Exploring TRLx: Hands-on Guide for Implementing Text Summarization through RLHF
Text summarization is a critical task in natural language processing that aims to condense the content of a given text into a shorter version while preserving its main ideas and key information. Traditional methods for text summarization often rely on rule-based or statistical approaches, which may not always capture the nuances and context of the original text.
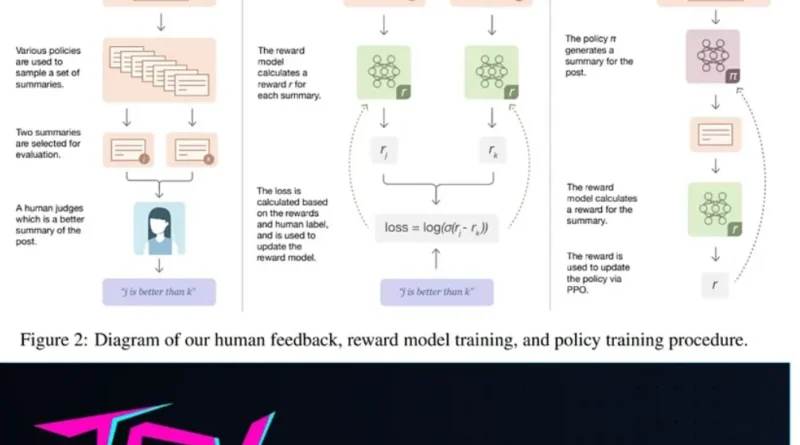
In recent years, there has been a growing interest in utilizing reinforcement learning techniques to improve the performance of text summarization models. One such approach is Reinforcement Learning from Human Feedback (RLHF), which combines the power of reinforcement learning with valuable human feedback to train text summarization models.
In this article, we will explore TRLx, a hands-on guide for implementing text summarization through RLHF. We will discuss the key steps involved in the implementation process and highlight the benefits of using TRLx for text summarization tasks.
Understanding RLHF and Its Benefits
Reinforcement Learning from Human Feedback (RLHF) is an approach that combines the strengths of reinforcement learning and human feedback to train machine learning models. RLHF has been successfully applied in various domains, including natural language processing tasks like text summarization.
The key idea behind RLHF is to leverage human-generated summaries as a source of reward signals for training text summarization models. By collecting feedback from human evaluators, the model can learn to generate high-quality summaries that align with human preferences.
One of the main benefits of RLHF is its ability to overcome the limitations of traditional fine-tuning approaches for text summarization. Fine-tuning on summarization data alone may lead to suboptimal performance, as it relies solely on the labeled data available. RLHF, on the other hand, allows the model to learn from human preferences and adapt accordingly, resulting in improved summarization performance.
Introducing TRLx and Its Features
TRLx is a powerful framework developed by CarperAI that enables the implementation of RLHF for text summarization tasks. TRLx is built on top of the Transformers library from Hugging Face, which provides state-of-the-art pre-trained models for natural language processing tasks.
One of the key features of TRLx is its support for Proximal Policy Optimization (PPO) and Implicit Language Q-Learning (ILQL) algorithms. These reinforcement learning algorithms help optimize the model’s performance by iteratively updating its policy based on the reward signals received from human evaluators.
TRLx also provides a streamlined and efficient fine-tuning experience by abstracting away the complexities of the training loop and optimization procedures. This allows researchers and developers to focus on the high-level reinforcement learning dynamics, without the need for boilerplate code in distributed training.
Hands-on Implementation Guide with TRLx
Let’s now dive into the hands-on implementation guide for text summarization using TRLx. We will walk through the key steps involved in the process, from fine-tuning a pre-trained transformer model to training a reward model and applying Proximal Policy Optimization (PPO) for further refinement.
Step 1: Fine-tuning a Pre-trained Transformer Model
To begin the process, we first need to fine-tune a pre-trained transformer model specifically for text summarization. TRLx simplifies this step by seamlessly incorporating custom datasets and abstracting away the intricacies of the training loop.
First, we import the required libraries and load the pre-trained transformer model and its tokenizer. In this example, we will use the T5-small model, a lightweight variant of the T5 transformer model designed for generative tasks like summarization.
import trlX
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("t5-small")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")
# Load your dataset
train_dataset, val_dataset = load_summarization_datasets()
# Fine-tune the model
trainer = trlX.Trainer(
model=model,
tokenizer=tokenizer,
train_dataset=train_dataset,
val_dataset=val_dataset,
train_batch_size=8,
gradient_accumulation_steps=2,
)
trainer.train()
In the above code snippet, we initialize the tokenizer and model using the T5-small variant. We also load our custom dataset for training and validation. Then, we create a Trainer instance from TRLx, providing it with the model, tokenizer, datasets, and training details such as batch size and gradient accumulation steps. Finally, we call the trainer.train() method to initiate the fine-tuning process.
Step 2: Training a Reward Model
The next step is to train a reward model, which helps us evaluate the quality of the generated summaries during the reinforcement learning phase. The reward model is trained using a comparison dataset that consists of pairs of summaries along with scores indicating their quality.
TRLx simplifies the training of the reward model by providing a RewardModel class and a RewardModelTrainer class. The RewardModel class encapsulates the fine-tuned transformer model, while the RewardModelTrainer class handles the training process.
from trlX.reward_model import RewardModel
from datasets import load_dataset
reward_model = RewardModel(model, tokenizer)
comparison_dataset = load_dataset("allenai/scitldr")
# Train the reward model
reward_trainer = trlX.RewardModelTrainer(
reward_model=reward_model,
train_dataset=comparison_dataset,
train_batch_size=8,
)
reward_trainer.train()
In the above code snippet, we create an instance of the RewardModel class, passing in the fine-tuned transformer model and its tokenizer. We also load a comparison dataset, in this case, the TL;DR summarization dataset from AllenAI.
Then, we instantiate a RewardModelTrainer and provide it with the reward model and the comparison dataset. We also specify the batch size for training. Finally, we call the reward_trainer.train() method to start the training process.
Step 3: Fine-tuning the Model using PPO
The final step in the implementation process is to further refine the transformer model using Proximal Policy Optimization (PPO). PPO is a popular reinforcement learning algorithm that helps optimize the model’s performance by leveraging the insights gained from the trained reward model.
ppo_trainer = trlX.PPOTrainer(
model=model,
tokenizer=tokenizer,
reward_model=reward_model,
train_dataset=train_dataset,
train_batch_size=8,
)
ppo_trainer.train()
In the above code snippet, we create an instance of the PPOTrainer class, providing it with the model, tokenizer, reward model, training dataset, and batch size. The PPOTrainer leverages the reward model during the fine-tuning process to guide the model’s learning through reinforcement. Finally, we call the ppo_trainer.train() method to initiate the PPO-based fine-tuning procedure.
Conclusion
In this article, we have explored TRLx, a hands-on guide for implementing text summarization through Reinforcement Learning from Human Feedback (RLHF). We have discussed the key steps involved in the implementation process, including fine-tuning a pre-trained transformer model, training a reward model, and applying Proximal Policy Optimization (PPO) for further refinement.
TRLx provides a streamlined and efficient framework for implementing RLHF in text summarization tasks, making it easier for researchers and developers to leverage reinforcement learning techniques. By combining the power of reinforcement learning with human feedback, TRLx enables the training of text summarization models that generate high-quality summaries aligned with human preferences.
Implementing RLHF for text summarization allows us to overcome the limitations of traditional fine-tuning approaches and improve the overall performance of the models. With TRLx, the process becomes more accessible and efficient, paving the way for advancements in the field of text summarization.
Don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰