Boosting GNNs with DiskGNN Tech
The field of machine learning has seen significant advancements in recent years, particularly in the realm of graph neural networks (GNNs). GNNs are a powerful tool for processing data from domains such as e-commerce and social networks, where complex structures need to be analyzed. However, as the scale of graph data continues to grow, traditional GNN systems face challenges in efficiently handling large datasets that exceed memory limits. This is where DiskGNN comes in as a transformative solution designed to optimize the speed and accuracy of GNN training on large-scale datasets.
The Need for DiskGNN
Traditionally, GNNs operate on data that fits within a system’s main memory. However, as datasets grow larger and more complex, it becomes increasingly challenging to handle them entirely in memory. This introduces the need for out-of-core solutions where data resides on disk. Existing out-of-core GNN systems face a trade-off between efficient data access and model accuracy. They either suffer from slow input/output operations due to small, frequent disk reads or compromise accuracy by handling graph data in disconnected chunks.
For example, previous solutions like Ginex and MariusGNN have shown significant drawbacks in terms of training speed or accuracy when dealing with large-scale datasets. This limitation calls for a more efficient and accurate approach to training GNNs on large datasets, and DiskGNN aims to fill that gap.
Introducing DiskGNN
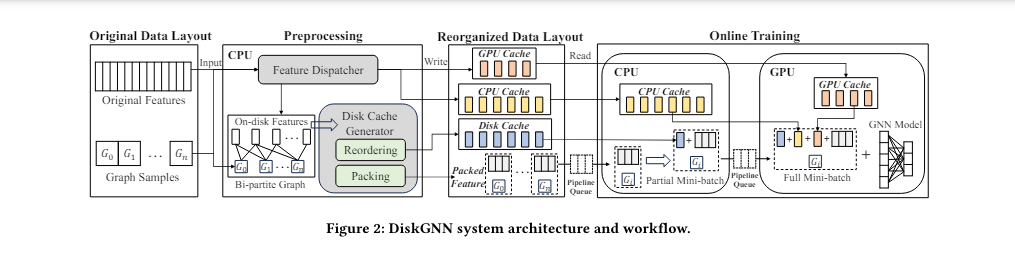
DiskGNN is a framework developed by researchers from Southern University of Science and Technology, Shanghai Jiao Tong University, Centre for Perceptual and Interactive Intelligence, AWS Shanghai AI Lab, and New York University. It focuses on optimizing the speed and accuracy of GNN training on large datasets by utilizing an innovative offline sampling technique.
The core idea behind DiskGNN is to preprocess and arrange graph data based on expected access patterns, thereby reducing unnecessary disk reads during training. This preprocessing step allows DiskGNN to organize node features into contiguous blocks on the disk, minimizing the amplification of read operations inherent in disk-based systems. By strategically managing data access and utilizing a multi-tiered storage approach that leverages GPU and CPU memory alongside disk storage, DiskGNN ensures that frequently accessed data is kept closer to the computation layer, resulting in significant speed improvements.
Enhancing Training Efficiency
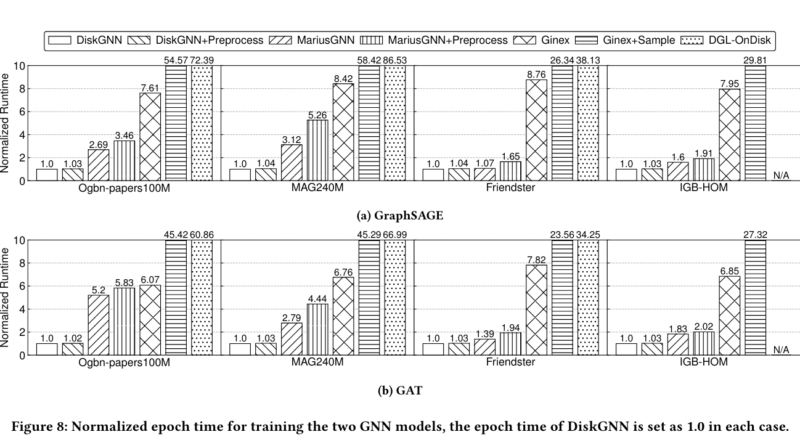
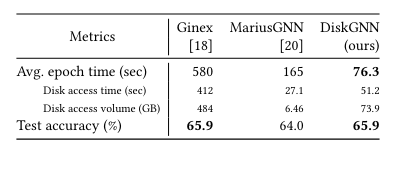
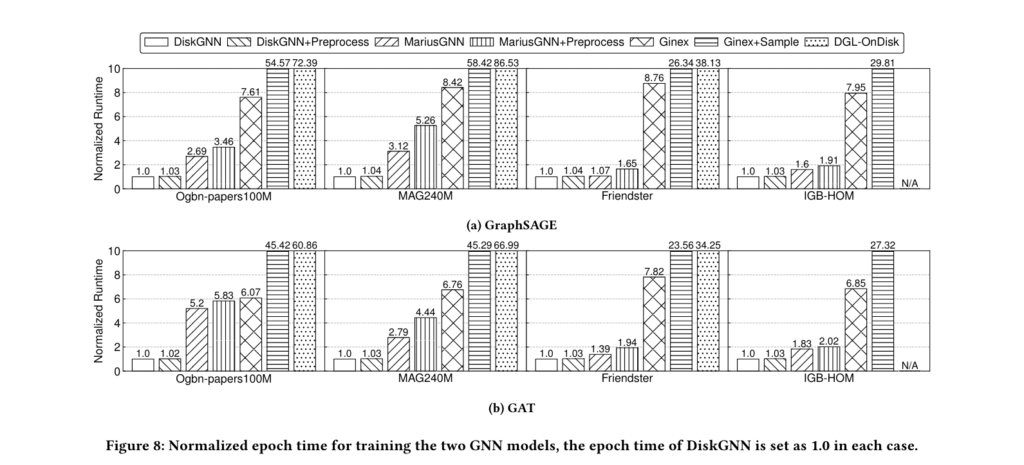
The architecture of DiskGNN is designed to optimize the training process for large-scale GNNs. In benchmark tests, DiskGNN demonstrated a speedup of over eight times compared to baselines, with training epochs averaging around 76 seconds, in contrast to 580 seconds for systems like Ginex. This substantial improvement in training speed can have a significant impact on researchers and industries working with extensive graph datasets, where time is of the essence.
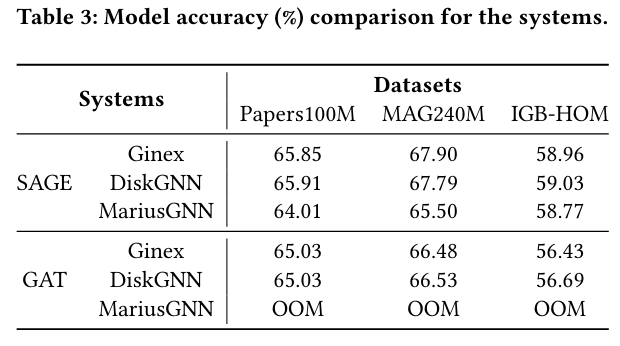
Moreover, DiskGNN achieves these speed gains while maintaining high model accuracy. Performance evaluations indicate that DiskGNN matches or exceeds the best model accuracies of existing systems while reducing the average epoch time and disk access time. For instance, when tested on the Ogbn-papers100M graph dataset, DiskGNN maintained an accuracy of approximately 65.9% while reducing the average disk access time to just 51.2 seconds, compared to 412 seconds in previous systems.
The Significance of DiskGNN
The introduction of DiskGNN represents a significant leap forward in efficient large-scale learning with graph neural networks. By addressing the dual challenges of data access speed and model accuracy, DiskGNN sets a new standard for out-of-core GNN training. Its strategic data management and innovative architecture outperform existing solutions, offering a faster and more accurate approach to training GNNs on large datasets.
The implications of DiskGNN extend beyond academic research. Industries such as e-commerce and social networks, where large-scale graph data is prevalent, can benefit greatly from this technology. DiskGNN’s ability to handle massive datasets efficiently opens up new possibilities for analyzing complex structures and extracting valuable insights from the data. With DiskGNN, researchers and practitioners can push the boundaries of what is possible with GNNs, making it an invaluable tool for data-intensive tasks.
Conclusion
Graph neural networks have revolutionized the field of machine learning by enabling the analysis of complex data structures. However, as datasets continue to grow in scale and complexity, traditional methods for training GNNs face limitations. DiskGNN emerges as a transformative solution, optimizing the speed and accuracy of GNN training on large-scale datasets.
By leveraging an innovative offline sampling technique and a multi-tiered storage approach, DiskGNN significantly enhances training efficiency. It minimizes unnecessary disk reads, reduces the load on the storage system, and speeds up the training process. Moreover, DiskGNN maintains high model accuracy, outperforming existing solutions in both speed and accuracy.
DiskGNN’s contributions extend beyond the academic realm, offering practical applications in industries dealing with extensive graph datasets. With DiskGNN, researchers and practitioners can unlock the full potential of large-scale graph data, opening up new avenues for analysis and insights.
In summary, DiskGNN represents a leap toward efficient large-scale learning with graph neural networks, setting a new standard for out-of-core GNN training. As the field continues to evolve, DiskGNN will undoubtedly play a crucial role in advancing the capabilities of graph-based machine learning and empowering data-driven decision-making.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
Read our other blogs on AI Tools 😁
If you like our work, you will love our Newsletter 📰