ChuXin: Language Model Breakthrough
In the rapidly evolving field of natural language processing (NLP), language models have become increasingly powerful tools for generating human-like text. These models have revolutionized various applications, from chatbots to language translation systems. One of the latest additions to the domain of large language models (LLMs) is ChuXin 1.6B, a fully open-sourced language model with a whopping 1.6 billion parameters. In this article, we will explore the capabilities of ChuXin, its training methodology, and its potential impact on the research community.
Understanding ChuXin 1.6B
ChuXin 1.6B is a language model developed by a team of researchers with the goal of advancing the state-of-the-art in natural language processing. It is built upon the backbone of LLaMA2, a model architecture that has been specifically tailored for large-scale language models. With 1.6 billion parameters, ChuXin 1.6B is one of the largest language models publicly available.
Training Methodology
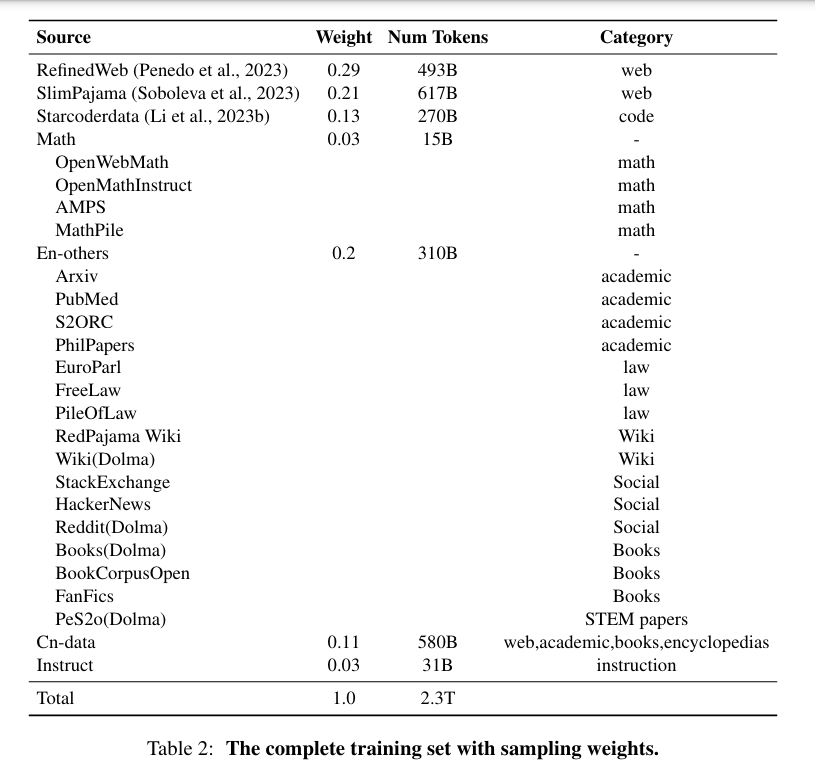
To train ChuXin 1.6B, the researchers utilized a vast amount of open-source data, including encyclopedias, online publications, public knowledge databases in both English and Chinese, and a staggering 2.3 trillion tokens of open-source data. This extensive dataset allowed ChuXin to learn from a wide variety of sources and enhance its language generation capabilities.
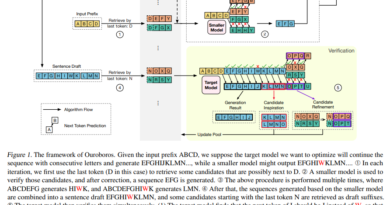
To achieve an input length of 1 million, the researchers improved ChuXin’s context length capabilities by continuing pre-training on datasets derived from lengthier texts. By incorporating longer texts into the training process, ChuXin gains a better understanding of context, enabling it to generate more coherent and contextually relevant text.
Advancements and Applications
ChuXin 1.6B represents a significant advancement in the field of language modeling. Its massive size and extensive training enable it to generate high-quality text across a wide range of applications. Researchers and developers can utilize ChuXin to enhance chatbots, improve language translation systems, and even generate code.
Furthermore, the open-source nature of ChuXin allows the research community to explore its capabilities, investigate its limitations, and understand its biases and potential risks. The availability of open language models like ChuXin fosters collaboration and drives advancements in the field.
Evaluating ChuXin’s Performance
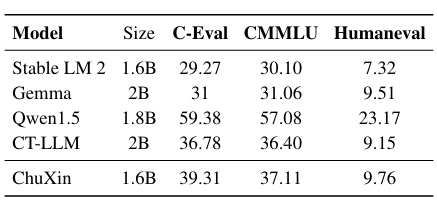
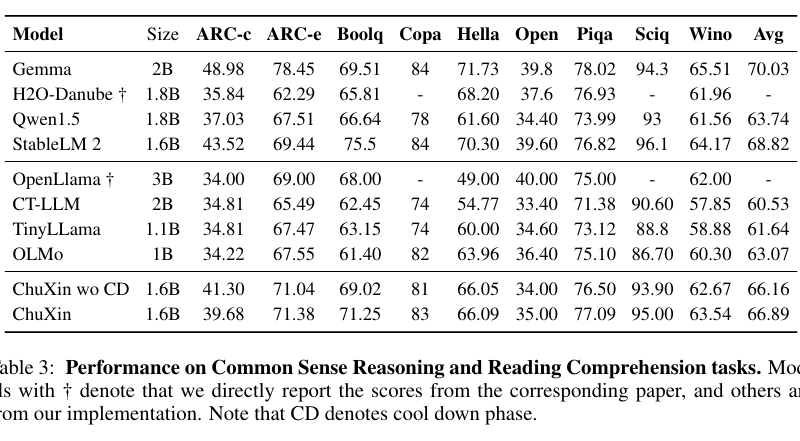
To evaluate the performance of ChuXin 1.6B, the research team conducted various tests and benchmarks. For Chinese tasks, they used the CMMLU and C-Eval tests, which assess Chinese comprehension and reasoning. Additionally, the team employed HumanEval to gauge ChuXin’s ability to generate code. The results of these evaluations demonstrated the model’s proficiency in performing these tasks and its improvement with increased training data.
Future Directions
The researchers behind ChuXin 1.6B envision a future where even larger and more advanced language models are developed. They plan to incorporate features like instruction tweaking and multi-modal integration to further enhance the capabilities of these models. Additionally, they aim to share the challenges they encountered during the development process, inspiring the open-source community and propelling further progress in language modeling.
Conclusion
ChuXin 1.6B is a groundbreaking open-source language model with a size of 1.6 billion parameters. Its extensive training and large-scale architecture enable it to generate high-quality text across various applications. As the field of natural language processing continues to evolve, models like ChuXin pave the way for advancements and foster collaboration within the research community. By leveraging the power of open-source language models, we can push the boundaries of language processing and create more sophisticated and context-aware systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
If you like our work, you will love our Newsletter 📰