Introducing PaliGemma by Google AI
Google has recently unveiled a groundbreaking development in the field of artificial intelligence with the introduction of PaliGemma, a new family of vision language models. This innovative technology enables machines to understand and generate text based on visual input, opening up new possibilities for applications such as image captioning, question-answering, and document understanding.
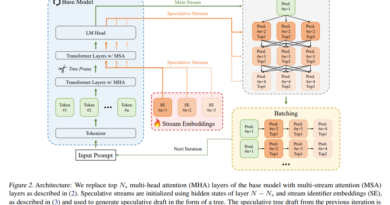
The PaliGemma Family
This family of vision language models is comprised of two primary components: the image encoder SigLIP-So400m and the text decoder Gemma-2B. SigLIP, which is short for “Similarity-based Language-Image Pretraining,” is a joint-trained image and text encoder similar to CLIP (Contrastive Language-Image Pretraining). This powerful model has the capability to comprehend both text and visuals, making it an essential component of the PaliGemma architecture.
Gemma, on the other hand, is a text-generating model that requires a decoder. By integrating Gemma with SigLIP’s image encoder using a linear adapter, PaliGemma becomes a potent vision language model that can generate text based on visual input.
PaliGemma Training and Capabilities
This family models were trained using the “Big_vision” codebase, which has also been utilized for developing other models such as CapPa, SigLIP, LiT, BiT, and the original ViT. This codebase has proven to be highly effective in training advanced vision language models.
This family offers a wide range of capabilities and can be fine-tuned to perform specific tasks such as image captioning, question-answering, entity detection, entity segmentation, and document understanding. These models are available in three different precision levels (bfloat16, float16, and float32) and three resolution levels (224×224, 448×448, and 896×896) . The higher resolution models provide superior quality but require more memory, while the 224×224 version is suitable for most use cases.
Use Cases and Limitations
It excels in single-turn tasks and performs best when fine-tuned for specific use cases. However, it is not intended for conversational use. While it offers a wide range of skills, it is important to note that PaliGemma needs to be fine-tuned using a comparable prompt structure for specific tasks. Task prefixes like “detect” or “segment” can be used to specify the desired task.
Although PaliGemma delivers impressive results, it may not be the most suitable choice for all applications. Users with limited resources should consider the memory requirements of the higher resolution models. For most tasks, the 224×224 versions provide a suitable balance between quality and resource usage.
Conclusion
Google’s introduction of PaliGemma signifies a major breakthrough in the field of vision language models. By combining advanced image and text encoders, PaliGemma enables machines to generate text based on visual input, opening up new possibilities in various applications.
The PaliGemma family offers an impressive range of capabilities and can be fine-tuned for specific tasks such as image captioning, question-answering, and entity detection. While it excels in single-turn tasks, it is not designed for conversational use.
As the field of artificial intelligence continues to advance, models like PaliGemma pave the way for machines to better understand and interact with the visual world. With its powerful capabilities, PaliGemma holds the potential to revolutionize various industries and drive further innovation in the field of AI.
Explore 3600+ latest AI tools at AI Toolhouse 🚀. Don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Read our other blogs on AI Tools 😁
If you like our work, you will love our Newsletter 📰