Apple’s Breakthrough in Language Model Efficiency: Unveiling Speculative Streaming for Faster Inference
Language models have revolutionized the field of artificial intelligence by enabling machines to understand and generate human language. These models have proven to be highly effective in a wide range of applications, from natural language processing to chatbots and virtual assistants. However, the computational burden associated with large language models (LLMs) has been a significant challenge, particularly during the inference phase, where generating each token requires extensive computational resources. To address this challenge, Apple has introduced a groundbreaking technique called Speculative Streaming, which aims to enhance the efficiency of LLM inference and enable faster and more responsive applications.
The Challenge of LLM Inference
The inference phase of LLMs is a computationally intensive process, requiring significant resources to generate responses in real-time. As LLMs have become increasingly complex and large, the latency in generating responses has become a critical bottleneck, hindering the deployment of these models in applications that require instant feedback. Traditional approaches to LLM inference are inherently sequential, resulting in time-consuming generation processes. This scenario has prompted researchers to explore innovative solutions to improve the efficiency of LLM inference while maintaining the quality of the outputs.
Introducing Speculative Decoding
Speculative decoding has emerged as a promising strategy to mitigate the delays associated with LLM inference. This technique involves generating multiple potential future tokens in advance, reducing the time required for generation. However, existing implementations of speculative decoding rely on a dual-model architecture, which includes a smaller draft model for generating candidate tokens and a larger target model for their verification. While effective, this approach introduces significant overhead, requiring the deployment and management of two separate models, thus complicating the inference pipeline.
Apple’s Breakthrough: Speculative Streaming
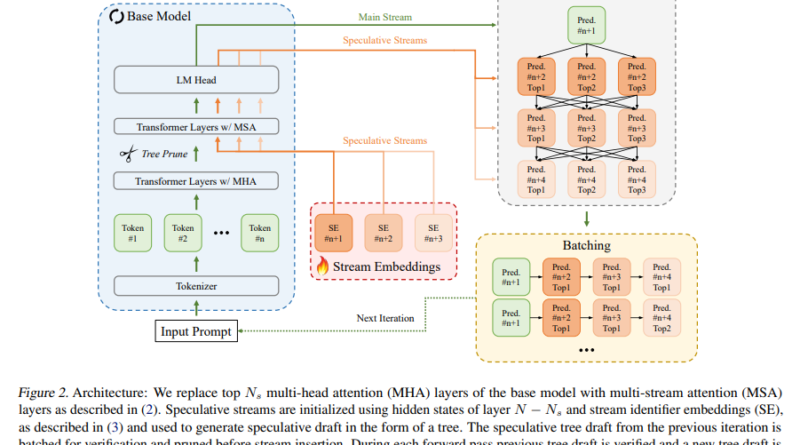
Apple’s Speculative Streaming introduces a groundbreaking methodology to address the challenges mentioned above head-on. This approach integrates the speculation and verification processes into a single, streamlined model, eliminating the need for an auxiliary draft model. At the core of Speculative Streaming lies a sophisticated multi-stream attention mechanism, enabling the model to simultaneously predict and verify multiple future tokens within a single forward pass. By leveraging the inherent parallelism in modern computing architectures, this mechanism significantly accelerates the inference process.
Efficient Utilization of Computational Resources
One of the key innovations of Speculative Streaming is the modification of the fine-tuning objective of the model. Instead of predicting the next token, the model is trained to predict future n-grams, allowing for more efficient utilization of computational resources. Despite this modification, the generative quality of the model is not compromised. In fact, Speculative Streaming introduces a novel tree drafting mechanism that optimizes the speculation process by generating a tree of candidate token sequences, pruned and verified in parallel, further enhancing the efficiency of the method.
Impressive Speed and Output Quality
Benchmarked against traditional methods and various state-of-the-art approaches, Speculative Streaming has demonstrated impressive speedups ranging from 1.8 to 3.1 times across diverse tasks such as summarization, structured queries, and meaning representation. Remarkably, these gains in efficiency have not been achieved at the expense of output quality. On the contrary, the approach consistently produces results on par with or superior to those generated by conventional methods, underscoring its effectiveness as a solution to the latency problem in LLM inference.
Parameter Efficiency and Deployment on Resource-Constrained Devices
Unlike other methods that require significant additional parameters to facilitate speculative decoding, Speculative Streaming achieves its objectives with minimal parameter overhead. This attribute makes it particularly well-suited for deployment on resource-constrained devices, such as mobile phones and IoT devices. The ability to efficiently utilize computational resources while maintaining high-quality outputs opens up new possibilities for applying LLMs in real-world settings where rapid response times are crucial.
Conclusion
Apple’s breakthrough in language model efficiency with the introduction of Speculative Streaming represents a significant leap forward in enhancing the efficiency of LLM inference. By elegantly fusing speculation and verification within a single model and introducing innovative mechanisms such as multi-stream attention and tree drafting, Apple has simplified the deployment and management of LLMs. The implications of this research are profound, promising to unlock new possibilities for applying LLMs in scenarios where rapid response times are crucial. As natural language processing continues to advance, approaches like Speculative Streaming will play a pivotal role in ensuring that the potential of LLMs can be fully realized in a wide array of applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰