Exploring the Intricacies of Self-Correction in Language Models: Unveiling Logical Errors and Backtracking Efficacy
Language Models (LMs) have become an integral part of many AI applications, enabling tasks such as answering questions, completing tasks, and generating code. However, LMs are not without their limitations. Inaccurate outputs and logical errors can occur, especially when LMs are faced with complex reasoning tasks. To address this issue, researchers have been exploring the concept of self-correction in LMs. In this article, we delve into a recent AI paper from Google that uncovers the intricacies of self-correction in language models, specifically focusing on logical errors and the efficacy of backtracking.
The Need for Self-Correction in Language Models
Language Models are designed to generate text based on the input they receive. While they excel in various language-based tasks, they are not immune to errors. In scenarios that require reasoning, such as answering complex questions, LMs may produce incorrect or illogical outputs. This poses a challenge as users rely on accurate and reliable results from these models.
🔥Explore 3500+ AI Tools and 2000+ GPTs at AI Toolhouse
To overcome this limitation, researchers have been investigating methods to enable LMs to identify and correct their errors. Self-correction is a process that allows LMs to review their generated outputs, identify mistakes, and refine their responses based on feedback. By incorporating self-correction mechanisms, LMs can improve their accuracy and reliability in reasoning tasks.
Unveiling Logical Errors: The Google AI Paper
Google researchers recently published a paper titled “LLMs cannot find reasoning errors but can correct them!” This paper explores the limitations of LMs in terms of self-correction, specifically focusing on their ability to recognize logical errors in reasoning tasks.
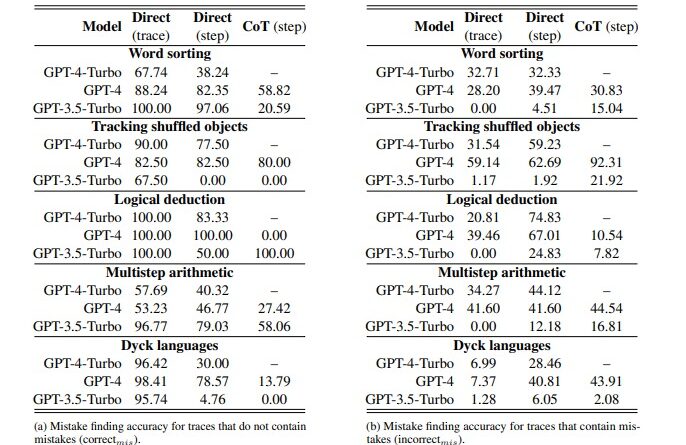
The researchers conducted thorough testing on two key components of self-correction: mistake finding and output correction. They utilized the BIG-Bench Mistake dataset, which consisted of 300 traces, including both correct and incorrect answers. Human labelers reviewed these traces to ensure accuracy and consistency in the evaluation process.
The Role of Mistake Finding in Self-Correction
One of the main objectives of the Google AI paper was to determine whether LMs can accurately identify logical errors in Chain-of-Thought (CoT) style reasoning tasks. CoT reasoning involves a series of interconnected statements, where LMs need to understand the relationships between these statements to arrive at the correct answer.
The findings of the study highlighted the difficulty LMs face in identifying logical errors. While self-correction allows LMs to refine their outputs, the initial identification of mistakes poses a significant challenge. Recognizing logical errors in CoT-style reasoning remains a complex task for LMs, indicating the need for further research and improvement in mistake finding mechanisms.
Leveraging Backtracking for Error Correction
In addition to examining mistake finding, the Google AI paper also explored the efficacy of backtracking for error correction. Backtracking refers to the process of retracing steps to rectify errors. The researchers proposed using a trained classifier as a reward model to facilitate backtracking and improve LM performance.
By leveraging backtracking as a means of error correction, LMs can analyze their generated outputs, identify the specific steps leading to logical errors, and refine their responses accordingly. This approach shows promise in enhancing the self-correction capabilities of LMs and improving their accuracy in reasoning tasks.
Implications and Future Directions
The study conducted by Google researchers sheds light on the intricacies of self-correction in language models, specifically in terms of identifying logical errors and the efficacy of backtracking. The findings indicate that while LMs struggle to recognize logical errors, they can correct them with the aid of backtracking and a trained reward model.
These findings have significant implications for the future development of LMs. Researchers are now motivated to delve deeper into refining mistake-finding mechanisms, leveraging innovative approaches, and enhancing error detection abilities. By addressing the challenges identified in the study, LMs can be empowered with robust self-correction capabilities, resulting in more accurate and reliable outputs for reasoning tasks.
Furthermore, the study also highlights the importance of fine-tuned reward models. The researchers found that a relatively small fine-tuned reward model can outperform the zero-shot prompting of a larger model when evaluating the same test set. This insight opens avenues for further exploration and optimization of reward models in self-correction mechanisms.
Conclusion
Language Models play a vital role in various AI applications, but they are not immune to errors, especially in reasoning tasks. The concept of self-correction offers a promising solution to enhance the accuracy and reliability of LMs by allowing them to identify and correct logical errors in their outputs. The Google AI paper discussed in this article uncovers the intricacies of self-correction in LMs, emphasizing the challenges in mistake finding and the potential of backtracking for error correction.
As the field of AI continues to advance, further research and development in self-correction mechanisms are essential. By addressing the limitations identified in the study, researchers can empower LMs with robust self-correction capabilities, paving the way for more accurate and reliable outputs in reasoning tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰