LLMs in Computing Education: A New Era of Feedback Generation
In today’s rapidly evolving technological landscape, the field of computing education faces unique challenges. With the increasing demand for computing skills, large classes and limited resources, providing timely and effective feedback to students has become a crucial aspect of ensuring their success. Traditional methods of manual feedback can be time-consuming and often lack the personalization needed to address the diverse needs of individual learners. This is where large language models (LLMs) come into play, offering the potential to revolutionize the feedback generation process in computing education.
Automated feedback generation has been a long-standing challenge in computing education. Existing approaches primarily focus on identifying mistakes rather than providing constructive guidance. However, recent advancements in LLMs have shown promise in offering rapid, human-like feedback that can significantly enhance the learning experience for students.
The Limitations of Traditional Feedback Generation Methods
Before delving into the potential of LLMs, it is essential to understand the limitations of traditional feedback generation methods. Manual feedback provided by instructors or teaching assistants can be subjective, time-consuming, and often lacks consistency. It is challenging to provide personalized feedback to each student in a large class, leading to a one-size-fits-all approach that may not adequately address individual learning needs.
Furthermore, the time required for manual feedback can lead to delays, hindering students’ progress and reducing their motivation. With the increasing demand for computing skills and the need for continuous learning, a more efficient and scalable feedback generation approach is necessary.
Leveraging Large Language Models for Feedback Generation

Large language models, such as OpenAI’s GPT-3 and GPT-4, have demonstrated remarkable capabilities in understanding and generating human-like text. These models are trained on vast amounts of text data and can generate coherent and contextually relevant responses. Leveraging the power of LLMs, researchers have explored their potential in automating and enhancing feedback generation in computing education.

Recent research has shown that LLMs can identify issues in student code, such as compiler errors or test failures, with varying degrees of accuracy. However, there are limitations to their performance, including inconsistencies and inaccuracies in feedback. To address these limitations, the concept of using LLMs as judges to evaluate other LLMs’ output has gained traction. This approach, known as LLMs-as-judges, aims to improve the quality and reliability of feedback generated by LLMs.
Assessing the Effectiveness of LLMs in Feedback Generation
To evaluate the effectiveness of LLMs in providing feedback on student-written programs, researchers from Aalto University, the University of Jyväskylä, and The University of Auckland conducted a comprehensive study. The study aimed to assess whether open-source LLMs can rival proprietary ones in terms of feedback quality and reliability.
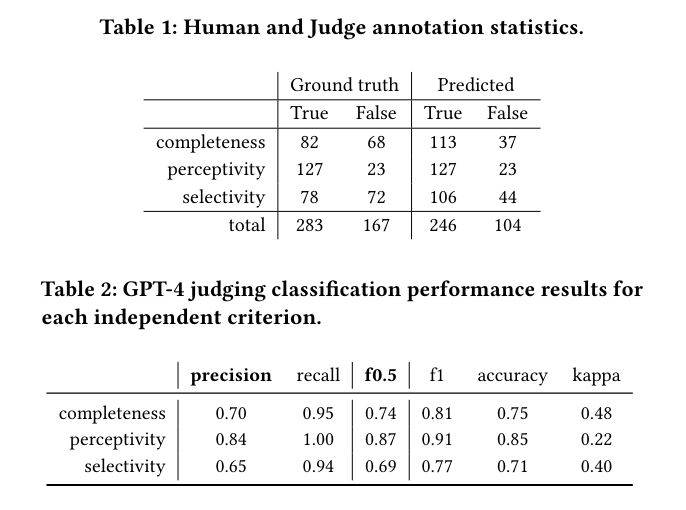
The researchers utilized data from an introductory programming course at Aalto University, consisting of student help requests and feedback generated by GPT-3.5. The evaluation criteria focused on feedback completeness, perceptivity, and selectivity. The feedback was assessed both qualitatively and automatically using GPT-4 as a judge.
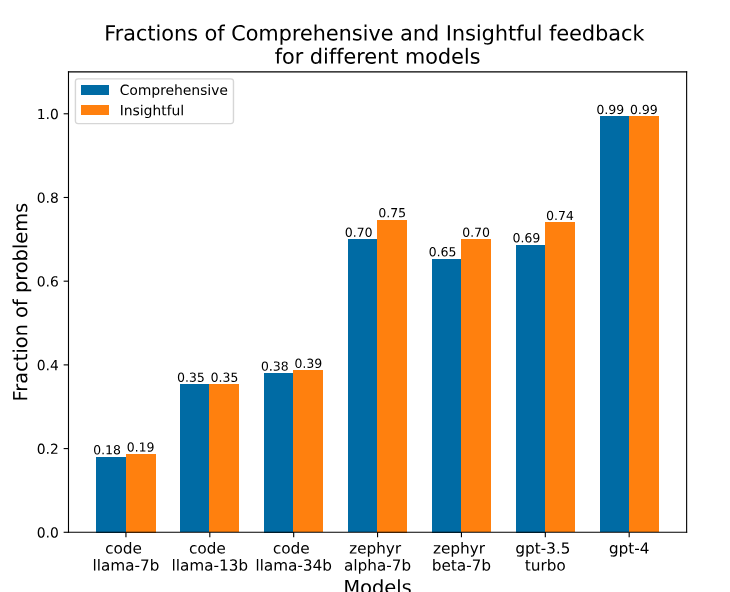
The results of the study showed that while most feedback generated by LLMs was perceptive, only a little over half of it was complete, and many contained misleading content. The performance of GPT-4 as a judge indicated reasonably good completeness classification and selectivity classification, with slightly lower performance in selectivity. The study also revealed that GPT-4 tends to grade feedback more positively compared to human annotators, suggesting some positive bias.
The Potential of Open-Source LLMs in Feedback Generation
One of the key aspects explored in the study was the potential of open-source LLMs in feedback generation. Open-source LLMs offer an alternative to proprietary models, ensuring more transparency, accessibility, and reduced reliance on proprietary solutions. Evaluating various open-source LLMs alongside proprietary ones, the researchers found that open-source models demonstrated the potential to generate programming feedback.
The ability of open-source LLMs to generate feedback opens up new opportunities for computing education. Instructors and teaching assistants can leverage these models as cost-effective and accessible resources to provide timely and personalized feedback to students. While proprietary LLMs may still exhibit higher levels of performance, open-source alternatives offer a promising solution for educational institutions with limited resources.
Ethical Considerations and Future Directions
Although LLMs offer significant potential for enhancing feedback generation in computing education, ethical considerations must be taken into account. The reliance on proprietary LLMs raises concerns about data privacy, ownership, and bias. Open-source alternatives provide a more transparent solution, addressing some of these ethical concerns. However, further research is needed to ensure the fairness, reliability, and effectiveness of both proprietary and open-source LLMs in generating feedback.
As the field of large language models continues to evolve, future research directions should focus on addressing the limitations and improving the performance of LLMs in feedback generation. The development of domain-specific LLMs tailored to computing education could further enhance the accuracy and relevance of generated feedback. Additionally, studies exploring the impact of personalized feedback from LLMs on student learning outcomes would provide valuable insights into the potential of these models in education.
Conclusion
Large language models have the potential to revolutionize feedback generation in computing education. By harnessing the power of LLMs, instructors and teaching assistants can provide timely, personalized feedback to students, addressing their individual learning needs. While there are limitations and ethical considerations associated with proprietary LLMs, open-source alternatives offer accessible and cost-effective solutions. Further research and development in the field can unlock the full potential of LLMs in enhancing feedback generation and improving student success in computing education.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
If you like our work, you will love our Newsletter 📰