This AI Research Case Study from Microsoft Reveals How Medprompt Enhances GPT-4’s Specialist Capabilities in Medicine and Beyond Without Domain-Specific Training
Microsoft researchers address the challenge of improving GPT-4’s ability to answer medical questions without domain-specific training. They introduce Medprompt, which employs different prompting strategies to enhance GPT-4’s performance. The goal is to achieve state-of-the-art results on all nine benchmarks in the MultiMedQA suite.
This study extends prior research on GPT-4’s medical capabilities, notably BioGPT and Med-PaLM, by systematically exploring prompt engineering to enhance performance. Medprompt’s versatility is demonstrated across diverse domains, including electrical engineering, machine learning, philosophy, accounting, law, nursing, and clinical psychology.
The study explores AI’s goal of creating computational intelligence principles for universal problem-solving. It emphasizes the success of foundation models like GPT-3 and GPT-4, showcasing their remarkable competencies across diverse tasks without intensive specialized training. These models employ the text-to-text paradigm, learning extensively from large-scale web data. Performance metrics, such as next-word prediction accuracy, improve with increased scale in training data, model parameters, and computational resources. Foundation models demonstrate scalable problem-solving abilities, indicating their potential for generalized tasks across domains.
The research systematically explores prompt engineering to enhance GPT-4’s performance on medical challenges. Careful experimental design mitigates overfitting, employing a testing methodology akin to traditional machine learning. Medprompt’s evaluation of MultiMedQA datasets, using eyes-on and eyes-off splits, indicates robust generalization to unseen questions. The study examines performance under increased computational load and compares GPT-4’s CoT rationales with those of Med-PaLM 2, revealing longer and more detailed reasoning logic in the generated outputs.
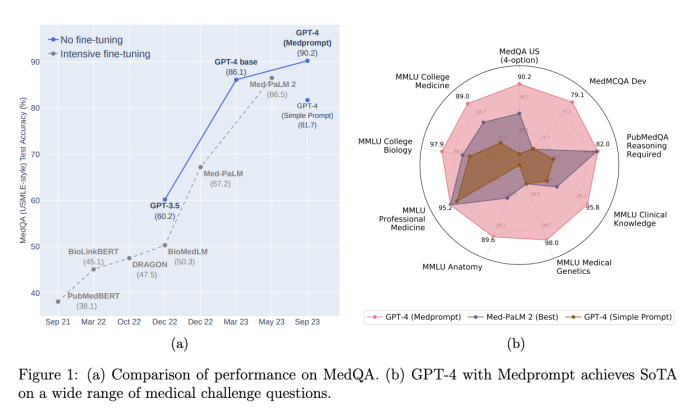
Medprompt improves GPT-4’s performance on medical question-answering datasets, achieving existing results in MultiMedQA and surpassing specialist models like Med-PaLM 2 with fewer calls. With Medprompt, GPT-4 achieves a 27% reduction in error rate on the MedQA dataset and breaks a 90% score for the first time. Medprompt’s techniques, including dynamic few-shot selection, a self-generated chain of thought, and choice shuffle-ensembling, can be applied beyond medicine to enhance GPT-4’s performance in various domains. The rigorous experimental design ensures that overfitting concerns are mitigated.
In conclusion, Medprompt has demonstrated exceptional performance in medical question-answering datasets, surpassing MultiMedQA and displaying adaptability across various domains. The study highlights the significance of eyes-off evaluations to prevent overfitting and recommends further exploration of prompt engineering and fine-tuning to utilize foundation models in vital fields such as healthcare.
In future work, it is important to refine prompts and the capabilities of foundation models in incorporating and composing few-shot examples into prompts. There is also potential for synergies between prompt engineering and fine-tuning in high-stakes domains, such as healthcare, and fast engineering and fine-tuning should be explored as crucial research areas. Game-theoretic Shapley values could be used for credit allocation in ablation studies, and further research is needed to calculate Shapley values and analyze their application in such studies.


