven machine learning. By incorporating the concept of Chain of Manipulations, researchers can continue to explore new avenues for improving VLMs and unlocking their full potential.
Conclusion
Enhancing Vision-Language Models with Chain of Manipulations is a promising approach that enables VLMs to perform advanced visual reasoning tasks. By mimicking the way humans manipulate visual information, VLMs can acquire various visual contents and perform reasoning steps to arrive at accurate answers. The research study conducted by Tsinghua University and Zhipu AI demonstrates the effectiveness of the Chain of Manipulations approach in improving VLM performance.
While challenges and limitations exist, the study opens up new possibilities for further research and development in the field of faithful visual reasoning and error traceability. By addressing these challenges and incorporating recommendations, VLMs can continue to evolve and contribute to advancements in data-driven machine learning.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰