Advancements in Knowledge Distillation and Multi-Teacher Learning: Introducing AM-RADIO Framework
Knowledge distillation has become a widely adopted technique for transferring knowledge from a larger “teacher” model to a smaller “student” model, achieving performance similar to or even surpassing the teacher’s capabilities. This approach has opened up new possibilities for model compression, enabling the deployment of efficient and lightweight models without sacrificing performance.
In recent years, advancements in knowledge distillation have led to the emergence of multi-teacher learning frameworks. These frameworks leverage the knowledge of multiple teacher models to enhance the learning process of the student model. One such innovative framework is the AM-RADIO framework, which aims to train a vision foundation model from scratch through multi-teacher distillation.
The Concept of Knowledge Distillation
Before diving into the details of the AM-RADIO framework, let’s first understand the concept of knowledge distillation. Knowledge distillation involves training a “student” model using the soft targets generated by a pre-trained “teacher” model. These soft targets can be either the teacher’s output logits or intermediate network activations. By learning from the teacher’s knowledge, the student model can benefit from the teacher’s expertise and generalize better on unseen data.
The traditional knowledge distillation approach involves using a single teacher model to distill knowledge into a student model. However, recent research has shown that leveraging multiple teacher models can further enhance the performance of the student model. This is where the concept of multi-teacher learning comes into play.
Multi-Teacher Learning and the AM-RADIO Framework
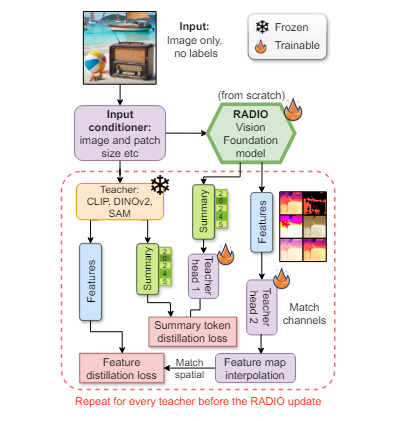
Multi-teacher learning explores the idea of jointly distilling a student model from multiple teachers. Each teacher model provides a unique perspective and knowledge, which the student model can benefit from. The AM-RADIO framework takes this concept a step further by utilizing multiple foundational models simultaneously, enabling student models to surpass individual teachers on crucial metrics.
The AM-RADIO framework selects three seminal teacher model families, namely CLIP, DINOv2, and SAM, for their outstanding performance across various vision tasks. These teacher models represent a broad spectrum of internet images and provide a diverse range of knowledge. The AM-RADIO framework assumes that these teacher models collectively capture a comprehensive understanding of vision tasks, without relying on supplemental ground truth guidance.
The evaluation of the AM-RADIO framework encompasses various metrics, including image-level reasoning, pixel-level visual tasks such as segmentation mIOU on ADE20K and Pascal VOC, and integration into large Vision-Language Models. Notably, the framework’s performance is evaluated against the SAM-COCO instance segmentation task.
Introducing E-RADIO: A Hybrid Architecture for Knowledge Distillation
While the AM-RADIO framework leverages multiple teacher models to enhance student learning, it also presents a challenge when distilling foundation models (FMs) with CNN-like architectures. To address this challenge, NVIDIA researchers introduce a novel hybrid architecture called E-RADIO.
E-RADIO surpasses the performance of individual teachers like CLIP, DINOv2, and SAM in various tasks, including vision question answering. It exhibits higher throughput and improved efficiency compared to traditional Vision Transformer (ViT) models. Furthermore, E-RADIO outperforms ViT models in dense tasks such as semantic segmentation and instance segmentation.
The flexibility of the E-RADIO framework is highlighted by its successful integration into visual question-answering setups, showcasing its potential for diverse applications. This hybrid architecture brings together the strengths of both the foundation models and CNN-like architectures, resulting in superior performance and efficiency.
Conclusion: Advancements and Possibilities
Advancements in knowledge distillation and multi-teacher learning, as demonstrated by the AM-RADIO framework, have opened up new possibilities for model compression and knowledge transfer. By leveraging the knowledge of multiple teacher models, the performance of student models can be significantly enhanced.
The AM-RADIO framework, with its multi-teacher distillation approach, trains a vision foundation model from scratch, showcasing superior performance across various vision tasks. Additionally, the introduction of the E-RADIO hybrid architecture addresses the challenge of distilling foundation models with CNN-like architectures, further improving efficiency and performance.
As the field of knowledge distillation continues to evolve, we can expect further advancements and innovative frameworks that push the boundaries of model compression and knowledge transfer. These advancements will enable the deployment of efficient and lightweight models without compromising on performance, paving the way for more accessible and scalable AI applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
If you like our work, you will love our Newsletter 📰