Balancing Efficiency and Recall in Language Models: Introducing BASED for High-Speed, High-Fidelity Text Generation
Artificial intelligence has revolutionized the way we interact with technology, particularly in the field of natural language processing. Language models have become increasingly sophisticated, capable of processing vast amounts of information and generating high-quality text. However, two crucial aspects that have always posed a challenge in language models are efficiency and recall capabilities. Striking a balance between these two factors is essential to ensure optimal performance and utility.
The Challenge: Efficiency vs. Recall
Efficiency in language models refers to their ability to process information quickly and accurately. With the ever-increasing amounts of data, it is crucial for models to perform efficiently without compromising on the quality of generated text. On the other hand, recall is the model’s ability to accurately remember and reproduce information from the input. While models with full attention mechanisms have high recall capabilities, they often suffer from memory consumption and computational inefficiency.
Bridging the Gap: Introducing BASED
To address the challenge of balancing efficiency and recall in language models, researchers from Stanford University, University at Buffalo, and Purdue University have introduced BASED (Balancing Efficiency and Recall in Language Models). BASED is an architecture that significantly differs from traditional approaches, offering a unique solution that bridges the gap between efficiency and recall.
Unlike previous models, BASED integrates linear attention with sliding window attention. This hybrid architecture allows for dynamic adjustment based on the task at hand. It can mimic the expansive recall capabilities of full attention models or operate within the confines of a reduced state size, similar to more memory-efficient alternatives. This adaptability showcases the versatility of BASED and its practical applicability across various language processing tasks.
The Brilliance of BASED
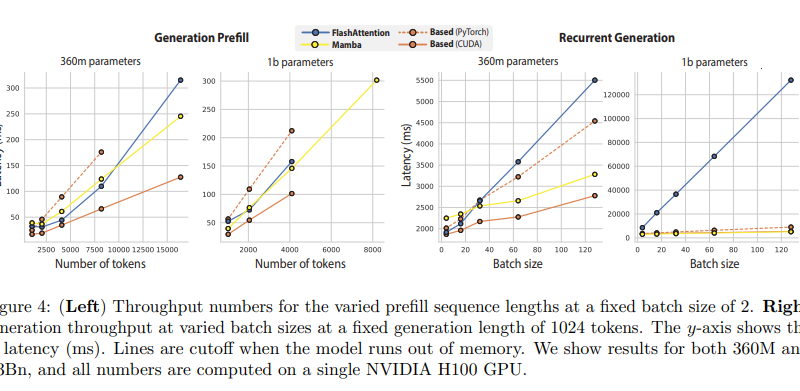
What sets BASED apart is not only its conceptual design but also its implementation. The architecture incorporates IO-aware algorithms, specifically developed to enhance throughput in language generation tasks. These algorithms play a pivotal role in achieving unparalleled efficiency, outperforming established models like FlashAttention-2 in terms of throughput. This leap in performance highlights the importance of algorithmic efficiency in the evolution of language models.
The empirical evaluation of BASED further solidifies its standing as a groundbreaking advancement in the field. BASED demonstrates its superiority over existing sub-quadratic models through rigorous tests, including perplexity measurements and recall-intensive tasks. It matches and occasionally surpasses the recall capabilities of these models, marking a significant milestone in the quest for highly efficient yet capable language processing tools.
Implications and Future Prospects
The development of BASED represents a broader shift in the landscape of natural language processing. It exemplifies the growing emphasis on creating models that are not only powerful but also resource-efficient. In an era where the environmental impact of computing is increasingly scrutinized, BASED sets a precedent for future research.
The introduction of BASED opens the door to a myriad of applications previously constrained by the limitations of existing models. By ingeniously balancing efficiency and recall, BASED addresses a fundamental challenge in natural language processing. Its impact will resonate beyond the confines of academic research, influencing the development of artificial intelligence technologies for years to come.
Conclusion
Efficiency and recall are critical aspects of language models that determine their utility and effectiveness. The introduction of BASED represents a pivotal moment in the evolution of language models, heralding a new era of balancing these two factors. BASED’s hybrid architecture and IO-aware algorithms offer a unique solution to bridge the gap between efficiency and recall, paving the way for more sophisticated and practical applications in artificial intelligence.
As technology continues to advance, striking a balance between efficiency and recall will remain a priority. BASED’s groundbreaking approach sets a precedent for future research and inspires further innovation in the field of natural language processing. With BASED, we are one step closer to achieving high-speed, high-fidelity text generation that meets the demands of modern language processing tasks.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰