Reinforced Fine-Tuning (ReFT): Enhancing the Generalizability of Learning LLMs for Reasoning with Math Problem Solving
In the world of artificial intelligence (AI), researchers are constantly looking for ways to enhance the performance and generalizability of language models. ByteDance AI Research has recently unveiled a new method called Reinforced Fine-Tuning (ReFT) that aims to enhance the generalizability of learning Large Language Models (LLMs) for reasoning, with math problem-solving as a prime example.
The Limitations of Supervised Fine-Tuning (SFT)
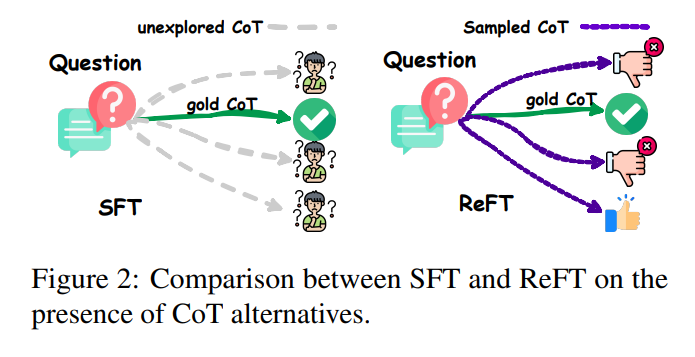
One effective method to improve the reasoning skills of LLMs is to employ supervised fine-tuning (SFT) with chain-of-thought (CoT) annotations. However, this approach has limitations in terms of generalization because it heavily depends on the provided CoT data. In scenarios like math problem-solving, each question in the training data typically has only one annotated reasoning path. While this approach may work well for the specific reasoning path that is annotated, it may struggle to generalize to unseen reasoning paths. This limitation hinders the overall performance and adaptability of the language models.
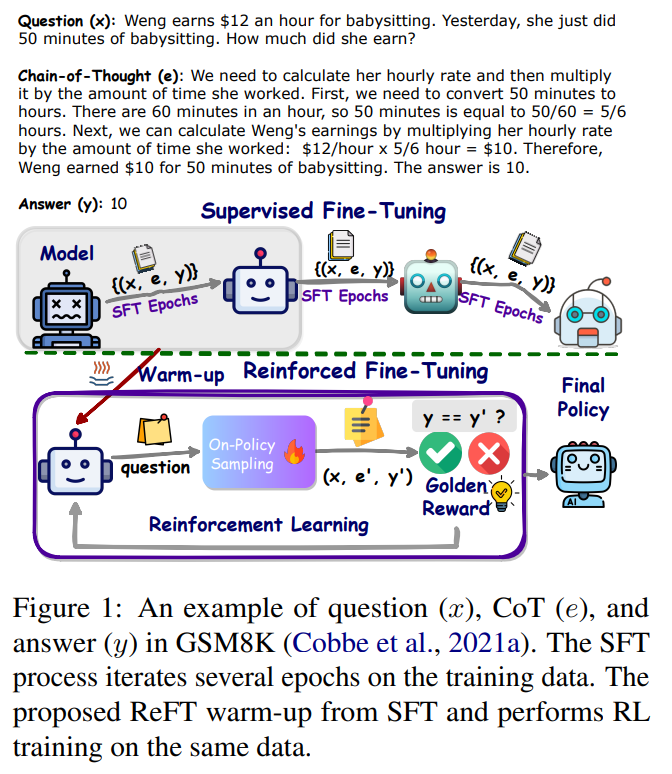
Introducing Reinforced Fine-Tuning (ReFT)
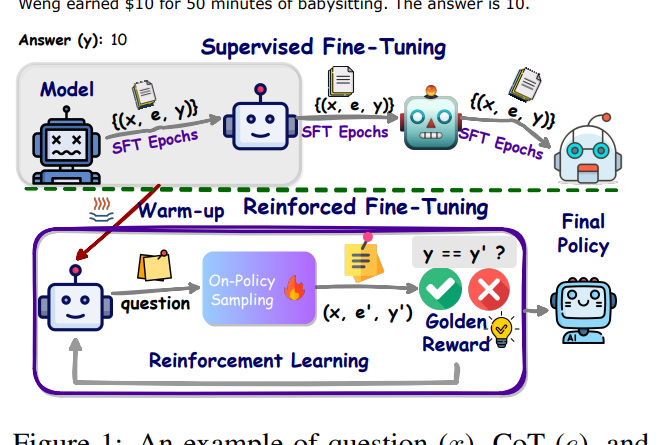
To overcome the limitations of SFT, researchers from ByteDance AI Research lab propose a practical method known as Reinforced Fine-Tuning (ReFT) [1]. The ReFT approach combines SFT with online reinforcement learning using the Proximal Policy Optimization (PPO) algorithm [2]. This two-stage process aims to enhance the generalizability of learning LLMs for reasoning, particularly in math problem-solving.
Stage 1: Warm-Up with Supervised Fine-Tuning (SFT)
The ReFT method begins by warming up the model through supervised fine-tuning (SFT) [2]. During this stage, the model is trained on annotated CoT data, which provides a starting point for the learning process. However, unlike traditional SFT, ReFT goes beyond relying on a single annotated reasoning path. It explores multiple CoT annotations to optimize a non-differentiable objective. This approach allows the model to learn from diverse reasoning paths and improves its ability to generalize to unseen scenarios.
Stage 2: Fine-Tuning with Reinforcement Learning
After the warm-up stage, ReFT leverages online reinforcement learning, specifically employing the Proximal Policy Optimization (PPO) algorithm [2]. During this fine-tuning process, the model is exposed to various reasoning paths automatically sampled based on the given question. These reasoning paths are not limited to the CoT annotations but are generated through exploration. The rewards for reinforcement learning come naturally from the ground-truth answers. By combining supervised fine-tuning with reinforcement learning, ReFT aims to create a more robust and adaptable LLM for enhanced reasoning abilities.
Improving CoT Prompt Design and Data Engineering
Recent research efforts have focused on improving chain-of-thought (CoT) prompt design and data engineering to enhance the quality and generalizability of reasoning solutions. Some approaches have utilized Python programs as CoT prompts, demonstrating more accurate reasoning steps and significant improvements over natural language CoT [6]. By using Python programs, researchers can provide more fine-grained and precise instructions for reasoning, leading to better performance in math problem-solving tasks.
Additionally, efforts are being made to increase the quantity and quality of CoT data, including the integration of additional data from OpenAI’s ChatGPT [5]. The availability of more diverse and extensive CoT data can help improve the generalizability of LLMs and enhance their reasoning capabilities.
The Performance of ReFT
The ReFT method has shown promising results in enhancing the generalizability of learning LLMs for reasoning in math problem-solving. Extensive experiments conducted on GSM8K, MathQA, and SVAMP datasets have demonstrated the superior performance of ReFT over SFT [1]. By exploring multiple reasoning paths and leveraging reinforcement learning, ReFT outperforms traditional supervised fine-tuning in terms of reasoning capability and generalization.
In addition to the core ReFT method, further enhancements can be achieved by combining inference-time strategies such as majority voting and re-ranking [1]. These strategies can help boost the performance of ReFT even further, ensuring that the model produces accurate and reliable reasoning solutions.
Conclusion
Reinforced Fine-Tuning (ReFT) stands out as a method that enhances the generalizability of learning LLMs for reasoning with math problem-solving as an example. By combining supervised fine-tuning with reinforcement learning, ReFT optimizes a non-differentiable objective and explores multiple CoT annotations, leading to improved reasoning capabilities and generalization. The performance of ReFT has been demonstrated through experiments on various datasets, showcasing its effectiveness in solving math problems [1]. Efforts to improve CoT prompt design, data engineering, and the integration of additional data sources further enhance the quality and generalizability of reasoning solutions. ReFT opens up new possibilities for enhancing the capabilities of language models and expanding their applications in various domains.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰