Introducing CLoVe: Enhancing Compositionality in Vision-Language Models
In recent years, the field of Vision-Language Models (VLMs) has witnessed remarkable advancements. Models like CLIP have demonstrated impressive performance in tasks that require the integration of visual and textual information. However, these models often struggle with compositionality, which refers to the ability to combine known concepts in novel ways. This limitation has prompted researchers from the University of Michigan and Netflix to propose a new machine-learning framework called CLoVe. In this article, we will explore the challenges faced by VLMs in achieving compositionality, the shortcomings of existing methods, and how CLoVe addresses these issues.
The Challenge of Compositionality in Vision-Language Models
VLMs have shown remarkable capabilities in recognizing objects and understanding textual information. However, when it comes to combining visual and textual elements in a compositional manner, these models often fall short. The problem lies in their text representations, which appear indifferent to word order. As a result, these models struggle to generate meaningful compositions of known concepts when presented with novel inputs.
For example, consider a VLM that has learned to recognize and describe various objects. Given the textual prompt “A red apple on a table,” the model may successfully identify and describe each individual component. However, if presented with a novel prompt like “A table on a red apple,” the model may fail to comprehend the intended composition, resulting in an incorrect output.
Existing Methods and Limitations
Researchers have proposed several methods to enhance compositionality in VLMs. Two notable approaches are NegCLIP and REPLACE. NegCLIP focuses on improving compositionality by leveraging negative examples, whereas REPLACE aims to enhance scores on compositionality benchmarks. However, both methods come with their own limitations.
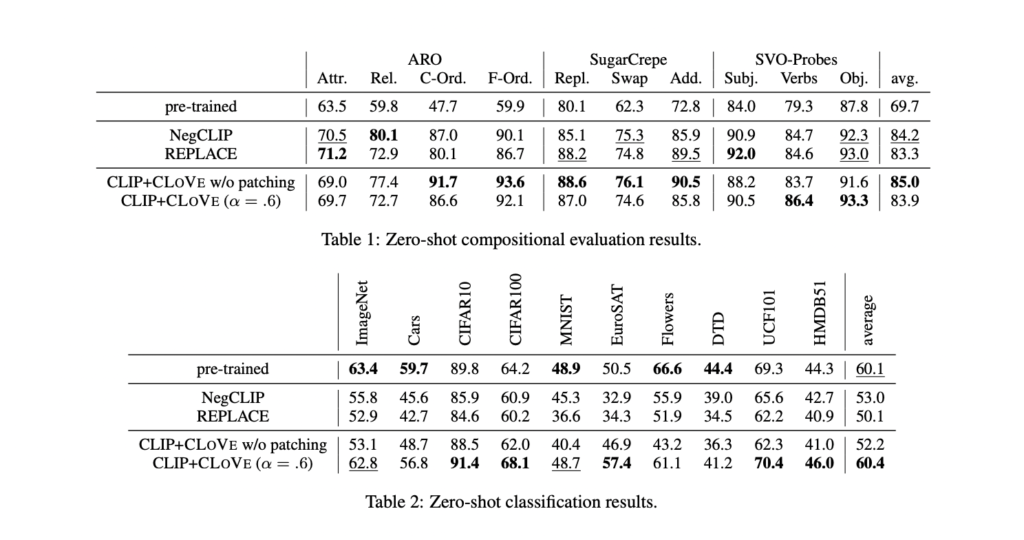
NegCLIP shows improved compositionality on benchmarks like SugarCrepe but at the expense of object recognition performance, particularly on datasets like ImageNet. REPLACE, on the other hand, enhances SugarCrepe scores but significantly reduces ImageNet performance, highlighting the challenge of balancing compositional capabilities with standard recognition tasks.
These limitations underscore the need for a new approach that can effectively enhance compositionality in VLMs while preserving performance on standard benchmarks.
Introducing CLoVe: A Machine Learning Framework for Compositionality
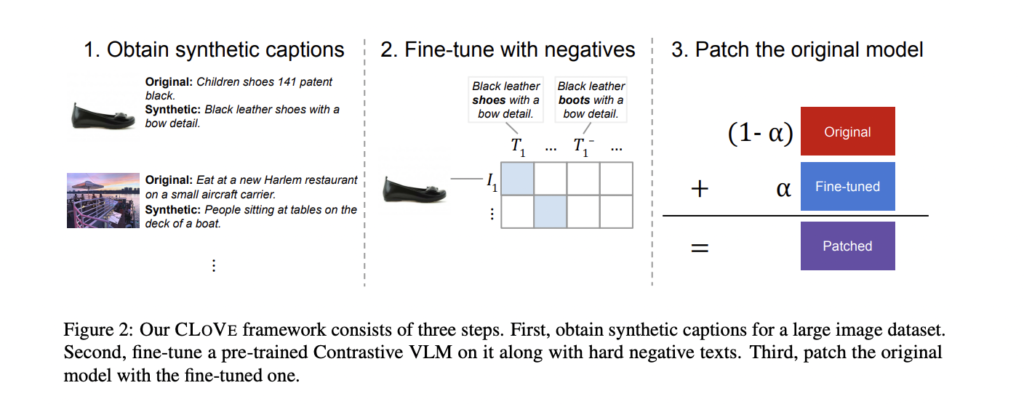
The team of researchers from the University of Michigan and Netflix has proposed a novel machine learning framework called CLoVe. This framework aims to improve the compositionality of pre-trained contrastive Vision-Language Models while maintaining performance on other tasks.
CLoVe achieves this goal through three key contributions:
1. Data Curation and Compositional Knowledge Handling
CLoVe leverages data curation techniques to impact the handling of compositional knowledge in VLMs. By carefully selecting and preprocessing training data, CLoVe aims to ensure that the model is exposed to a diverse range of compositional examples. This approach helps the model learn the relationship between visual and textual elements, enabling it to generate meaningful compositions when presented with novel inputs.
2. Training with Hard Negatives
To further enhance the model’s understanding of compositions, CLoVe incorporates training with hard negatives. Hard negatives are randomly generated text inputs that are designed to challenge the model’s compositional capabilities. By training the model on these hard negatives, CLoVe effectively strengthens its ability to comprehend and generate meaningful compositional outputs.
3. Model Patching for Balanced Performance
One of the key challenges in enhancing compositionality is maintaining performance on previously learned tasks. CLoVe addresses this challenge by employing model patching techniques. This approach allows the fine-tuned model to retain its enhanced compositionality while recovering performance on functions supported by the pre-trained model. By striking a balance between compositional gains and maintaining overall performance, CLoVe ensures the practical applicability of the framework.
Advantages of CLoVe
CLoVe offers several advantages over existing methods. Firstly, it significantly improves compositionality over pre-trained models like CLIP while maintaining performance on object recognition benchmarks like ImageNet. This balanced approach allows CLoVe to excel in both compositional understanding and object-centric recognition tasks.
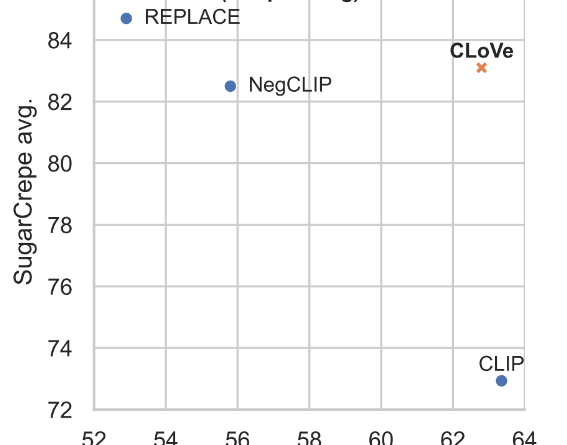
Secondly, CLoVe outperforms other methods like NegCLIP and REPLACE on various compositionality benchmarks, including ARO, SugarCrepe, and SVO-Probes. This superior performance in composition tasks highlights the effectiveness of CLoVe’s approach in improving the text representation capabilities of VLMs.
Lastly, CLoVe achieves higher Recall@5 scores than NegCLIP and REPLACE in zero-shot text-to-image and image-to-text retrieval tasks. This further demonstrates the superior compositionality and cross-modal understanding of CLoVe.
Conclusion
In conclusion, CLoVe is a novel machine-learning framework proposed by researchers from the University of Michigan and Netflix. By leveraging data curation, training with hard negatives, and employing model patching, CLoVe significantly enhances the compositionality of pre-trained contrastive Vision-Language Models without sacrificing performance on standard benchmarks. Experimental results demonstrate the effectiveness of CLoVe across various compositionality benchmarks, highlighting the importance of data quality, training with challenging negatives, and maintaining overall performance in advancing the capabilities of Vision-Language Models.
By addressing the challenge of compositionality, CLoVe paves the way for more sophisticated applications of Vision-Language Models in various fields, including image captioning, question-answering, and cross-modal retrieval. As the field continues to evolve, frameworks like CLoVe contribute to the ongoing development of AI systems that can understand and generate complex compositional concepts, bringing us closer to bridging the gap between language and vision.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter📰