Advanced Language Models for Structured Knowledge Embedding with StructLM
Natural Language Processing (NLP) has made significant strides in recent years, thanks to the development of large language models (LLMs). These models, such as GPT-3 and ChatGPT, have demonstrated impressive capabilities in generating human-like text and understanding natural language. However, when it comes to dealing with structured information, LLMs still struggle to effectively ground their knowledge, highlighting a crucial gap in their capabilities.
The limitations of LLMs in handling structured data have motivated researchers to develop innovative approaches to enhance their structured knowledge grounding (SKG) capabilities. One such approach is the use of instruction tuning (IT) to improve the controllability and predictability of LLMs, aligning them with user expectations and improving their performance on downstream tasks.
To address this gap in SKG capabilities, a team of researchers from the University of Waterloo and Ohio State University has introduced StructLM. Leveraging the CodeLlama architecture, the StructLM model has been specifically designed to enhance LLMs’ ability to comprehend and utilize structured data more effectively.
The Need for Structured Knowledge Grounding in LLMs
LLMs have demonstrated remarkable proficiency in generating human-like text, but they often struggle to ground their knowledge in structured sources. This limitation becomes evident when LLMs are tasked with understanding and utilizing structured data, such as tabular data or database information. The ability to effectively ground structured knowledge is crucial for LLMs to perform tasks like data-to-text generation, table-based question answering, and other structured data interpretation tasks.
Advancements in Structured Knowledge Grounding
To improve LLMs’ structured knowledge grounding capabilities, several advancements have been made in recent years. These advancements include:
1. Learning Contextual Representations of Tabular Data
One approach to enhancing SKG is to learn contextual representations of tabular data. By incorporating tabular information into the training process, LLMs can gain a deeper understanding of the structure and semantics of structured data. This enables them to generate more accurate and contextually appropriate responses when dealing with structured information.
2. Integrating Relation-Aware Self-Attention
Another approach is to integrate relation-aware self-attention mechanisms. By considering the relationships between different elements in structured data, LLMs can better capture the dependencies and associations within the data. This helps them to generate more coherent and contextually relevant responses when grounded in structured knowledge.
3. Pretraining over Tabular/Database Data
Pretraining LLMs on tabular or database data has also been explored to enhance SKG capabilities. By exposing LLMs to a large corpus of structured data during the pretraining phase, they can develop a better understanding of the underlying structure and patterns within the data. This can lead to improved performance on SKG tasks, as the models have already learned to ground their knowledge in structured sources.
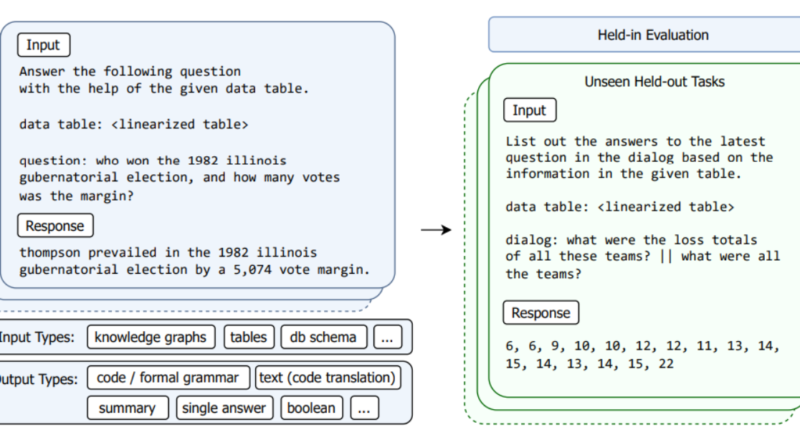
4. Unifying SKG Tasks into a Sequence-to-Sequence Format
Recent advancements have focused on unifying SKG tasks into a sequence-to-sequence format. By formulating SKG as a sequence generation problem, LLMs can be trained to generate output sequences that accurately capture the structured information present in the input. This approach has shown promising results in improving LLMs’ performance on SKG tasks.
5. Using Prompting Frameworks on LLMs
Prompting frameworks have also been utilized to enhance SKG capabilities. By providing explicit instructions or prompts to LLMs, researchers can guide their behavior and align them with user expectations. This improves the controllability and predictability of LLMs, enabling them to generate more accurate and contextually appropriate responses when grounded in structured knowledge.
Introducing StructLM: Advancing Large Language Models for Structured Knowledge Grounding
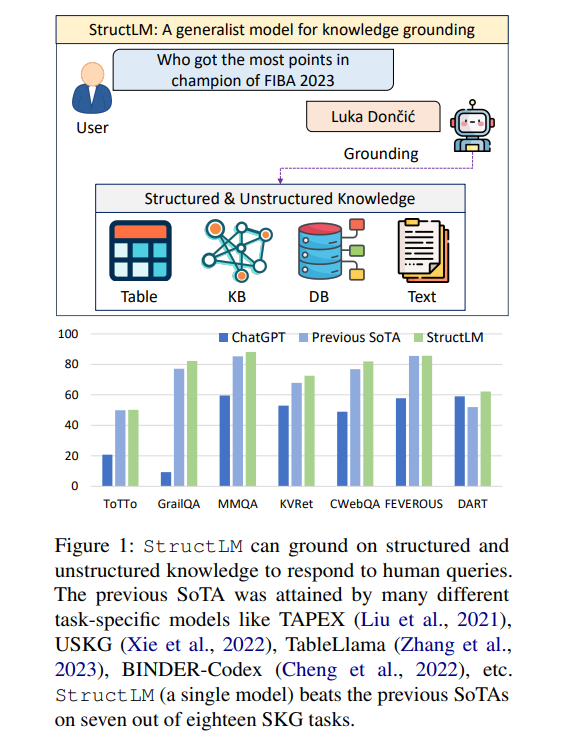
To further advance LLMs’ SKG capabilities, researchers from the University of Waterloo and Ohio State University have developed StructLM. Leveraging the CodeLlama architecture, StructLM is a novel model specifically designed to enhance the grounding of structured knowledge in LLMs.
The researchers trained StructLM using a comprehensive instruction-tuning dataset comprising over 1.1 million examples. This dataset allowed StructLM to learn how to effectively ground its knowledge in structured sources, surpassing task-specific models across a wide range of datasets. The CodeLlama architecture, with varying parameters ranging from 7B to 34B, ensures that StructLM can handle different levels of complexity and scale.
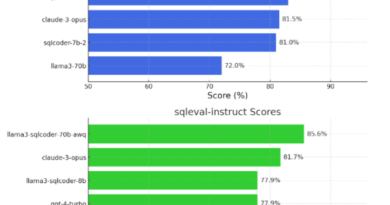
The research team curated a diverse dataset for StructLM, covering 25 SKG tasks, including data-to-text generation and table-based question answering. By evaluating StructLM on 18 held-in tasks and developing it for six held-out tasks, the researchers demonstrated its superior performance in grounding structured and unstructured knowledge. StructLM outperformed existing models on 14 of the 18 evaluated datasets, establishing new benchmarks for SKG tasks.
Furthermore, StructLM demonstrated strong generalization performance, outperforming ChatGPT on 5 out of 6 held-out tasks. This highlights the model’s ability to generalize its knowledge-grounding capabilities to new tasks and datasets. StructLM has the potential to redefine the landscape of structured data interpretation and further improve the SKG capabilities of LLMs.
Conclusion
The development of StructLM represents a significant advancement in improving LLMs’ structured knowledge grounding capabilities. By leveraging the CodeLlama architecture and a comprehensive instruction tuning dataset, StructLM surpasses task-specific models on a range of SKG tasks and establishes new state-of-the-art achievements. However, the researchers acknowledge the limitations in dataset diversity and evaluation metrics, emphasizing the need for broader and more heterogeneous structured data types to further enhance SKG model development.
As the field of NLP continues to evolve, advancements like StructLM pave the way for more effective and efficient utilization of structured information by large language models. With further research and development, LLMs can become even more proficient in understanding and leveraging structured data, enabling them to provide more accurate and contextually appropriate responses in various applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter📰