Unlocking Speed and Efficiency in Large Language Models with Ouroboros: A Novel Artificial Intelligence Approach to Overcome the Challenges of Speculative Decoding
The field of natural language processing has witnessed remarkable progress with the advent of Large Language Models (LLMs) such as GPT and BERT. These models have demonstrated unparalleled capabilities in understanding and generating human-like text, revolutionizing various applications in conversational AI, language translation, and more. However, their widespread adoption in real-time scenarios has been impeded by a critical challenge: the need for faster inference speed.
Conventional autoregressive decoding, which generates tokens sequentially, poses a significant bottleneck in achieving high-speed inference with LLMs. Researchers from the NLP Group at Tsinghua University have introduced a novel framework called Ouroboros, which offers a groundbreaking solution to this challenge. Ouroboros adopts a speculative decoding method, departing from the traditional autoregressive approach, and promises to unlock speed and efficiency in large language models.
The Limitations of Speculative Decoding
Before delving into the details of Ouroboros, it is essential to understand the limitations of speculative decoding. Speculative decoding is a widely-used technique to speed up inference for LLMs without modifying the outcome. It involves generating multiple tokens simultaneously, enabling parallel processing and potential acceleration. However, speculative decoding has traditionally suffered from issues such as high computational complexity and loss of output quality. These limitations have hindered its widespread adoption and necessitated the development of innovative approaches like Ouroboros.
Ouroboros: Revolutionizing Efficiency in Large Language Models
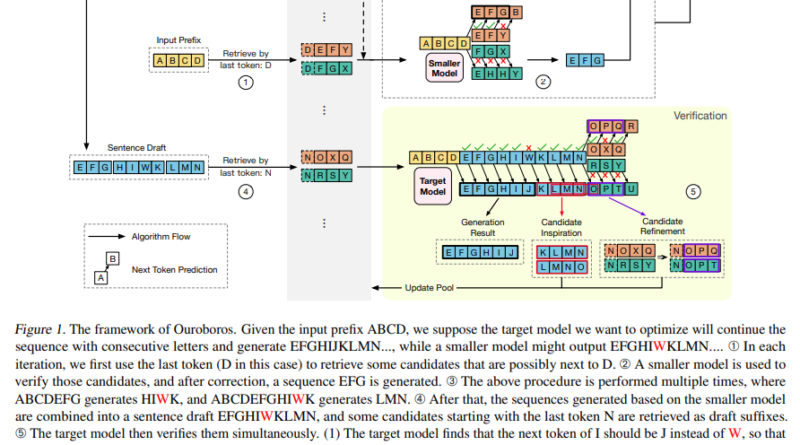
Ouroboros represents a groundbreaking approach to overcoming the challenges of speculative decoding and unlocking speed and efficiency in large language models. Developed by the NLP Group at Tsinghua University, Ouroboros introduces a novel framework that combines speculative decoding with the concept of a phrase candidate pool to enhance efficiency during inference.
Speculative Decoding with Ouroboros
In the Ouroboros framework, the speculative decoding process begins by using a smaller, more efficient model to generate initial drafts. These drafts are constructed at the phrase level, providing a higher-level representation of the desired output. Unlike traditional autoregressive decoding, which generates one token at a time, Ouroboros leverages the concept of a phrase candidate pool to inspire the drafting process. The phrase candidate pool contains potential phrase candidates that align with the target output, enabling the smaller model to produce longer, more coherent drafts.
Verification and Refinement Process
Once the initial drafts are generated, a verification and refinement process takes place using the larger target model. This process ensures that the output maintains high accuracy and coherence while benefiting from the speed-ups achieved through speculative decoding. Unlike traditional methods, which only consider confirmed tokens, Ouroboros leverages the entire draft, including both confirmed and discarded tokens, for verification and refinement. This holistic approach ensures that the output maintains the desired quality while significantly accelerating the inference process.
Advantages of Ouroboros
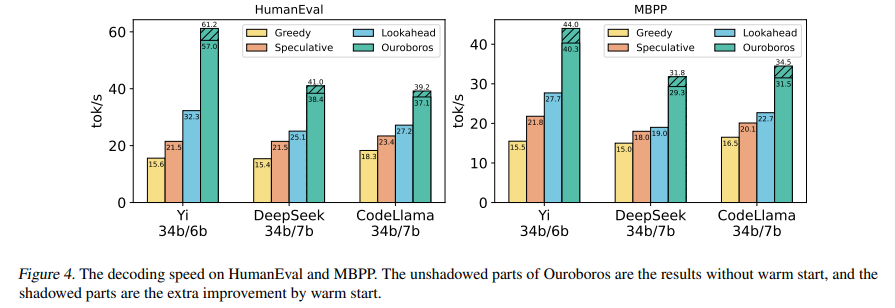
Ouroboros offers several advantages over existing methods such as lookahead decoding and traditional speculative decoding. It achieves speed-ups of up to 2.8x without compromising the quality of the output. This acceleration opens up new possibilities for real-time applications of large language models, where speed and accuracy are of utmost importance. Whether it’s conversational AI, instant language translation, or any other application that requires real-time language processing, Ouroboros provides a promising solution.
Potential Applications and Future Developments
The introduction of the Ouroboros framework paves the way for significant advancements in large language models and their applications. Real-time scenarios that were previously beyond reach can now benefit from the speed and efficiency offered by Ouroboros. Conversational AI systems can generate responses faster, language translation services can provide instant translations, and various other applications can leverage the power of large language models in real-time.


As the field of natural language processing continues to evolve, the principles underlying Ouroboros are likely to inspire further innovations. Researchers and developers will build upon this novel approach to unlock even greater speed and efficiency in large language models. The quest for ever more efficient and effective natural language processing technologies will continue, fueled by the success of frameworks like Ouroboros.
In conclusion, Ouroboros introduces a groundbreaking framework that overcomes the challenges of speculative decoding and unlocks speed and efficiency in large language models. By combining speculative decoding with a phrase candidate pool and leveraging the verification and refinement process, Ouroboros achieves a fine balance between speed and output quality. This innovation opens up new possibilities for real-time applications of large language models and sets a new benchmark for future developments in natural language processing.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰